大语言模型推理和部署开源库VLLM解读
Published:
vLLM是借助分页注意力机制实现轻松、快速且低成本的大语言模型服务。
blog地址:vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
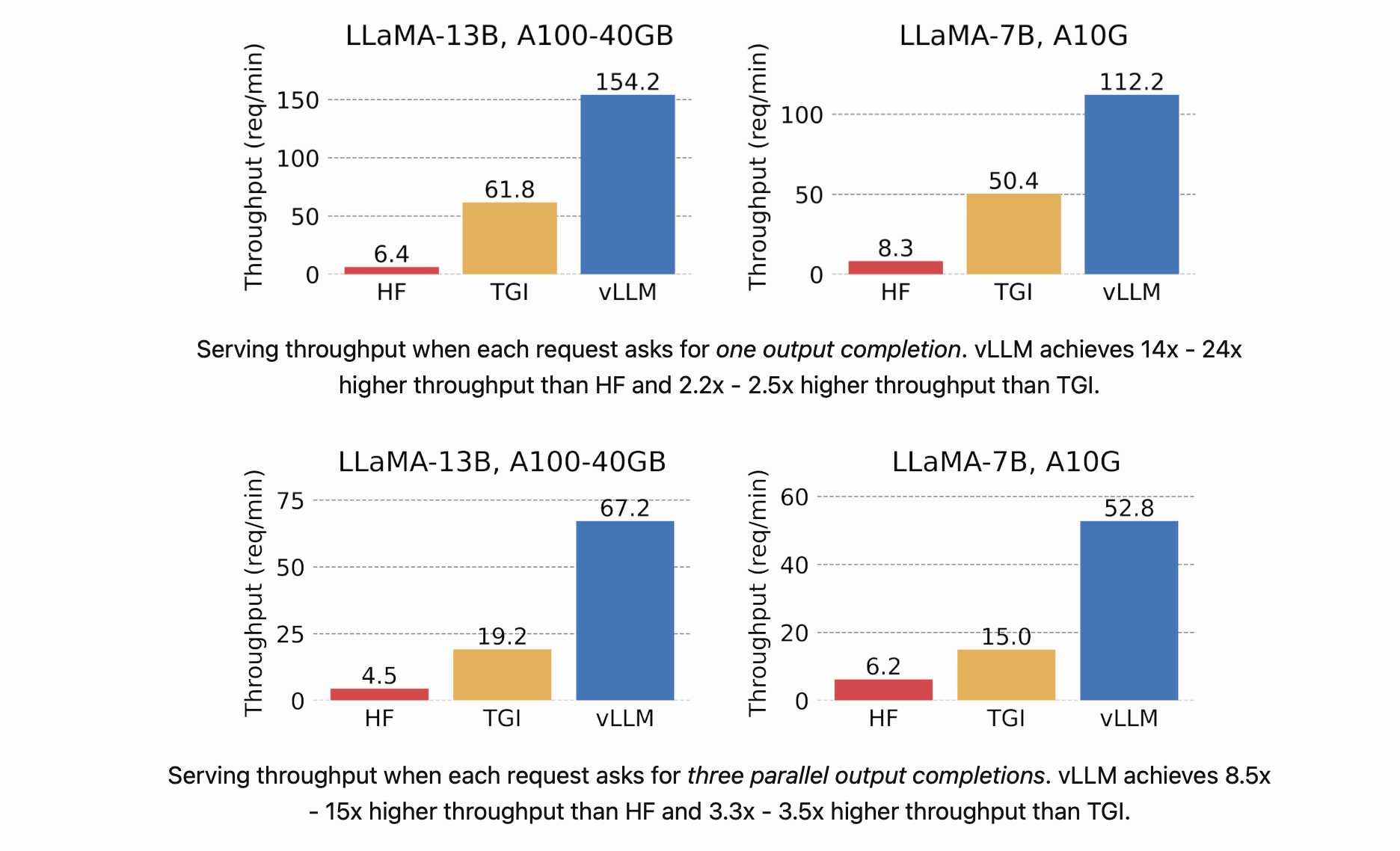
大语言模型(LLMs)有望从根本上改变我们在所有行业中使用人工智能的方式。然而,实际部署这些模型颇具挑战性,即便在昂贵的硬件上,其速度也可能慢得惊人。今天,我们很高兴推出vLLM,这是一个用于快速大语言模型推理和部署的开源库。vLLM采用了我们全新的注意力算法——分页注意力(PagedAttention),该算法能有效地管理注意力的键和值。配备了分页注意力的vLLM重新定义了大语言模型部署的新标杆:它的吞吐量比HuggingFace Transformers高出24倍之多,且无需对模型架构做任何改动。
vLLM由加州大学伯克利分校开发,在过去两个月里已部署到Chatbot Arena和Vicuna Demo中。即使对于像LMSYS这样计算资源有限的小型研究团队而言,它也是实现经济高效的大语言模型部署的核心技术。现在只需在我们的GitHub代码库中输入一条指令,即可试用vLLM。
超越最先进的性能
我们将vLLM的吞吐量与最受欢迎的大语言模型库HuggingFace Transformers(HF)以及此前的最先进技术HuggingFace文本生成推理(TGI)进行了对比。我们在两种配置下进行评估:在英伟达A10G GPU上运行LLaMA - 7B模型,以及在英伟达A100 GPU(40GB)上运行LLaMA - 13B模型。我们从ShareGPT数据集中抽取请求的输入/输出长度样本。在我们的实验中,与HF相比,vLLM的吞吐量最高提升达24倍,与TGI相比,最高提升达3.5倍。
秘诀所在:分页注意力(PagedAttention)
在vLLM中,我们发现大语言模型服务的性能瓶颈在于内存。在自回归解码过程中,大语言模型的所有输入令牌都会生成其注意力键和值张量,并且这些张量会保留在GPU内存中,以便生成后续令牌。这些缓存的键和值张量通常被称为键值缓存(KV cache)。键值缓存具有以下特点:
- 占用空间大:在LLaMA - 13B模型中,单个序列的键值缓存占用空间可达1.7GB。
- 动态变化:其大小取决于序列长度,而序列长度变化极大且难以预测。因此,有效地管理键值缓存是一项重大挑战。我们发现,现有系统因内存碎片化和过度预留,会浪费60% - 80%的内存。
为解决这一问题,我们引入了分页注意力(PagedAttention)算法,该算法的灵感源自操作系统中虚拟内存和分页的经典概念。与传统注意力算法不同,分页注意力允许将连续的键和值存储在不连续的内存空间中。具体而言,分页注意力将每个序列的键值缓存划分为多个块,每个块包含固定数量令牌的键和值。在注意力计算过程中,分页注意力内核能够高效识别并获取这些块。

由于这些块在内存中无需连续,我们就能像在操作系统的虚拟内存中那样,以更灵活的方式管理键和值:可以将块看作页面,令牌看作字节,序列看作进程。通过块表,一个序列中连续的逻辑块被映射到不连续的物理块。随着新令牌的生成,物理块会按需分配。 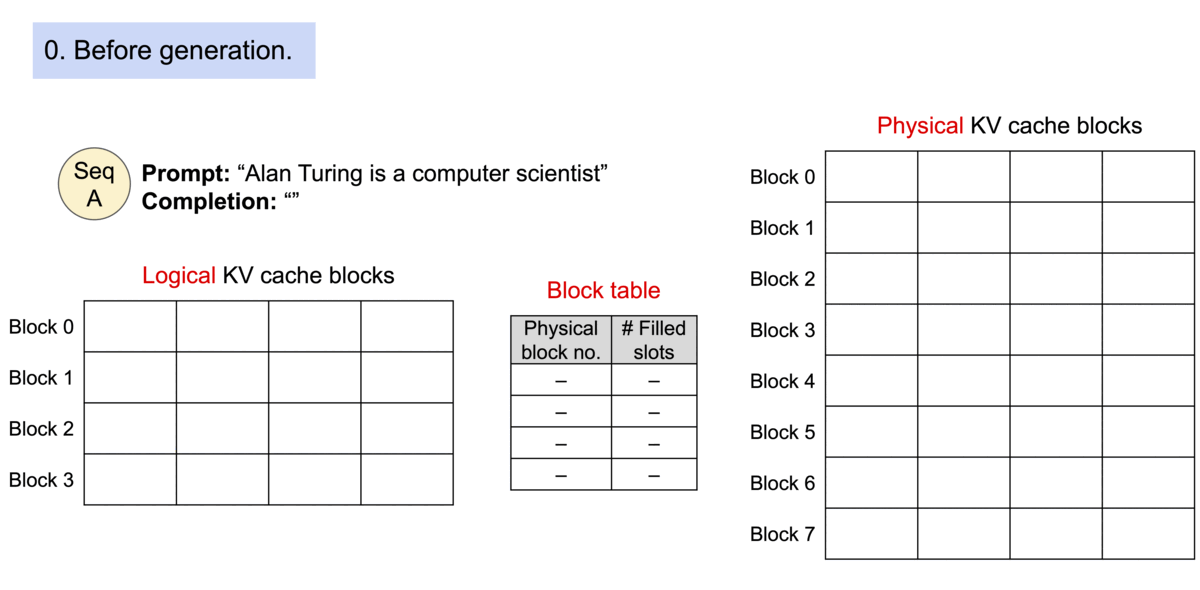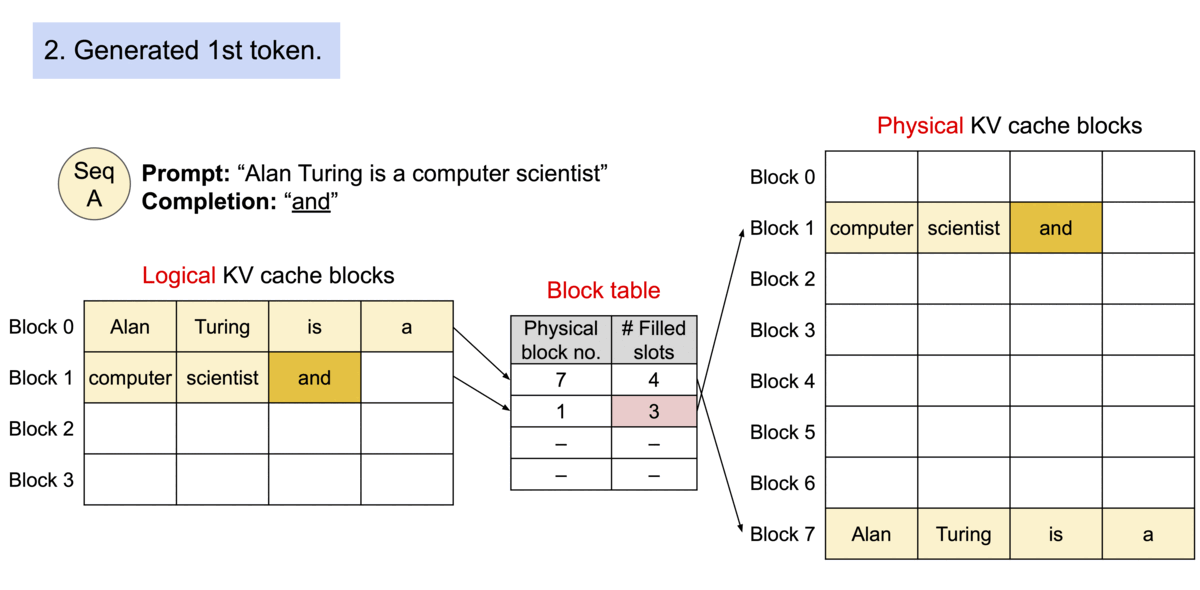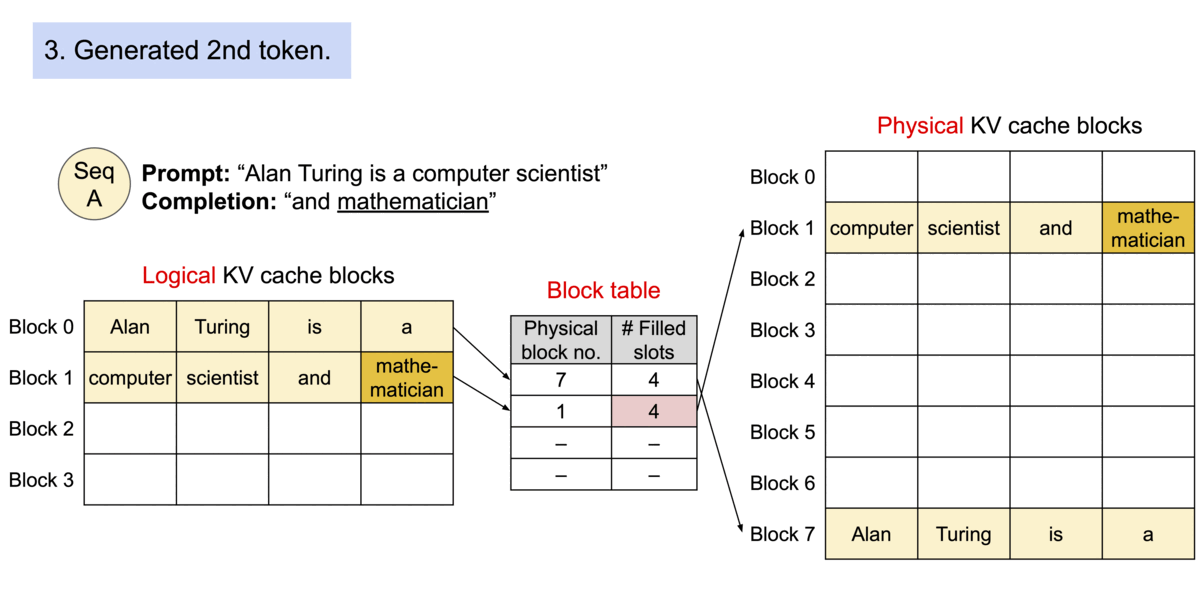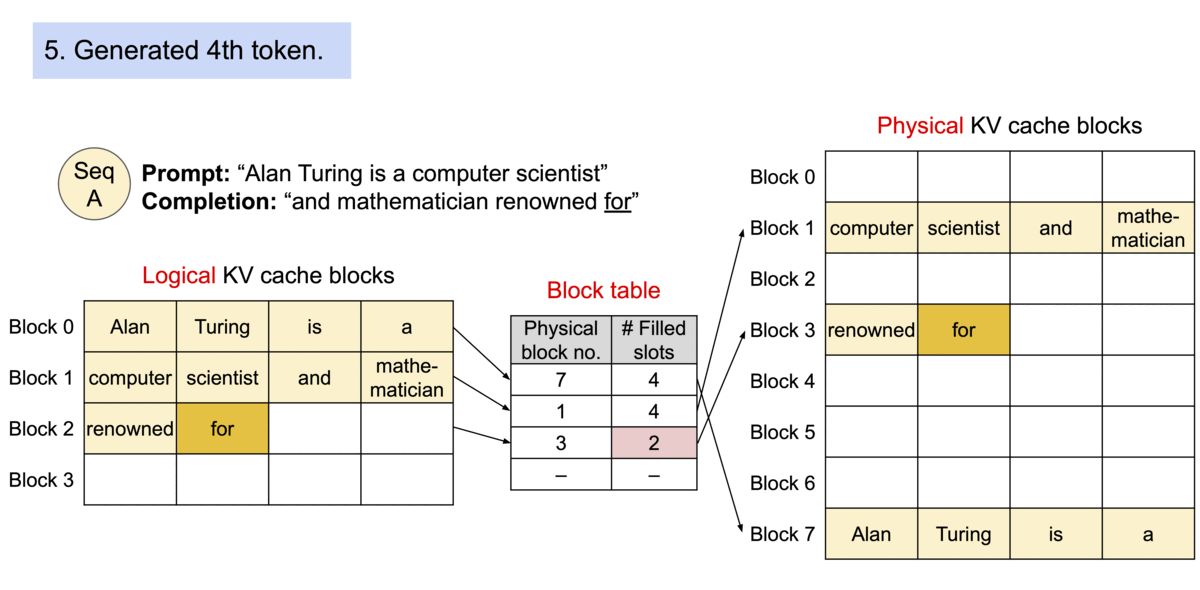
在分页注意力机制中,内存浪费仅发生在序列的最后一个块中。在实际应用中,这使得内存使用率近乎最优,浪费率仅不到4%。内存效率的提升带来了极大的好处:它使系统能够将更多序列进行批量处理,提高GPU利用率,从而如上述性能结果所示,显著提高吞吐量。
分页注意力机制还有另一个关键优势:高效的内存共享。例如,在并行采样中,相同的提示会生成多个输出序列。在这种情况下,提示的计算和内存可以在输出序列之间共享。
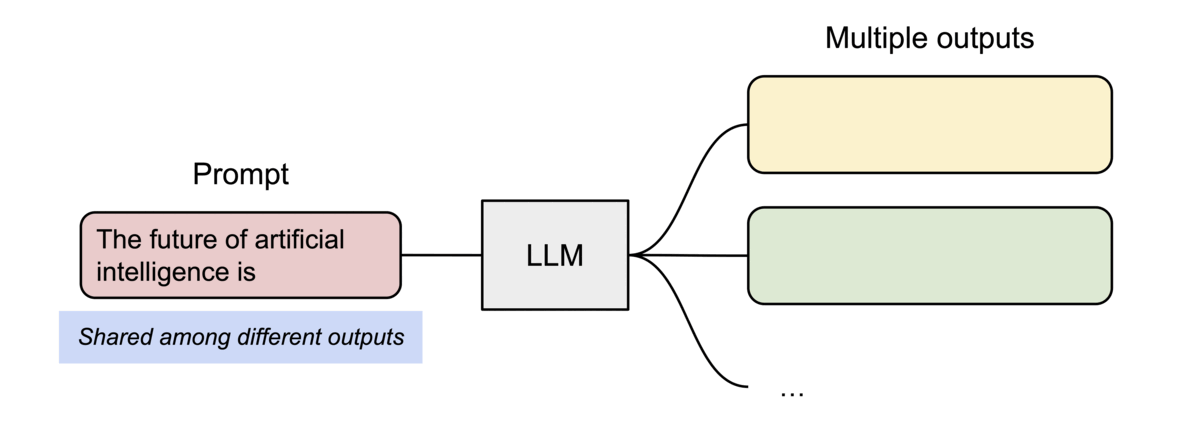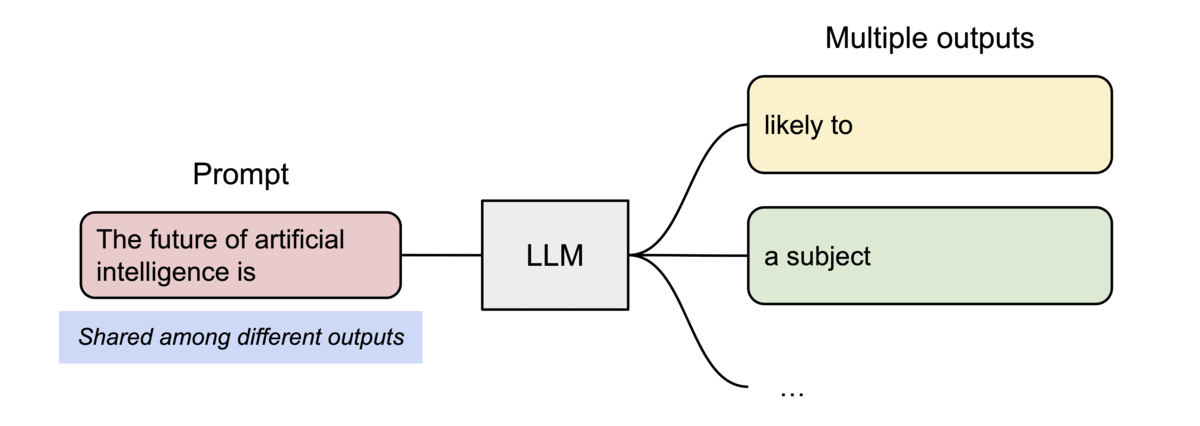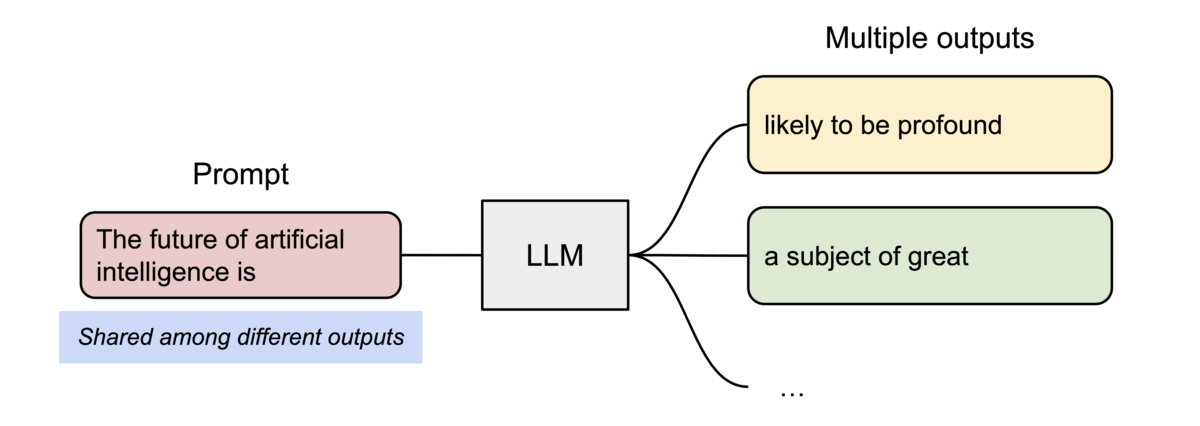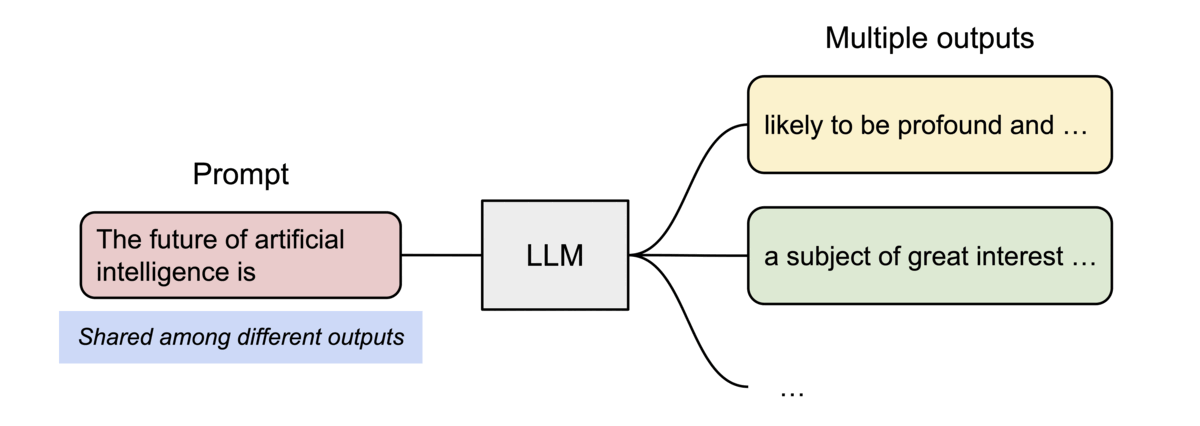
分页注意力(PagedAttention)通过其块表自然地实现了内存共享。就如同进程共享物理页面一样,在分页注意力中,不同序列可以通过将其逻辑块映射到相同的物理块来共享这些块。为确保安全共享,分页注意力会跟踪物理块的引用计数,并实现写时复制机制。
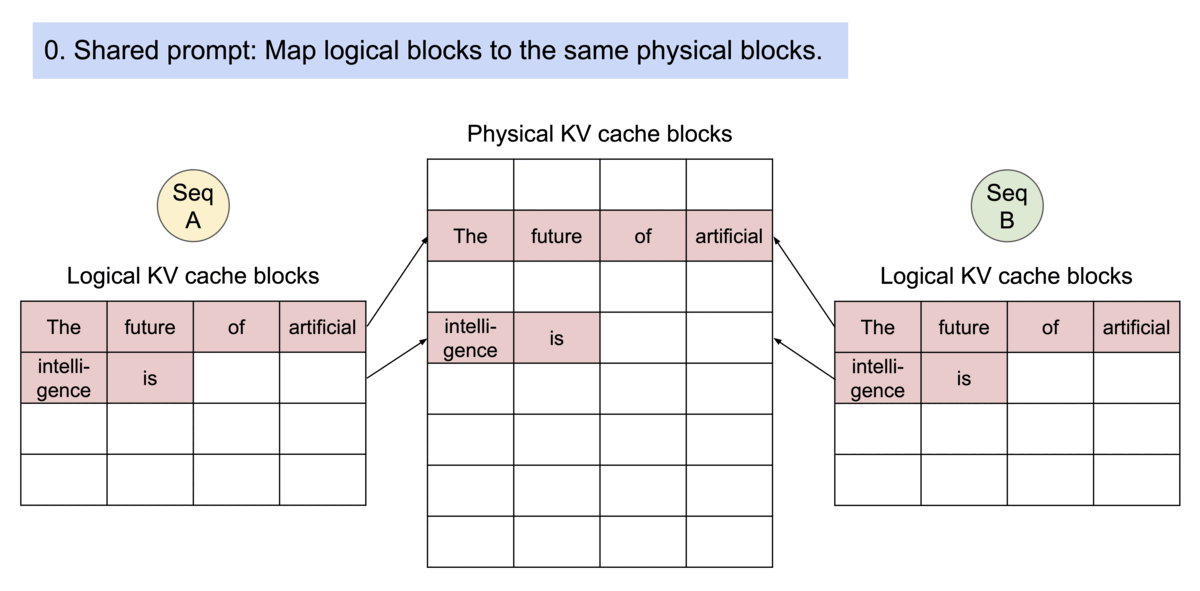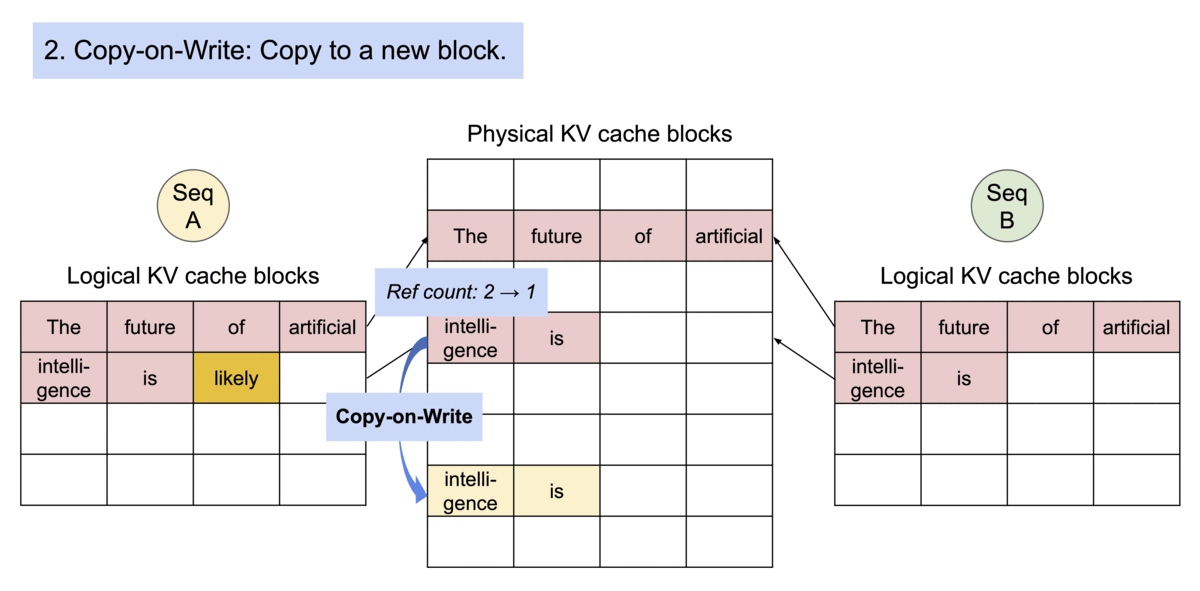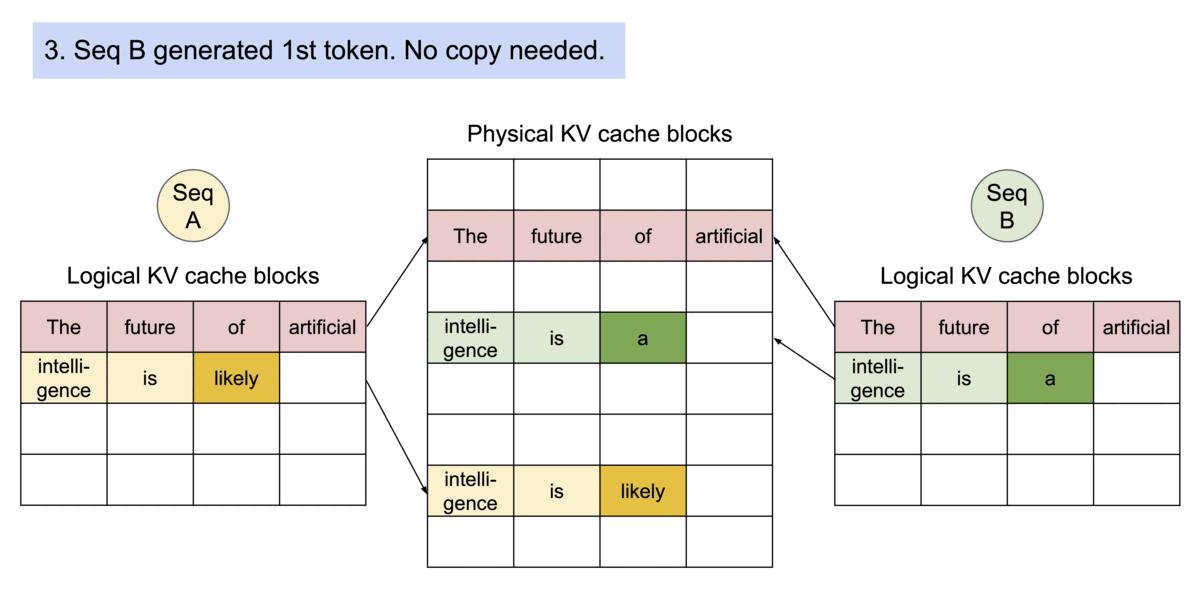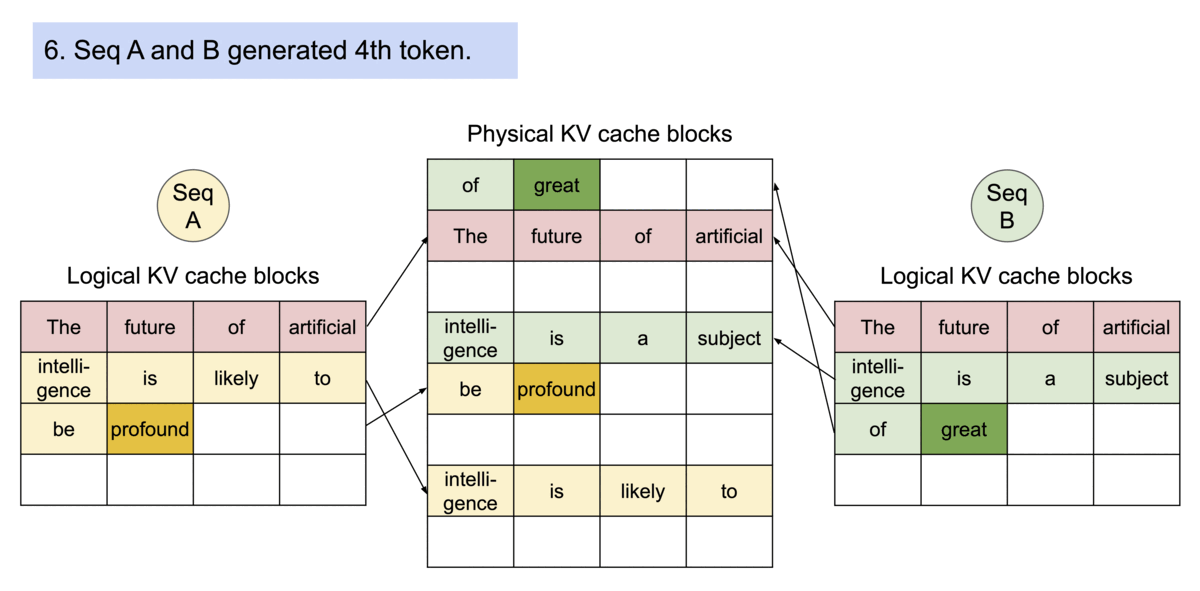 针对采样多个输出的请求的示例生成过程。
针对采样多个输出的请求的示例生成过程。
分页注意力(PagedAttention)的内存共享功能极大地降低了复杂采样算法(如并行采样和束搜索)的内存开销,将它们的内存使用量最多削减55%。这能使吞吐量提升高达2.2倍。这使得此类采样方法在大语言模型服务中切实可行。
分页注意力(PagedAttention)是vLLM背后的核心技术,vLLM是我们的大语言模型推理与服务引擎,它以高性能和易用的接口支持多种模型。如需了解vLLM和分页注意力(PagedAttention)更多技术细节,可查看我们的GitHub代码库,并敬请关注我们的论文。
LMSYS小羊驼(Vicuna)和聊天机器人竞技场背后的无名英雄
今年4月,LMSYS开发了广受欢迎的小羊驼(Vicuna)聊天机器人模型并将其公开。从那时起,小羊驼(Vicuna)在聊天机器人竞技场中为数百万用户提供服务。最初,LMSYS的FastChat采用基于Hugging Face Transformers的服务后端来支持聊天演示。随着该演示越来越受欢迎,高峰流量增长了数倍,使得Hugging Face后端成为一个重大瓶颈。LMSYS和vLLM团队携手合作,很快开发出FastChat - vLLM集成方案,将vLLM用作新的后端,以满足不断增长的需求(流量增长高达5倍)。在LMSYS早期的内部微基准测试中,vLLM服务后端的吞吐量比最初的Hugging Face后端高出30倍。
自4月中旬以来,诸如小羊驼(Vicuna)、考拉(Koala)和LLaMA等最受欢迎的模型,都已通过FastChat - vLLM集成成功提供服务。借助FastChat作为多模型聊天服务前端,vLLM作为推理后端,LMSYS能够利用有限数量的由高校赞助的GPU,以高吞吐量和低延迟为数百万用户提供小羊驼(Vicuna)服务。LMSYS正在将vLLM的应用扩展到更广泛的模型,包括Databricks的Dolly、LAION的OpenAssistant以及Stability AI的StableLM。对更多模型的支持正在开发中,即将推出。
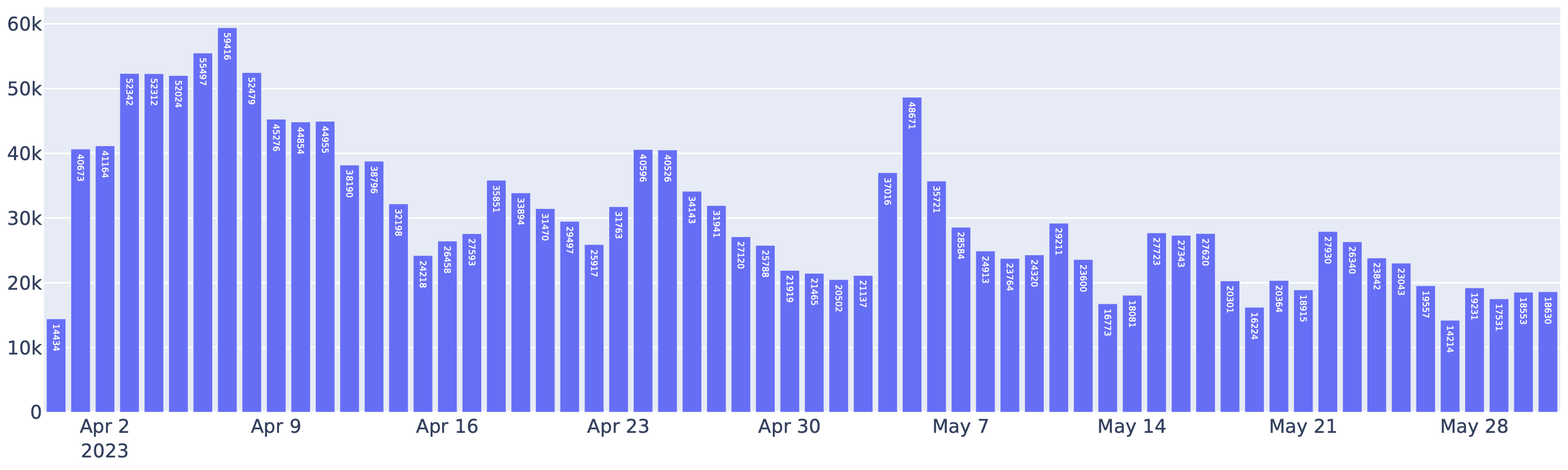 4月至5月期间,聊天机器人竞技场中由FastChat - vLLM集成提供服务的请求情况。实际上,发送至聊天机器人竞技场的请求中,超过一半都将vLLM用作推理后端。
4月至5月期间,聊天机器人竞技场中由FastChat - vLLM集成提供服务的请求情况。实际上,发送至聊天机器人竞技场的请求中,超过一半都将vLLM用作推理后端。
vLLM的使用还显著降低了运营成本。借助vLLM,LMSYS能够将处理上述流量所使用的GPU数量削减50%。vLLM平均每天处理3万个请求,峰值可达6万个,这充分展示了vLLM的稳定性。
开始使用vLLM
使用以下命令安装vLLM(更多内容请查看我们的安装指南):
pip install vllm
vLLM 可用于离线推理和在线服务。要在离线推理中使用 vLLM,可以在 Python 脚本中导入 vLLM 并使用 LLM 类:
from vllm import LLM
prompts = ["Hello, my name is", "The capital of France is"] # 示例提示词。
llm = LLM(model="lmsys/vicuna-7b-v1.3") # 创建一个LLM。
outputs = llm.generate(prompts) # 根据提示词生成文本。
要使用 vLLM 进行在线服务,可以通过以下方式启动一个与 OpenAI API 兼容的服务器:
python -m vllm.entrypoints.openai.api_server --model lmsys/vicuna-7b-v1.3
你可以使用与 OpenAI API 相同的格式查询服务器:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "lmsys/vicuna-7b-v1.3",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
如需了解更多使用 vLLM 的方法,请查看快速入门指南。