jetson orin nano super AI模型部署之路(一)deepseek r1模型部署
Published:
先看一下部署完成后的效果。可以直接在手机上访问jetson,有web界面供使用。 
也可以直接在电脑上访问。 
我这个是8GB 128-bit LPDDR5 102GB/s版本,256g硬盘。先看一下基本参数。
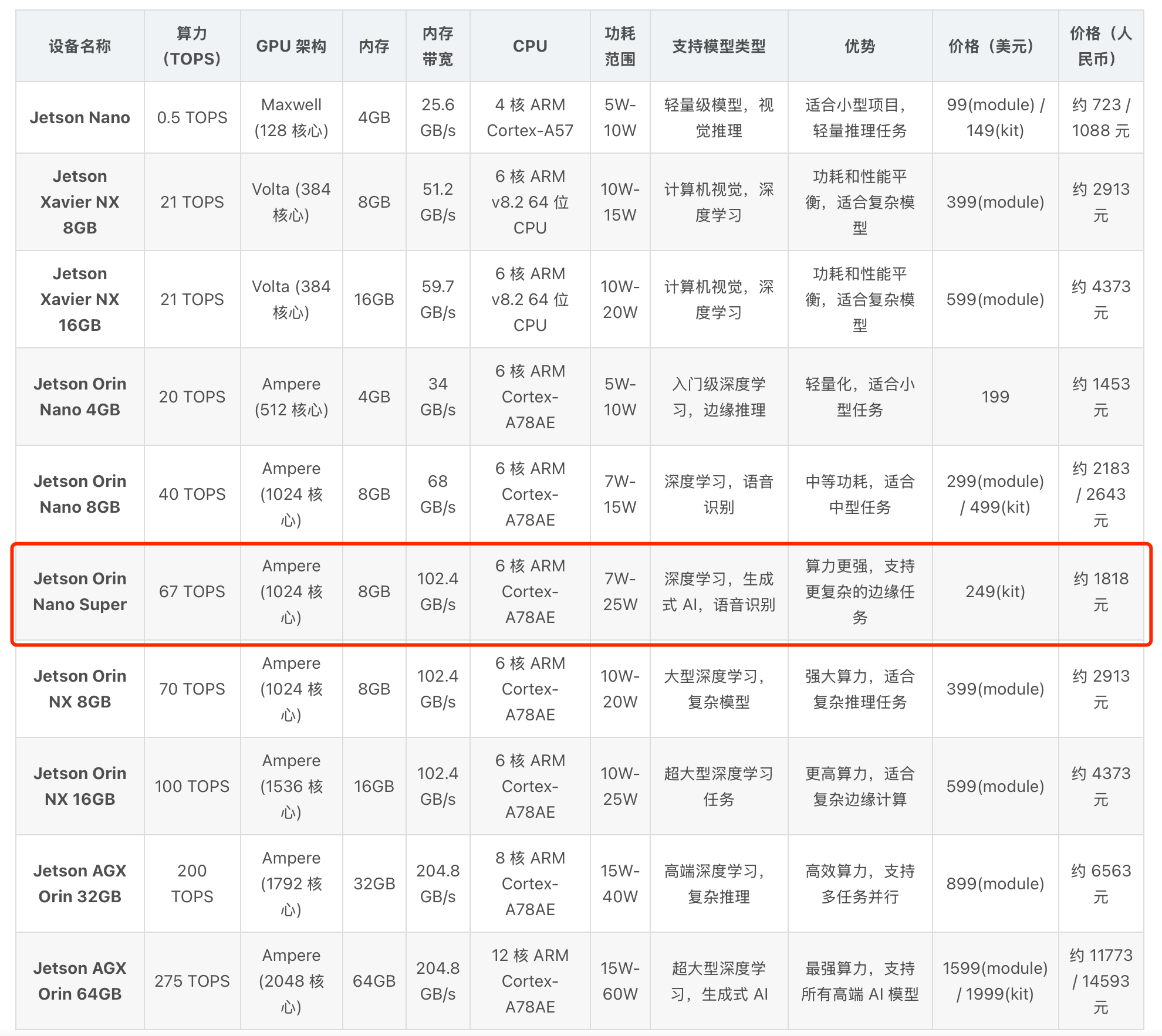
从算力和价格的比较看,jetson orin nano super 8g版本的性价比还是很高的,在较低的价格上,仍然有67TOPS(INT8)的算力。而且使用的是较新的ampere架构。CPU使用6核 ARM Cortex- A78AE,频率可达1.7GHz。 在这个算力基础上, 可以运行更强的AI模型,适合更复杂的边缘计算任务。
部署deepseek使用的工具之一是ollama
Ollama 是一个开源的本地大型语言模型(LLM)运行框架,旨在简化在本地机器上部署、管理和运行各种开源大语言模型的过程。它通过提供简单的命令行工具和 API,使用户能够轻松下载、配置和运行模型,而无需依赖复杂的云服务或高性能硬件。ollama现在支持llama3、deepseek r1、phi-4、gemma2以及其他很多模型的一键部署和运行。
- 安装
curl -fsSL https://ollama.com/install.sh | sh
- 运行模型 安装完成后,直接访问官网ollama models链接,选取自己要用的模型即可。我们这里选用deepseek-r1 7b的模型。7b的模型占用显存就要7G多。
然后直接在terminal运行
ollama run deepseek-r1
即可。
现在只能在terminal中使用deepseek,不方便看,而且生成的代码不容易复制,因此有一个类似chatgpt或者deepseek官网的web界面会更容易使用。下面来配置类似deepseek网页端的web界面,但是模型推理是在我们本地的jetson设备上。
- 环境配置
在terminal使用ollama的话,上面的操作就可以完成。如果想通过其他工具或者代码调用ollama的模型,在Linux环境下,需要进行一些环境配置。主要是把11434端口暴露出来,ollama是通过这个端口接收输入的。
sudo vi /etc/systemd/system/ollama.service
在[Service]标签下添加Environment=”OLLAMA_HOST=0.0.0.0:11434”
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
然后重启ollama
sudo systemctl daemon-reload
sudo systemctl restart ollama.service
如果想立即停掉ollama释放显存,也可以手动启动或者关闭ollama。
sudo systemctl start ollama.service
sudo systemctl stop ollama.service
- 测试ollama服务是否在后台正常运行
其他服务调用ollama,是通过11434端口。在terminal执行
curl http://localhost:11434
如果返回Ollama is running,代表ollama服务正在正常运行,其他服务可调用到ollama的模型。
配置open-webui,使用web界面
- 配置conda环境
现在jetson可以直接使用miniconda或者anaconda。我们这里以安装miniconda为例。
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm ~/miniconda3/miniconda.sh
启动conda
source ~/miniconda3/bin/activate
更推荐将~/miniconda3/bin/activate中的内容添加到~/.bashrc文件中,自动来激活conda。
然后我们来创建一个conda环境,注意open-webui要求python版本大于等于3.11。
conda create -n openwebui python=3.11
创建完成后激活conda环境。
- 安装open webui
pip install open-webui
- 启动open-webui
只要前面ollama的端口设置好了,就可以直接启动open-webui,它会自动通过访问ollama的服务,来检测已经安装的ollama模型。想安装新的模型,只要访问ollama models,执行ollama run xxx就可以自动安装了。
open-webui serve
- 通过web访问ollama open-webui运行后,可以通过8080端口访问open-webui。我们在另外的与jetson在同一局域网的设备,访问
http://jetson-ip:8080即可访问部署在jetson上的LLM模型了,并且有美观的web界面供使用。
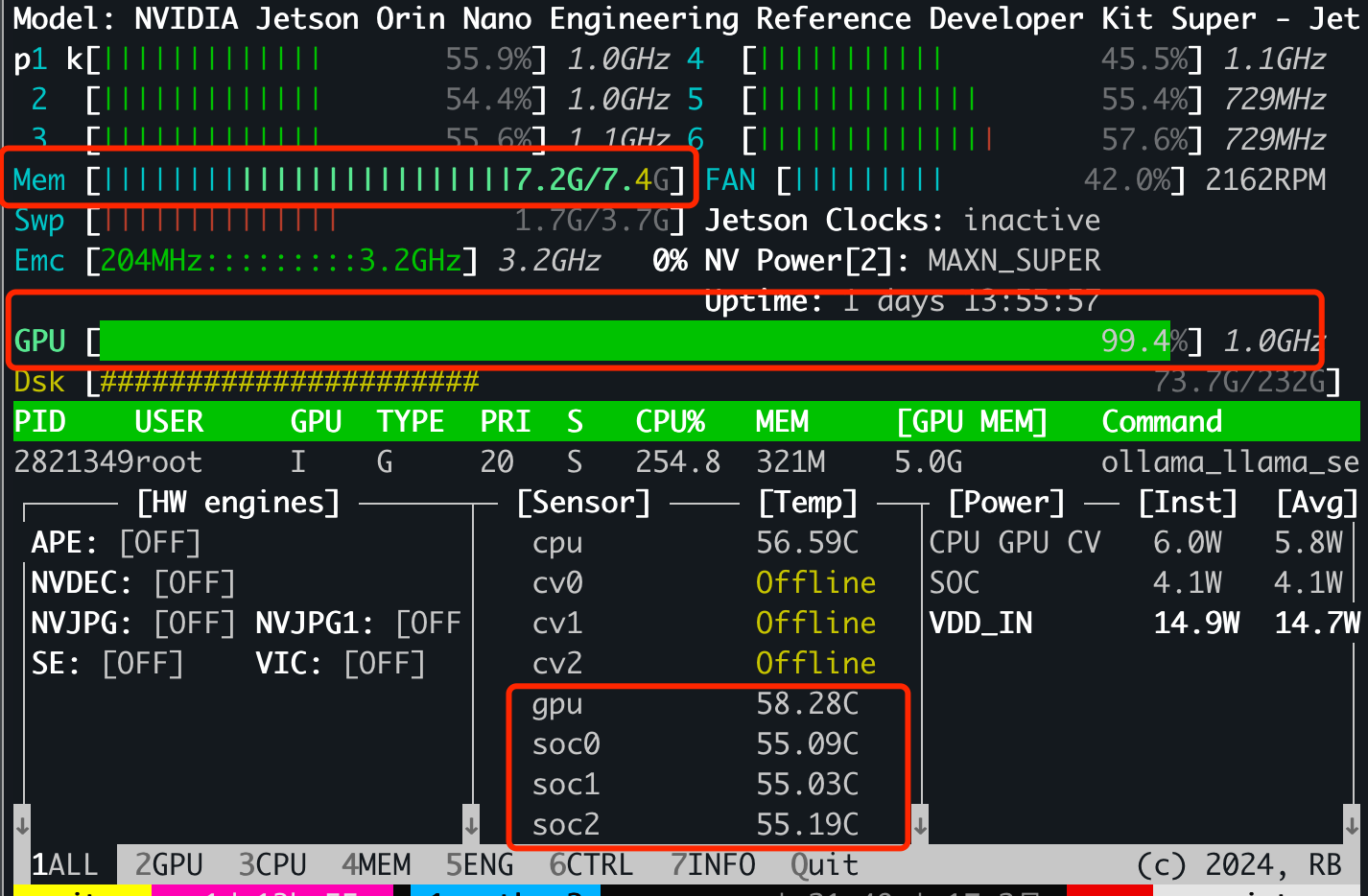
在推理过程中,系统8G显存基本全部被占满,GPU全频,jetson温度也会升到60度左右。