Restormer模型代码解析
Published:
上一篇我们对Restormer的论文进行了解析。这篇对Restormer的代码进行解析。
论文地址:Restormer: Efficient Transformer for High-Resolution Image Restoration。代码地址:Restormer
以Deraining项目中的test.py文件为切入点,来分析其model。
test.py进行了修改,适配Mac的mps backend。
## Restormer: Efficient Transformer for High-Resolution Image Restoration
## Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang
## https://arxiv.org/abs/2111.09881
import numpy as np
import os
import argparse
from tqdm import tqdm
import sys
import torch.nn as nn
import torch
import torch.nn.functional as F
import utils
from natsort import natsorted
from glob import glob
from restormer_arch import Restormer
from skimage import img_as_ubyte
from pdb import set_trace as stx
parser = argparse.ArgumentParser(description='Image Deraining using Restormer')
parser.add_argument('--input_dir', default='./Datasets/', type=str, help='Directory of validation images')
parser.add_argument('--result_dir', default='./results/', type=str, help='Directory for results')
parser.add_argument('--weights', default='./pretrained_models/deraining.pth', type=str, help='Path to weights')
args = parser.parse_args()
####### Load yaml #######
yaml_file = 'Options/Deraining_Restormer.yml'
import yaml
try:
from yaml import CLoader as Loader
except ImportError:
from yaml import Loader
x = yaml.load(open(yaml_file, mode='r'), Loader=Loader)
s = x['network_g'].pop('type')
##########################
# Detect available device (CUDA, MPS, or CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
print(f"{x['network_g'] = }")
model_restoration = Restormer(**x['network_g'])
print(f'{model_restoration = }')
sys.exit()
checkpoint = torch.load(args.weights, map_location='cpu')
model_restoration.load_state_dict(checkpoint['params'])
print("===>Testing using weights: ", args.weights)
model_restoration.to(device)
if device.type == 'cuda' and torch.cuda.device_count() > 1:
model_restoration = nn.DataParallel(model_restoration)
model_restoration.eval()
factor = 8
# datasets = ['Rain100L', 'Rain100H', 'Test100', 'Test1200', 'Test2800']
datasets = ['my']
for dataset in datasets:
print(f'{dataset = }')
result_dir = os.path.join(args.result_dir, dataset)
os.makedirs(result_dir, exist_ok=True)
inp_dir = os.path.join(args.input_dir, 'test', dataset, 'input')
files = natsorted(glob(os.path.join(inp_dir, '*.png')) + glob(os.path.join(inp_dir, '*.jpg')))
with torch.no_grad():
for file_ in tqdm(files):
if device.type == 'cuda':
torch.cuda.ipc_collect()
torch.cuda.empty_cache()
img = np.float32(utils.load_img(file_)) / 255.0
img = torch.from_numpy(img).permute(2, 0, 1)
input_ = img.unsqueeze(0).to(device)
# Padding in case images are not multiples of 8
h, w = input_.shape[2], input_.shape[3]
H, W = ((h + factor) // factor) * factor, ((w + factor) // factor) * factor
padh = H - h if h % factor != 0 else 0
padw = W - w if w % factor != 0 else 0
input_ = F.pad(input_, (0, padw, 0, padh), 'reflect')
restored = model_restoration(input_)
# Unpad images to original dimensions
restored = restored[:, :, :h, :w]
restored = torch.clamp(restored, 0, 1).cpu().detach().permute(0, 2, 3, 1).squeeze(0).numpy()
#utils.save_img(os.path.join(result_dir, os.path.splitext(os.path.split(file_)[-1])[0] + '.png'), img_as_ubyte(restored))
utils.save_img((os.path.join(result_dir, os.path.splitext(os.path.split(file_)[-1])[0]+'.png')), img_as_ubyte(restored))
我们运行,首先看一下传入Restormer类进行实例化的参数。
x['network_g'] = {'inp_channels': 3, 'out_channels': 3, 'dim': 48, 'num_blocks': [4, 6, 6, 8], 'num_refinement_blocks': 4, 'heads': [1, 2, 4, 8], 'ffn_expansion_factor': 2.66, 'bias': False, 'LayerNorm_type': 'WithBias', 'dual_pixel_task': False}
打印一下model看。
model_restoration = Restormer(
(patch_embed): OverlapPatchEmbed(
(proj): Conv2d(3, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(encoder_level1): Sequential(
(0): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(48, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(project_out): Conv2d(48, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(48, 254, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(254, 254, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=254, bias=False)
(project_out): Conv2d(127, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(1): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(48, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(project_out): Conv2d(48, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(48, 254, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(254, 254, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=254, bias=False)
(project_out): Conv2d(127, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(2): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(48, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(project_out): Conv2d(48, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(48, 254, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(254, 254, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=254, bias=False)
(project_out): Conv2d(127, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(3): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(48, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(project_out): Conv2d(48, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(48, 254, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(254, 254, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=254, bias=False)
(project_out): Conv2d(127, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(down1_2): Downsample(
(body): Sequential(
(0): Conv2d(48, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): PixelUnshuffle(downscale_factor=2)
)
)
(encoder_level2): Sequential(
(0): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(1): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(2): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(3): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(4): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(5): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(down2_3): Downsample(
(body): Sequential(
(0): Conv2d(96, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): PixelUnshuffle(downscale_factor=2)
)
)
(encoder_level3): Sequential(
(0): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(1): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(2): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(3): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(4): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(5): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(down3_4): Downsample(
(body): Sequential(
(0): Conv2d(192, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): PixelUnshuffle(downscale_factor=2)
)
)
(latent): Sequential(
(0): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(384, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(project_out): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(384, 2042, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(2042, 2042, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2042, bias=False)
(project_out): Conv2d(1021, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(1): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(384, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(project_out): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(384, 2042, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(2042, 2042, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2042, bias=False)
(project_out): Conv2d(1021, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(2): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(384, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(project_out): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(384, 2042, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(2042, 2042, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2042, bias=False)
(project_out): Conv2d(1021, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(3): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(384, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(project_out): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(384, 2042, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(2042, 2042, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2042, bias=False)
(project_out): Conv2d(1021, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(4): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(384, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(project_out): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(384, 2042, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(2042, 2042, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2042, bias=False)
(project_out): Conv2d(1021, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(5): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(384, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(project_out): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(384, 2042, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(2042, 2042, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2042, bias=False)
(project_out): Conv2d(1021, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(6): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(384, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(project_out): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(384, 2042, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(2042, 2042, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2042, bias=False)
(project_out): Conv2d(1021, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(7): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(384, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(project_out): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(384, 2042, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(2042, 2042, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2042, bias=False)
(project_out): Conv2d(1021, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(up4_3): Upsample(
(body): Sequential(
(0): Conv2d(384, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): PixelShuffle(upscale_factor=2)
)
)
(reduce_chan_level3): Conv2d(384, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(decoder_level3): Sequential(
(0): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(1): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(2): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(3): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(4): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(5): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)
(project_out): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(192, 1020, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(1020, 1020, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1020, bias=False)
(project_out): Conv2d(510, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(up3_2): Upsample(
(body): Sequential(
(0): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): PixelShuffle(upscale_factor=2)
)
)
(reduce_chan_level2): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(decoder_level2): Sequential(
(0): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(1): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(2): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(3): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(4): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(5): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(up2_1): Upsample(
(body): Sequential(
(0): Conv2d(96, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): PixelShuffle(upscale_factor=2)
)
)
(decoder_level1): Sequential(
(0): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(1): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(2): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(3): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(refinement): Sequential(
(0): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(1): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(2): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
(3): TransformerBlock(
(norm1): LayerNorm(
(body): WithBias_LayerNorm()
)
(attn): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(qkv_dwconv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=288, bias=False)
(project_out): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(norm2): LayerNorm(
(body): WithBias_LayerNorm()
)
(ffn): FeedForward(
(project_in): Conv2d(96, 510, kernel_size=(1, 1), stride=(1, 1), bias=False)
(dwconv): Conv2d(510, 510, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=510, bias=False)
(project_out): Conv2d(255, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)
(output): Conv2d(96, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
基本结构还是一个encocder-decoder的架构。
Restormer 类的实现为:
##---------- Restormer -----------------------
class Restormer(nn.Module):
def __init__(self,
inp_channels=3,
out_channels=3,
dim = 48,
num_blocks = [4,6,6,8],
num_refinement_blocks = 4,
heads = [1,2,4,8],
ffn_expansion_factor = 2.66,
bias = False,
LayerNorm_type = 'WithBias', ## Other option 'BiasFree'
dual_pixel_task = False ## True for dual-pixel defocus deblurring only. Also set inp_channels=6
):
super(Restormer, self).__init__()
self.patch_embed = OverlapPatchEmbed(inp_channels, dim)
self.encoder_level1 = nn.Sequential(*[TransformerBlock(dim=dim, num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])
self.down1_2 = Downsample(dim) ## From Level 1 to Level 2
self.encoder_level2 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])
self.down2_3 = Downsample(int(dim*2**1)) ## From Level 2 to Level 3
self.encoder_level3 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**2), num_heads=heads[2], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[2])])
self.down3_4 = Downsample(int(dim*2**2)) ## From Level 3 to Level 4
self.latent = nn.Sequential(*[TransformerBlock(dim=int(dim*2**3), num_heads=heads[3], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[3])])
self.up4_3 = Upsample(int(dim*2**3)) ## From Level 4 to Level 3
self.reduce_chan_level3 = nn.Conv2d(int(dim*2**3), int(dim*2**2), kernel_size=1, bias=bias)
self.decoder_level3 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**2), num_heads=heads[2], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[2])])
self.up3_2 = Upsample(int(dim*2**2)) ## From Level 3 to Level 2
self.reduce_chan_level2 = nn.Conv2d(int(dim*2**2), int(dim*2**1), kernel_size=1, bias=bias)
self.decoder_level2 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])
self.up2_1 = Upsample(int(dim*2**1)) ## From Level 2 to Level 1 (NO 1x1 conv to reduce channels)
self.decoder_level1 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])
self.refinement = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_refinement_blocks)])
#### For Dual-Pixel Defocus Deblurring Task ####
self.dual_pixel_task = dual_pixel_task
if self.dual_pixel_task:
self.skip_conv = nn.Conv2d(dim, int(dim*2**1), kernel_size=1, bias=bias)
###########################
self.output = nn.Conv2d(int(dim*2**1), out_channels, kernel_size=3, stride=1, padding=1, bias=bias)
def forward(self, inp_img):
inp_enc_level1 = self.patch_embed(inp_img)
out_enc_level1 = self.encoder_level1(inp_enc_level1)
inp_enc_level2 = self.down1_2(out_enc_level1)
out_enc_level2 = self.encoder_level2(inp_enc_level2)
inp_enc_level3 = self.down2_3(out_enc_level2)
out_enc_level3 = self.encoder_level3(inp_enc_level3)
inp_enc_level4 = self.down3_4(out_enc_level3)
latent = self.latent(inp_enc_level4)
inp_dec_level3 = self.up4_3(latent)
inp_dec_level3 = torch.cat([inp_dec_level3, out_enc_level3], 1)
inp_dec_level3 = self.reduce_chan_level3(inp_dec_level3)
out_dec_level3 = self.decoder_level3(inp_dec_level3)
inp_dec_level2 = self.up3_2(out_dec_level3)
inp_dec_level2 = torch.cat([inp_dec_level2, out_enc_level2], 1)
inp_dec_level2 = self.reduce_chan_level2(inp_dec_level2)
out_dec_level2 = self.decoder_level2(inp_dec_level2)
inp_dec_level1 = self.up2_1(out_dec_level2)
inp_dec_level1 = torch.cat([inp_dec_level1, out_enc_level1], 1)
out_dec_level1 = self.decoder_level1(inp_dec_level1)
out_dec_level1 = self.refinement(out_dec_level1)
#### For Dual-Pixel Defocus Deblurring Task ####
if self.dual_pixel_task:
out_dec_level1 = out_dec_level1 + self.skip_conv(inp_enc_level1)
out_dec_level1 = self.output(out_dec_level1)
###########################
else:
out_dec_level1 = self.output(out_dec_level1) + inp_img
return out_dec_level1
Restormer 的代码解析
这段代码实现了 Restormer 的网络结构,它是一种基于 Transformer 的深度学习模型,主要用于图像修复任务。以下是它的主要组成部分和详细解析:
主要组件:
- Patch Embedding(
self.patch_embed):- 从输入图像中提取重叠的图像块,并将它们嵌入到更高维的特征空间中。
- 将输入图像转换为适合 Transformer 处理的张量。
- Transformer Blocks:
TransformerBlock使用自注意力机制和前馈神经网络进行特征提取。- Transformer 块被广泛应用于编码器、潜在空间(latent space)、解码器和后续的精细化阶段。
- 多级编码器:
- 编码器由多层级组成(
encoder_level1、encoder_level2、encoder_level3和latent),每一级提取更抽象的特征。 - 使用
Downsample层在层级之间减少空间分辨率。
- 编码器由多层级组成(
- 多级解码器:
- 解码器通过对称的多层级(
decoder_level3、decoder_level2、decoder_level1)逐步重建输出图像。 - 使用
Upsample层在层级之间增加空间分辨率。 - 从编码器传递的特征图与解码器中上采样的输出拼接,保留高分辨率细节。
- 解码器通过对称的多层级(
- 精细化处理:
- 使用额外的 Transformer 块(
self.refinement)对解码器的输出进行进一步优化,提高图像质量。
- 使用额外的 Transformer 块(
- 双像素散焦任务(Dual-Pixel Defocus Task,可选):
- 当
dual_pixel_task=True时,增加一个跳跃连接(self.skip_conv),用于专门处理散焦去模糊任务。
- 当
- 最终输出:
- 使用一个卷积层(
self.output)将处理后的特征图映射到所需的输出通道。 - 默认情况下,模型将输入图像添加到最终输出,形成残差学习(
output + inp_img)。
- 使用一个卷积层(
参数说明:
inp_channels和out_channels:输入和输出图像的通道数(例如,RGB 图像有 3 个通道)。dim:Transformer 块的初始特征维度。num_blocks:每个层级中 Transformer 块的数量。heads:每个层级的注意力头数量。ffn_expansion_factor:Transformer 块中前馈网络的扩展因子。LayerNorm_type:Layer Normalization 的类型(支持WithBias和BiasFree)。
前向传播过程:
- 输入图像通过 Patch Embedding 层进行初步处理。
- 编码器通过多个层级提取特征,每经过一层,空间分辨率逐渐减小。
- 在潜在空间中,Transformer 块对抽象特征进行处理。
- 解码器逐步重建图像,并利用编码器传递的特征保留细节。
- 解码器的输出经过精细化处理,最终生成修复后的图像。
- 对于普通图像修复任务,输出通过残差连接(
output + inp_img)返回结果;对于特定任务(如双像素散焦任务),会采用特定的跳跃连接。
适用场景:
- 图像去噪
- 超分辨率
- 去模糊
- 一般的图像修复任务
1. OverlapPatchEmbed 模块
其实现为
## Overlapped image patch embedding with 3x3 Conv
class OverlapPatchEmbed(nn.Module):
def __init__(self, in_c=3, embed_dim=48, bias=False):
super(OverlapPatchEmbed, self).__init__()
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=3, stride=1, padding=1, bias=bias)
def forward(self, x):
x = self.proj(x)
return x
其主要特点是重叠特性,相邻像素块之间共享信息(与非重叠方式相比),增强了局部特征的提取能力。
2. TransformerBlock 模块
实现为
class TransformerBlock(nn.Module):
def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type):
super(TransformerBlock, self).__init__()
self.norm1 = LayerNorm(dim, LayerNorm_type)
self.attn = Attention(dim, num_heads, bias)
self.norm2 = LayerNorm(dim, LayerNorm_type)
self.ffn = FeedForward(dim, ffn_expansion_factor, bias)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.ffn(self.norm2(x))
return x
LayerNorm
class LayerNorm(nn.Module):
def __init__(self, dim, LayerNorm_type):
super(LayerNorm, self).__init__()
if LayerNorm_type =='BiasFree':
self.body = BiasFree_LayerNorm(dim)
else:
self.body = WithBias_LayerNorm(dim)
def forward(self, x):
h, w = x.shape[-2:]
return to_4d(self.body(to_3d(x)), h, w)
在前面打印的模型结构中,我们看到使用的都是WithBias_LayerNorm。
其实现为:
class WithBias_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(WithBias_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
mu = x.mean(-1, keepdim=True)
sigma = x.var(-1, keepdim=True, unbiased=False)
return (x - mu) / torch.sqrt(sigma+1e-5) * self.weight + self.bias
这段代码实现了一个自定义的 LayerNorm 层,命名为 WithBias_LayerNorm,它通过加权和偏置参数对输入进行归一化。此实现保留了可学习的权重参数(self.weight)和偏置参数(self.bias)。
主要功能
Layer Normalization 是一种归一化技术,通常用于深度学习网络中的非卷积层。
它通过对输入的最后一个维度计算均值和方差进行归一化,目的在于加快训练速度和提高模型性能。
代码解析
1. 构造函数(__init__):
- 参数:
normalized_shape:归一化的维度大小,通常与输入张量的最后一个维度一致。
- 初始化:
self.weight:形状与normalized_shape一致的可学习参数,用于对归一化后的输出进行缩放(初始化为全 1)。self.bias:形状与normalized_shape一致的可学习参数,用于对归一化后的输出添加偏置(初始化为全 0)。normalized_shape被转换为torch.Size对象,确保它是一个有效的形状。
2. 前向传播(forward):
- 输入张量
x的最后一个维度被归一化:- 计算均值:
mu = x.mean(-1, keepdim=True)
沿最后一个维度计算均值,结果保留维度。 - 计算方差:
sigma = x.var(-1, keepdim=True, unbiased=False)
沿最后一个维度计算无偏估计的方差。 - 归一化:
将输入减去均值,然后除以标准差 ((\text{sqrt(variance)} + 1e-5)),用于稳定计算。 - 缩放与偏移:
对归一化后的值应用self.weight和self.bias。
- 计算均值:
输出的形状与输入一致。
使用示例
假设输入张量的形状为 ([B, C, L]),最后一个维度 (L) 是需要归一化的维度。
import torch
import torch.nn as nn
# 创建 WithBias_LayerNorm 实例
normalized_shape = 64
layer_norm = WithBias_LayerNorm(normalized_shape)
# 随机生成输入张量 (batch_size=8, features=64, sequence_length=128)
x = torch.randn(8, 128, 64)
# 应用 LayerNorm
output = layer_norm(x)
# 输出形状
print(output.shape) # torch.Size([8, 128, 64])
特点
- 可学习参数:
self.weight和self.bias提供了灵活性,使模型可以在训练过程中学习如何缩放和偏移归一化后的值。
- 最后一维归一化:
- 默认只对最后一个维度进行归一化操作,这通常用于序列数据(如 NLP 或 Transformer 相关任务)。
- 数值稳定性:
- 在标准差的计算中添加 (1e-5) 防止除零错误。
与 PyTorch 内置 LayerNorm 的区别
- PyTorch 的
nn.LayerNorm同样支持可学习的权重和偏置。 - 此实现是一个简化版本,但功能类似,并提供自定义的灵活性。
Attention
## Multi-DConv Head Transposed Self-Attention (MDTA)
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b,c,h,w = x.shape
qkv = self.qkv_dwconv(self.qkv(x))
q,k,v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
out = (attn @ v)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out
这段代码实现了 Multi-DConv Head Transposed Self-Attention (MDTA),是用于图像或特征图的自注意力机制。MDTA 结合了多头注意力机制和深度可分离卷积,能够有效提取局部和全局特征。
主要组成部分解析
1. 初始化方法 (__init__)
- 输入参数:
dim:输入特征的通道数。num_heads:多头注意力的头数。bias:是否为卷积操作添加偏置。
- 主要组件:
self.num_heads:- 多头注意力的头数,每个头分别学习一部分特征。
self.temperature:- 一个可学习参数,形状为 ([ \text{num_heads}, 1, 1 ])。在注意力权重计算中起到缩放作用。
self.qkv:- 一个 (1 \times 1) 的卷积层,将输入张量映射到查询(
q)、键(k)和值(v)三个特征空间。
- 一个 (1 \times 1) 的卷积层,将输入张量映射到查询(
self.qkv_dwconv:- 一个深度可分离卷积(Depthwise Convolution),对
qkv特征进行空间上的信息整合。
- 一个深度可分离卷积(Depthwise Convolution),对
self.project_out:- 一个 (1 \times 1) 的卷积层,用于映射输出特征回原始通道数。
2. 前向传播方法 (forward)
- 输入形状解析:
- 输入
x的形状为 ([b, c, h, w]),分别是批量大小、通道数、高度和宽度。
- 输入
- 生成
qkv特征:self.qkv:将输入张量通过 (1 \times 1) 卷积生成查询、键、值。self.qkv_dwconv:进一步通过深度可分离卷积整合局部空间信息。
- 特征拆分:
- 使用
chunk方法将qkv按通道数拆分为q(查询)、k(键)、v(值),每个张量的通道数为 (\text{dim})。
- 使用
- 特征重排列:
- 使用
rearrange将q、k和v转换为多头格式,形状变为 ([b, \text{num_heads}, c’, h \times w]),其中 (c’ = \text{dim} / \text{num_heads})。
- 使用
- 特征归一化:
- 对
q和k的最后一维进行 (L_2) 归一化,便于计算相似性。
- 对
- 注意力权重计算:
- (\text{attn} = \text{softmax}((q \cdot k^T) \cdot \text{temperature})),形状为 ([b, \text{num_heads}, h \cdot w, h \cdot w])。
- 注意力加权特征聚合:
- 通过 (\text{out} = \text{attn} \cdot v) 将注意力权重作用到
v上,生成最终聚合的特征。
- 通过 (\text{out} = \text{attn} \cdot v) 将注意力权重作用到
- 输出重排列与映射:
- 使用
rearrange将多头特征重新排列为原始通道格式。 - 通过
self.project_out将输出特征映射回输入的通道数。
- 使用
使用示例
假设输入特征图形状为 ([1, 64, 32, 32]):
import torch
import torch.nn as nn
from einops import rearrange
# 创建 Attention 实例
attention = Attention(dim=64, num_heads=8, bias=False)
# 随机生成输入张量
x = torch.randn(1, 64, 32, 32)
# 前向传播
output = attention(x)
# 输出形状
print(output.shape) # torch.Size([1, 64, 32, 32])
特点
- 多头注意力:
- 将输入特征拆分为多个子空间,每个子空间独立计算注意力,从而捕获更丰富的特征。
- 深度可分离卷积:
- 增强局部特征提取能力,同时减少参数量和计算量。
- 可学习温度参数:
- 为不同头的注意力权重提供可调节的缩放因子。
- 全局与局部特征整合:
- 结合自注意力(全局关系)和卷积操作(局部特征),提升模型性能。
Gated-Dconv Feed-Forward Network (GDFN)
## Gated-Dconv Feed-Forward Network (GDFN)
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim*ffn_expansion_factor)
self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2, kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x1) * x2
x = self.project_out(x)
return x
Gated-Dconv Feed-Forward Network (GDFN) 详解
GDFN 是一种改进的前馈网络架构,结合了卷积操作和门控机制,用于增强 Transformer 的局部特征提取能力。以下是对代码中每一部分的详细分析。
代码解析
1. 初始化方法:__init__
hidden_features = int(dim*ffn_expansion_factor)
dim: 输入特征的通道数。ffn_expansion_factor: 前馈网络扩展因子,用于增加特征维度,提升网络的表示能力。hidden_features: 中间特征维度,通常是输入维度的扩展版本。
self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)
- 功能: 用 ( 1 \times 1 ) 卷积将输入特征从 ( \text{dim} ) 映射到 ( 2 \times \text{hidden_features} )。
- 目的:
- 提升特征维度,为后续操作提供更大的表示能力。
- 将特征拆分为两部分,用于门控机制。
self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2, kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)
- 功能: 深度卷积操作,对 ( 2 \times \text{hidden_features} ) 的特征进行局部特征提取。
- 特点:
- 深度卷积: 通过
groups=hidden_features*2,使每个通道独立进行卷积操作。 - 目的:
- 提取局部空间上下文信息。
- 轻量化:相比标准卷积,深度卷积计算量更低。
- 深度卷积: 通过
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
- 功能: 用 ( 1 \times 1 ) 卷积将中间特征映射回原始维度 ( \text{dim} )。
- 目的: 保持网络的输入输出维度一致。
2. 前向传播:forward
x = self.project_in(x)
- 输入张量
x的形状为 ([b, \text{dim}, h, w])。 - 经过
project_in后,形状变为 ([b, 2 \times \text{hidden_features}, h, w])。
x1, x2 = self.dwconv(x).chunk(2, dim=1)
- 功能:
- 使用
dwconv提取局部空间特征。 - 通过
chunk将输出特征分为两部分 ( x1 ) 和 ( x2 ):- ( x1 ) 作为激活部分。
- ( x2 ) 作为门控部分。
- 使用
- 形状变化:
dwconv的输出形状与输入相同:([b, 2 \times \text{hidden_features}, h, w])。chunk将其分成两部分:([b, \text{hidden_features}, h, w]) 各一份。
x = F.gelu(x1) * x2
- 门控机制:
- 对 ( x1 ) 应用非线性激活函数
GELU: [ \text{GELU}(x) = 0.5x \left(1 + \tanh\left(\sqrt{\frac{2}{\pi}} (x + 0.044715x^3)\right)\right) ] - 将激活后的 ( x1 ) 与 ( x2 ) 逐元素相乘,形成门控机制: [ x = \text{GELU}(x1) \odot x2 ]
- 目的: 利用 ( x2 ) 对 ( x1 ) 进行动态调节,增强网络的表达能力。
- 对 ( x1 ) 应用非线性激活函数
x = self.project_out(x)
- 使用 ( 1 \times 1 ) 卷积将结果映射回原始维度 ( \text{dim} )。
- 输出形状为 ([b, \text{dim}, h, w])。
GDFN 的核心设计思想
- 前馈网络的扩展:
- 标准 Transformer 的前馈网络是两层全连接层,而 GDFN 使用卷积操作,增强了局部空间特征建模能力。
- 门控机制:
- 通过将中间特征分为两部分 ( x1 ) 和 ( x2 ),并引入动态门控机制,提升了网络的非线性表达能力。
- 轻量化卷积:
- 使用深度卷积(
dwconv)替代标准卷积,减少计算量的同时保留局部特征提取能力。
- 使用深度卷积(
- 组合非线性与空间特征提取:
- ( x1 ) 经
GELU提供非线性激活,而 ( x2 ) 提供空间信息的动态调节,两者结合提升了网络的表示能力。
- ( x1 ) 经
总结
GDFN 通过结合深度卷积和门控机制,在保持轻量化的同时,增强了局部特征建模能力和表达灵活性。这种设计非常适合图像恢复等任务,能够有效提取局部上下文信息,同时具备 Transformer 的全局建模能力。
Downsample模块
class Downsample(nn.Module):
def __init__(self, n_feat):
super(Downsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat//2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelUnshuffle(2))
def forward(self, x):
return self.body(x)
Downsample 模块解析
Downsample 是一个降采样模块,用于减少特征图的空间分辨率和通道数。以下是代码的详细分析:
代码解析
1. 初始化方法:__init__
self.body = nn.Sequential(
nn.Conv2d(n_feat, n_feat//2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelUnshuffle(2)
)
a. 卷积层
nn.Conv2d(n_feat, n_feat//2, kernel_size=3, stride=1, padding=1, bias=False)
- 输入: 通道数为 ( n_feat )。
- 输出: 通道数减半,变为 ( n_feat // 2 )。
- 卷积操作参数:
kernel_size=3: 使用 ( 3 \times 3 ) 卷积核。stride=1: 卷积操作不会跳过像素。padding=1: 确保输出分辨率与输入相同(零填充)。
- 作用: 将特征的通道数减少一半,同时进行局部信息提取。
b. 像素去重排列 (PixelUnshuffle)
nn.PixelUnshuffle(2)
- 功能: 按 ( 2 \times 2 ) 的块对特征图进行像素重新排列,将空间分辨率缩小为原来的 ( 1/2 ),而通道数增加 ( 4 ) 倍。
- 假设输入形状为 ([b, c, h, w]):
- 输出形状变为 ([b, c \times 4, h/2, w/2])。
- 假设输入形状为 ([b, c, h, w]):
- 结合卷积后的输出:
- 通道数经过卷积变为 ( n_feat // 2 )。
- 经过
PixelUnshuffle后通道数变为 ( (n_feat // 2) \times 4 = 2 \times n_feat )。
- 目的: 减少空间分辨率,增加特征表示的局部信息密度。
2. 前向传播:forward
def forward(self, x):
return self.body(x)
- 输入 ( x ) 的形状为 ([b, n_feat, h, w])。
- 经过卷积: 通道数从 ( n_feat ) 变为 ( n_feat // 2 ),空间分辨率保持不变: [ [b, n_feat, h, w] \to [b, n_feat//2, h, w] ]
- 经过 PixelUnshuffle: 将空间分辨率缩小为 ( h/2 \times w/2 ),通道数增加为 ( 2 \times n_feat ): [ [b, n_feat//2, h, w] \to [b, 2 \times n_feat, h/2, w/2] ]
模块功能总结
- 降采样:
- 将输入的空间分辨率减少 ( 1/2 )。
- 同时,通道数增加为原来的 ( 2 ) 倍,特征表示密度更高。
- 像素去重排列:
PixelUnshuffle提供了一种轻量级的降采样方式,与传统的池化或步幅卷积不同,它直接重新排列像素以减少分辨率。
- 灵活性:
- 通过卷积减少通道数,结合
PixelUnshuffle的空间降采样,既提取了局部特征,又保持了降采样后的信息丰富度。
- 通过卷积减少通道数,结合
这种设计在图像重建、超分辨率等任务中非常常见,因为它在降采样的同时,能够保留更多细节信息供后续网络使用。
Upsample模块
class Upsample(nn.Module):
def __init__(self, n_feat):
super(Upsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat*2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2))
def forward(self, x):
return self.body(x)
### Upsample 模块解析
Upsample 是一个上采样模块,用于增加特征图的空间分辨率和减少通道数。以下是代码的详细分析:
代码解析
1. 初始化方法:__init__
self.body = nn.Sequential(
nn.Conv2d(n_feat, n_feat*2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2)
)
a. 卷积层
nn.Conv2d(n_feat, n_feat*2, kernel_size=3, stride=1, padding=1, bias=False)
- 输入: 通道数为 ( n_feat )。
- 输出: 通道数增加为 ( n_feat \times 2 )。
- 卷积操作参数:
kernel_size=3: 使用 ( 3 \times 3 ) 卷积核。stride=1: 卷积操作不会跳过像素。padding=1: 确保输出分辨率与输入相同(零填充)。
- 目的: 增加通道数,同时提取特征信息。
b. 像素移位排列 (PixelShuffle)
nn.PixelShuffle(2)
- 功能: 使用 ( 2 \times 2 ) 的分块方式对通道维度进行重新排列,将通道数减少为原来的 ( 1/4 ),同时将空间分辨率增加 ( 2 ) 倍。
- 假设输入形状为 ([b, c, h, w]):
- 输出形状变为 ([b, c/4, h \times 2, w \times 2])。
- 假设输入形状为 ([b, c, h, w]):
- 结合卷积后的输出:
- 通道数经过卷积变为 ( n_feat \times 2 )。
- 经过
PixelShuffle后通道数变为 ( (n_feat \times 2) / 4 = n_feat / 2 )。 - 但由于卷积部分输出通道数为 ( n_feat \times 2 ),实际
PixelShuffle将通道数恢复为 ( n_feat )。
2. 前向传播:forward
def forward(self, x):
return self.body(x)
- 输入 ( x ) 的形状为 ([b, n_feat, h, w])。
- 经过卷积: 通道数从 ( n_feat ) 增加为 ( n_feat \times 2 ),空间分辨率保持不变: [ [b, n_feat, h, w] \to [b, n_feat \times 2, h, w] ]
- 经过 PixelShuffle: 将空间分辨率扩大为 ( h \times 2 ) 和 ( w \times 2 ),通道数恢复为 ( n_feat ): [ [b, n_feat \times 2, h, w] \to [b, n_feat, h \times 2, w \times 2] ]
模块功能总结
- 上采样:
- 将输入的空间分辨率增加 ( 2 ) 倍。
- 同时,将通道数调整为保持一致的数量。
- 像素移位排列:
PixelShuffle提供了一种轻量级的上采样方式,它以低计算成本实现空间分辨率的提升。
- 结合卷积的灵活性:
- 卷积不仅增加了通道数,同时也引入了局部特征的提取能力,为上采样后的特征表示提供更丰富的信息。
这种设计在图像生成、超分辨率以及去噪等任务中非常常见,因为它能够有效地提升分辨率并保持特征的一致性。
forward计算过程分析
如图是forward的计算过程。
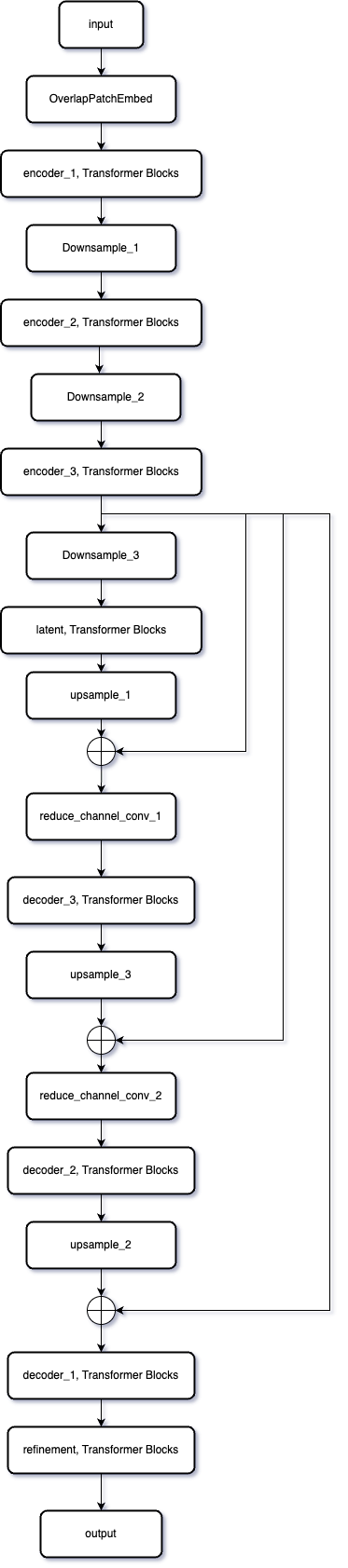
从这个结构图可以看出,Restormer 采用了一个经典的编码器-解码器结构,并结合了多级Transformer块和降采样/上采样模块。以下是对其结构的详细分析:
整体设计
- 输入部分:
OverlapPatchEmbed模块用作输入特征提取,通过卷积将原始图像转化为嵌入特征。
- 编码器部分:
- 包含了多个阶段的
Transformer Blocks,每个阶段特征图通过Downsample模块进行降采样,逐渐提取更高层次的特征。 - 降采样后,特征维度增加(比如通道数翻倍),而空间分辨率减小。
- 包含了多个阶段的
- 瓶颈部分 (latent):
- 在网络的中间部分,处理最小分辨率的特征,通过更多
Transformer Blocks捕获全局上下文信息。
- 在网络的中间部分,处理最小分辨率的特征,通过更多
- 解码器部分:
- 解码器通过
Upsample模块将特征逐步上采样回原始分辨率。 - 每个上采样阶段都会与对应编码器阶段的输出进行特征拼接(如图中显示的跳跃连接)。
- 拼接后的特征通过
reduce_channel_conv减少通道数,并传入Transformer Blocks进行处理。
- 解码器通过
- 输出部分:
- 最终通过
refinement模块进一步细化特征,最后使用卷积生成与输入分辨率相同的输出图像。
- 最终通过
关键模块解析
- Overlap Patch Embedding:
- 使用卷积将输入图像分割为有重叠的图像块,并将其映射到嵌入空间。
- Downsample 和 Upsample:
Downsample通过PixelUnshuffle和卷积实现空间分辨率的减小和通道数的增加。Upsample则使用PixelShuffle和卷积将通道数减小并恢复空间分辨率。
- Transformer Blocks:
- 提取每一层的特征,并通过自注意力机制捕获远距离依赖和全局特征。
- 这些模块在编码器和解码器中重复使用,确保跨层次特征的融合。
- 跳跃连接 (Skip Connections):
- 编码器中各阶段的输出与解码器中相应阶段的输入进行拼接,这种跳跃连接可以有效保留低层次特征,提高重建的精确度。
- Refinement:
- 在解码完成后,通过额外的
Transformer Blocks进一步细化特征,确保输出图像的质量。
- 在解码完成后,通过额外的
优点分析
- 多级特征提取:
- 编码器逐步提取高层次语义特征,解码器逐步恢复空间分辨率,同时通过跳跃连接保留了底层细节。
- Transformer的引入:
- Transformer块捕获了远距离依赖和全局上下文信息,非常适合用于图像复原任务。
- 高效的降采样/上采样:
- 采用
PixelShuffle和PixelUnshuffle进行分辨率调整,降低了计算复杂度。
- 采用
- 细化机制:
- 最后的
Refinement模块进一步提升了输出图像的质量。
- 最后的
适用场景
- 图像复原任务,如去噪、超分辨率重建、去模糊等。
- 需要捕获全局依赖关系和局部细节的高质量图像处理任务。