raw域去噪论文Mobile Aware Denoiser Network (MADNet) for Quad Bayer Images解读
Published:
论文、代码和ppt地址:Mobile Aware Denoiser Network (MADNet) for Quad Bayer Images。
摘要
像素合并是近来日益流行的一个术语。 它是利用高像素密度的相机传感器,在遇到低光照水平时将像素组合在一起,而在强光场景下,像素则不进行组合。其中一种像素排列方式是四拜耳(Quad Bayer)或四像素(Tetra)结构。从历史上看,人们在对拜耳图像进行去马赛克和去噪方面投入了大量精力,但由于四拜耳传感器是近期才出现的,对其关注较为有限。 针对四拜耳图像训练深度学习网络时面临的一个独特挑战是如何对这类数据(空间排列与深度排列)进行编码。通常,在对拜耳图像训练去噪网络时,输入会被拆分成各个独立的颜色通道,然而,正如结果所显示的那样,在处理四拜耳图像时采用这种方法会产生质量较差的结果。
在本文中,我们提出了一种对四像素(Tetra)传感器像素进行分组的高效方法,该方法能在图像质量和推理速度之间实现最佳权衡。由于像素数量极多,网络训练需要海量的数据,在数据有限的情况下,网络很容易出现过拟合现象。为了对网络进行正则化处理以避免过拟合,我们提出了一种新颖的通道间损失函数,它能有效地对网络训练进行正则化。最后,我们进行了消融研究,以分析我们所提出的损失函数、针对四像素传感器的像素分组以及具有不同噪声水平的输入数据所占比例。结果表明,本文所提出的技术能生成比传统方法质量更好的去噪后的四像素图像。我们希望本文能够启发人们进一步开展针对新型四拜耳(Quad Bayer)、十六像素(Hexa Deca)以及九像素(Nona)传感器算法开发方面的研究。
1. Introduction
图像去噪属于被称为图像复原的一类问题,并且被视作众多图像处理流程中的一个重要组成部分[4, 6, 35]。传统上,图像去噪是针对单灰度图像或经过去马赛克处理后的3通道RGB图像进行的[7, 11, 18]。然而,很多时候,需要在去马赛克处理之前,对处于线性原始格式的这些图像进行去噪[3, 9]。原始图像中的噪声往往相关性较低,因此处理起来挑战性较小;此外,与RGB图像相比,原始图像的未知像素值数量要少三分之一。不过,使得对原始格式图像进行去噪变得困难的原因在于,这些图像是由彼此相邻的不同颜色的像素组成的[1, 29]。不同颜色通道在像素网格上的确切排列方式取决于传感器中所使用的特定彩色滤光片阵列。
随着智能手机相机行业朝着诸如20000万像素这类高像素相机的趋势发展,最新的互补金属氧化物半导体(CMOS)传感器如今正在采用更多新颖的彩色滤光片阵列(CFA)模式,比如四拜耳(Tetra)、九像素(Nona)以及十六像素(Hexa Deca,Tetra2)模式[12 - 14, 16]。这些新的彩色滤光片阵列模式提供了将由相同颜色通道组成的相邻像素进行合并的灵活性,以便在低光照场景下获得更好的成像信号。对这些非拜耳原始图像进行去噪带来了独特的挑战,这是因为需要处理的像素数量极多,而且不同颜色像素之间的像素间距增大了[16]。
过去已经提出了许多不同类型的去噪技术。一些较为著名的去噪方法包括利用图像自相似性的基于块的去噪方法[2, 24, 25]、字典学习[6]、低秩逼近[10, 30]、贝叶斯建模[19, 20, 26, 34]以及频域方法[8, 31]。近来,随着图形处理器(GPU)的发展进步,深度学习为解决去噪问题开辟了新的途径[3, 17, 33]。然而,这些深度神经网络大多是针对RGB图像或传统拜耳模式原始图像进行训练的[3, 9]。传统上,为了在拜耳原始图像上训练深度神经网络,做法是将各个颜色相位分离成一个4通道的RGGB图像[3]。然而,这种方法的一个关键缺陷在于,当你将四拜耳图像中的16个通道分离出来时,由于空间下采样,会产生混叠伪影。
在本文中,我们提出了一种基于深度学习的稳健方法,用于针对包括四拜耳图像这类非拜耳模式在内的原始图像训练去噪网络。我们在本文中的三个主要贡献如下。首先,我们提议采用一种可能并非显而易见的像素分组方式,即,我们不将四拜耳图像编码为16个通道,而是通过合并对应相同颜色的相邻像素将其拆分为4个通道。其次,我们受传统全变分损失函数的启发,提出了一种新颖的通道间损失函数,不过有一个关键区别;我们的通道间损失函数组合会对预测像素值与真实图像中相邻像素之间的差异进行惩罚。第三,我们提出了一种实用的方法,通过采用两组不同的训练数据来对去噪神经网络的训练进行正则化,即往往具有较高噪声水平的低曝光数据和往往噪声较少的高曝光数据。
2. Method
我们的四拜耳去噪算法的整体架构如图1所示。该算法包含三个组成部分:四拜耳到四通道转换器、去噪网络、四通道到四拜耳转换器。四拜耳到四通道转换器会将四拜耳数据转换为四通道格式。然后,我们将四通道数据输入到第二个组成部分——去噪网络中,最后,四通道到四拜耳转换器会将经过去噪的四通道输出转换为四拜耳格式,以供后续任务使用。此外,我们创建了一个能保留细节的通道间损失函数。在本节中,我们将详细介绍我们方法的各个组成部分。
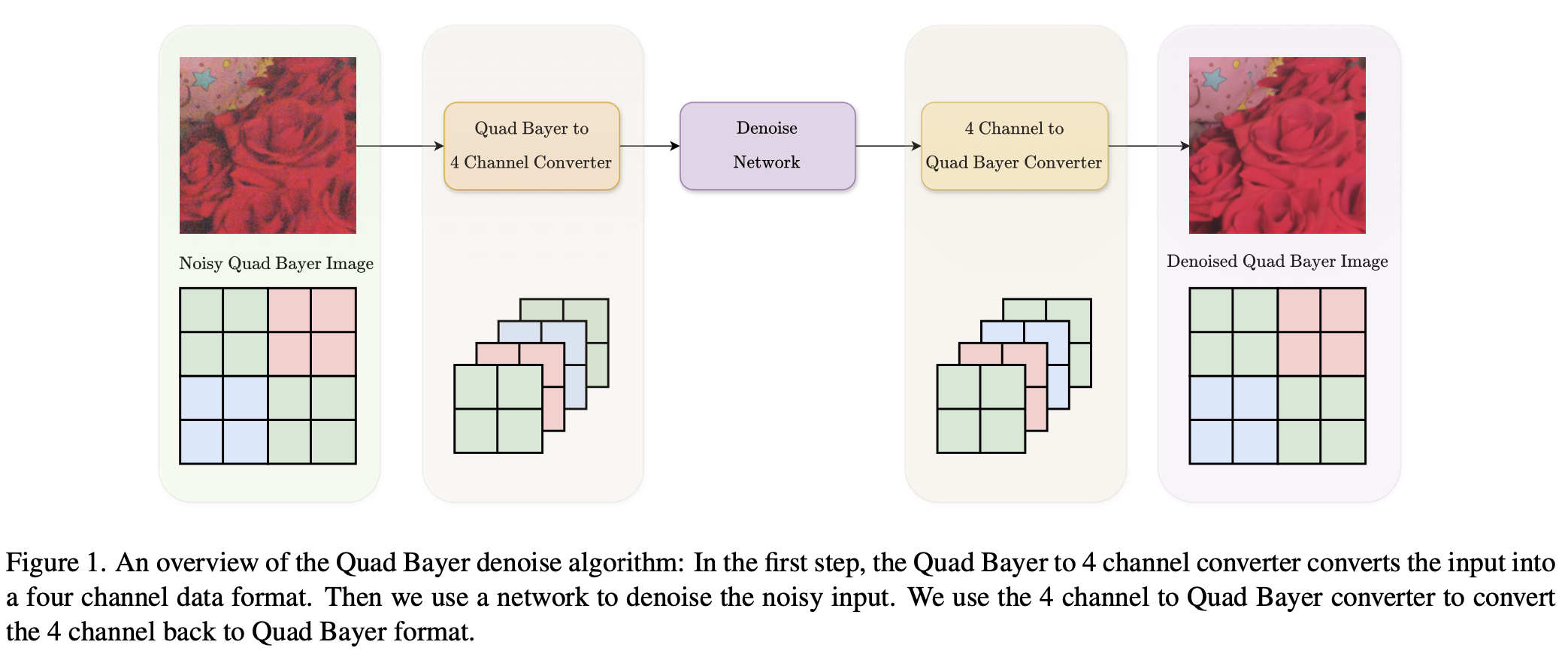 图1. 四拜耳去噪算法概述:第一步,四拜耳到四通道转换器将输入转换为四通道数据格式。然后,我们使用一个网络对含噪输入进行去噪。我们利用四通道到四拜耳转换器将四通道数据再转换回四拜耳格式。
图1. 四拜耳去噪算法概述:第一步,四拜耳到四通道转换器将输入转换为四通道数据格式。然后,我们使用一个网络对含噪输入进行去噪。我们利用四通道到四拜耳转换器将四通道数据再转换回四拜耳格式。
2.1. Quad Bayer/4 Channel Converter
在本节中,我们将讨论如何对四拜耳图像中的像素进行分组,以便为网络准备输入数据,以及如何再转换回四拜耳格式。
四拜耳到四通道转换器 如图2所示,在将四拜耳图像输入去噪网络之前,有两种主流的像素分组方法。一种是直接使用四拜耳图像本身。另一种是将四拜耳模式拆分为16个通道,如图2 - c所示。在此,我们提出一种新的像素分组方式。我们依据四拜耳模式内的颜色簇进行分组。图2 - b展示了如何组织这些像素。经过转换器后,四拜耳图像被转换为4通道数据。 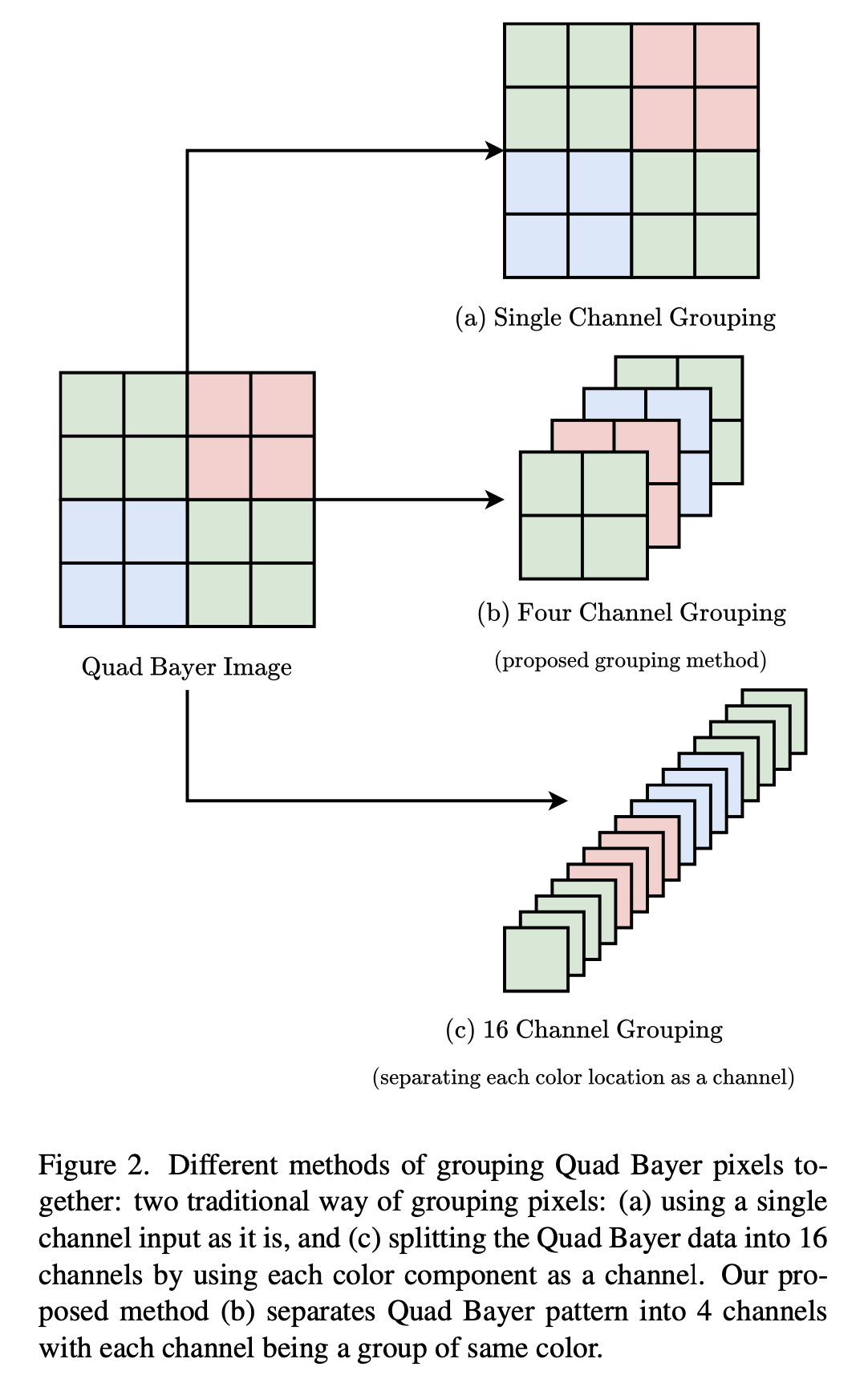 图2. 将四拜耳像素组合在一起的不同方法:两种传统的像素分组方式:(a)直接使用单通道输入;(c)通过将每个颜色分量作为一个通道,把四拜耳数据拆分为16个通道。我们提出的方法(b)是将四拜耳模式分离为4个通道,每个通道是一组相同颜色的像素。
图2. 将四拜耳像素组合在一起的不同方法:两种传统的像素分组方式:(a)直接使用单通道输入;(c)通过将每个颜色分量作为一个通道,把四拜耳数据拆分为16个通道。我们提出的方法(b)是将四拜耳模式分离为4个通道,每个通道是一组相同颜色的像素。
四通道到四拜耳转换器 这一步是2.1节所述过程的逆过程,它将4通道数据转换回四拜耳格式。
2.2. 去噪网络
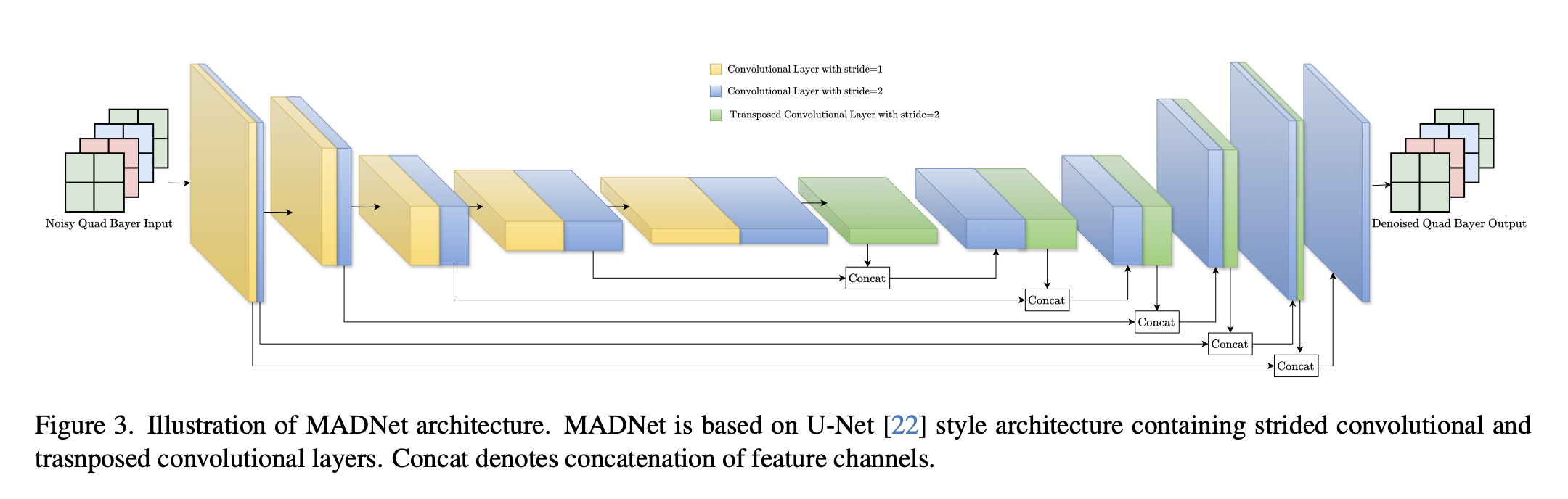
我们在图3中展示了详细的网络架构。我们的网络基于非常适用于图像去噪的U - Net [22]架构。不过,我们提出了一个通用框架,在该框架下任何网络都可以接入用于对图像进行去噪。
在我们的网络中,我们使用三种类型的卷积层:标准卷积层、用于下采样的步长卷积层以及用于上采样的转置卷积层。在编码器中,我们先使用标准卷积层,接着使用步长卷积层,将特征的空间维度按因子2缩小,并将通道数量增加2(第一层的通道数量为16)。编码器中总共有5个连续的模块。
在解码器中,我们先使用转置卷积层,接着使用标准卷积层,将特征的空间维度按因子2增大,并将通道数量减少2(即减至16)。在这里,我们使用解码器中的特征与来自编码器的对应特征进行拼接来实现跳跃连接。
2.3. 保留细节的通道间损失函数
在相关文献中,全变分(TV)目标函数已被广泛用于保边图像去噪[23]。受全变分损失成功应用的启发,我们提出了一种新颖的通道间损失(ICL)函数,其目的是使四拜耳模式中相同颜色邻域像素具有相似的强度值,同时保留边缘。然而,全变分损失与通道间损失的关键区别在于,全变分损失仅对输出图像施加约束,而我们计算的是输出图像与真实图像之间邻域像素的相似度。通道间损失(ICL)定义为 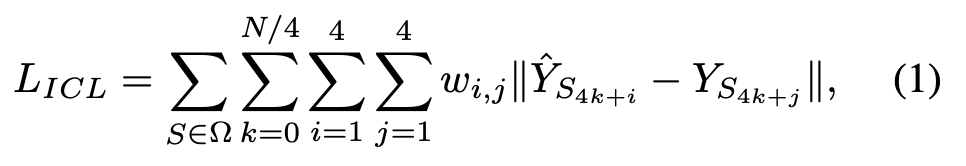
其中,Ω = {R(红色), Gr(绿红), B(蓝色), Gb(绿蓝)}是四拜耳中的颜色空间,N表示每幅图像中的像素数量,S表示通道索引,k是4像素组的索引,i和j是每个组内像素的索引,wi,j是差值的权重。为了便于理解,通道间损失(ICL)可进一步分为两部分:自身通道间损失(Lself ICL)和相邻通道间损失(Lneighbor)。

2.4. 总体的损失函数

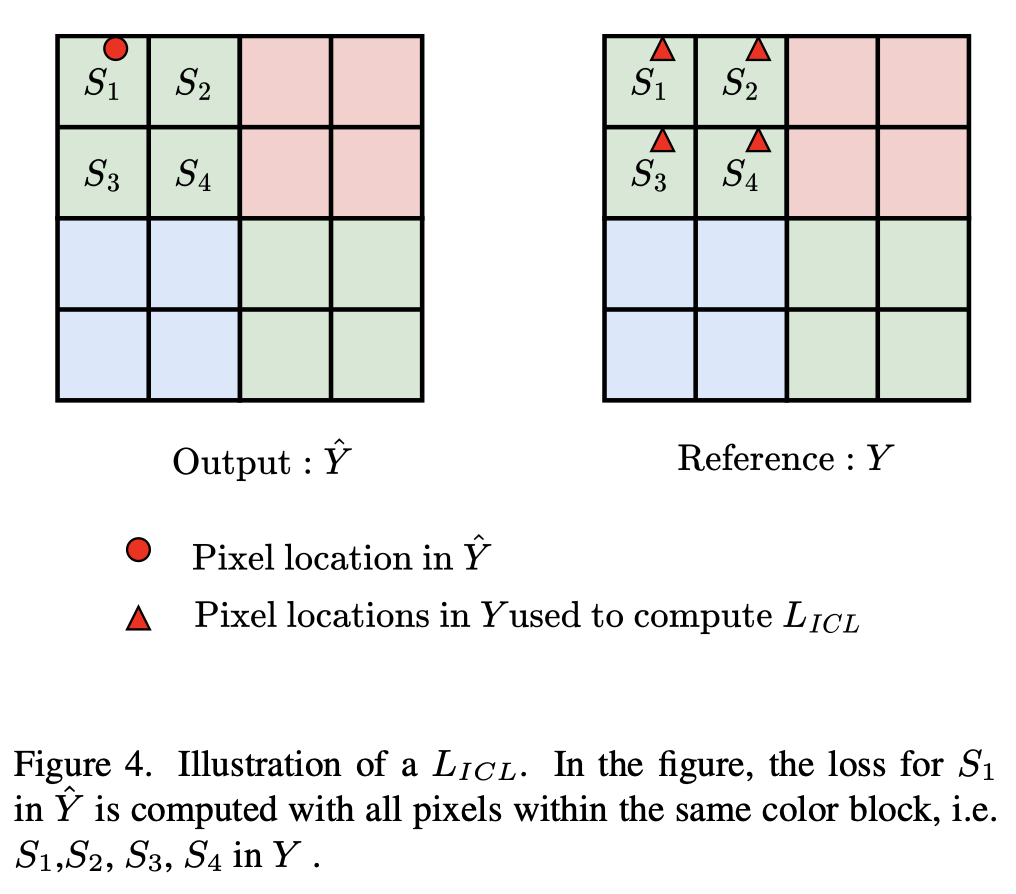
3 实验
在本节中,我们将详细介绍为评估所提出的去噪技术而开展的实验情况。我们首先会详细说明实验设置,例如训练数据、评估方法以及对比方法。然后,我们将针对最先进的(SOTA)去噪模型,从客观和视觉角度来评估我们模型的性能。最后,我们会进行几项消融实验,以分析通道间损失(ICL)目标的重要性、ICL与标准全变分目标之间的性能差异以及四拜耳到四通道转换的效果。
3.1. 实验设置
训练数据
我们采集了一个新的数据集,用于训练和对原始四拜耳图像进行基准测试。这些图像是使用三星Galaxy S22智能手机相机在低光照条件下拍摄的,该相机使用了一款专门设计的软件来获取分辨率为6120×8160的四拜耳格式原始图像。这款软件还能够修改诸如感光度(ISO)和曝光时间之类的相机设置。拍摄时,智能手机被固定在三脚架上,并通过远程触发进行拍摄。该数据集中包含了室内和室外场景的图像。
采集的数据包含两组含噪图像:(a)集合1——包含短曝光图像;(b)集合2——包含长曝光图像。对于这两个集合中的每一幅含噪图像,都有一幅对应的参考(真实)图像,其曝光时间显著更长,从而生成一幅噪声低且感知质量更好的真实图像。该数据集中的一对示例图像如图5所示。为避免运动模糊问题,我们在实验中仅使用没有任何运动的静态图像。此外,如图5所示,来自两个不同集合的图像可能会使用相同的参考图像。集合1和集合2中各总共采集了2876对含噪 - 参考图像对。纳入两组不同数据的目的是使去噪模型对更广泛的噪声水平更具鲁棒性。为采集含噪图像,曝光时间设置在1/50到1/5秒之间。对于参考图像,曝光时间增加了近10到30倍,并且相应地降低了ISO值,以获得曝光相同的图像。
对于模型训练,该数据集又被随机划分为两组,分别包含4600对和1152对图像,对应训练数据和测试数据。我们还确保了两个集合中的图像在训练数据和测试数据中都有相同的占比。

训练和推理细节
MADNet经过了25万次迭代训练,批次大小为4。此外,在训练期间,批次中的每幅图像都被随机裁剪成3个尺寸为512×512的图像块。使用了Adam优化器[15],其恒定学习率为5×10⁻⁴(β₁ = 0.9,β₂ = 0.999)来训练MADNet。对于公式(2)中的超参数,采用了以下取值:自身系数αself = 0.1,相邻系数αneighbor = 0.05以及结构相似性系数αSSIM = 0.85。所有的实现都是使用PyTorch2框架在Python中完成的,并且所有模型都在单个英伟达A100图形处理器(GPU)上进行训练。为了获得移动端设备上的推理能力,采用了骁龙神经处理引擎(SNPE)。使用SNPE工具包[21]将训练好的PyTorch模型转换为与移动端设备兼容的格式。
对比和评估方法
我们客观地将MADNet的性能与两种流行的最先进模型进行了对比:一种是BM3D [5],它使用传统的协同滤波方法;另一种是DnCNN [32],它采用端到端训练的深度模型来去除噪声。在我们的实验中,我们直接在四拜耳图像上运行BM3D算法,未事先将其转换为其他格式,例如去马赛克后的RGB图像。对于DnCNN,为了进行公平对比,我们使用我们的四拜耳图像对该模型进行了重新训练,这些四拜耳图像按照如图1所示的4通道分量的相同方式进行了编码。
对于客观评估,我们采用了标准的图像质量指标:峰值信噪比(PSNR)和结构相似性指数(SSIM)[28]。对每幅图像都计算了PSNR和SSIM值,并报告了整个数据集中的平均值。由于我们重点关注的是在智能手机上进行高效处理,我们还对比了上述模型在最新的三星Galaxy S24设备上的处理时间。
3.2. 去噪性能
在表1中,我们将MADNet的客观图像质量指标与其他去噪方法进行了对比。从表中可以看出,MADNet在峰值信噪比(PSNR)和结构相似性指数(SSIM)数值方面均优于其他方法。此外,MADNet在处理时间方面也优于其他最先进模型。我们没有报告BM3D的处理时间,因为它没有针对神经网络处理器(NPU)处理进行优化,并且与其他方法相比,作者发布的代码进行去噪所花费的时间要长得多。在图6中,我们从视觉角度对比了测试数据中两个场景的去噪结果。这些结果表明,与DnCNN和BM3D相比,MADNet保留了更多细节。 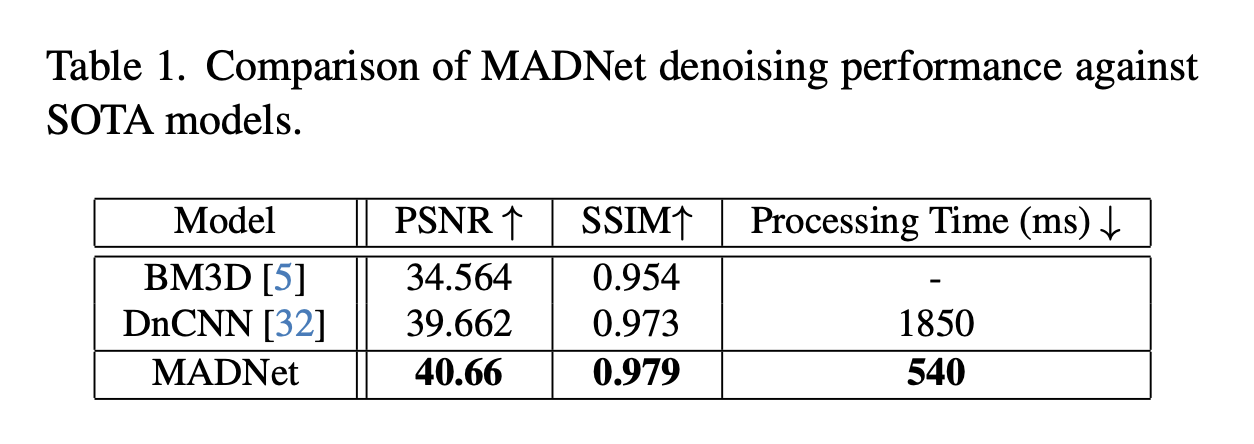

3.3. 消融实验
在此,我们将详细介绍为分析经过训练的MADNet模型的鲁棒性和泛化能力而开展的各项消融实验情况。
短曝光和长曝光图像的影响
在3.1节中我们提到,MADNet是使用包含数量相等的短曝光(集合1)和长曝光(集合2)图像的组合数据集进行训练的。采用不同曝光水平图像的目的是获得一个可用于广泛噪声特性范围的单一模型。为验证将不同噪声水平的数据集相结合的实用性,我们开展了一项实验,让MADNet仅使用短曝光图像或长曝光图像进行训练。我们将这些经过训练的模型的输出质量与使用两组组合数据集训练的模型进行了对比。结果如表2所示,可以看出使用组合数据集训练模型在图像质量指标方面具有些许优势。在图7中,我们提供了去噪结果的视觉对比,从该图可以看出,仅使用长曝光图像会导致伪影,因为噪声没有被完全去除,而仅使用短曝光图像会导致过度平滑。采用这两种曝光水平对于综合两组图像的最佳特性并获得更优的图像质量是至关重要的。 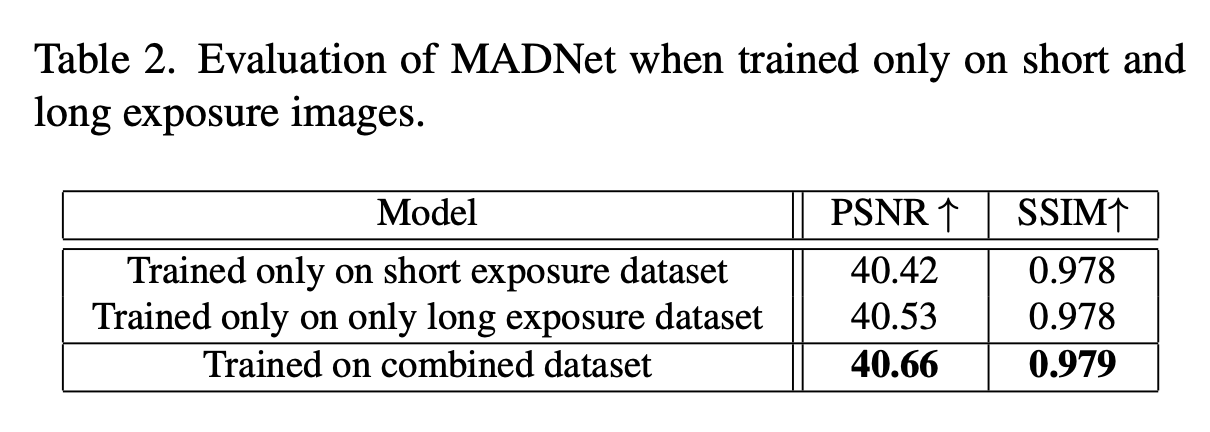

ICL的重要性
MADNet是使用公式(2)中详述的通道间损失(ICL)和结构相似性指数(SSIM)损失的组合进行训练的。在本实验中,我们通过使用不同损失函数组合训练多个模型来分析该目标中各组成部分的重要性。结果如表3所示,从所报告的值来看,使用所提出的ICL和SSIM目标组合在客观质量指标方面能产生最高的值。 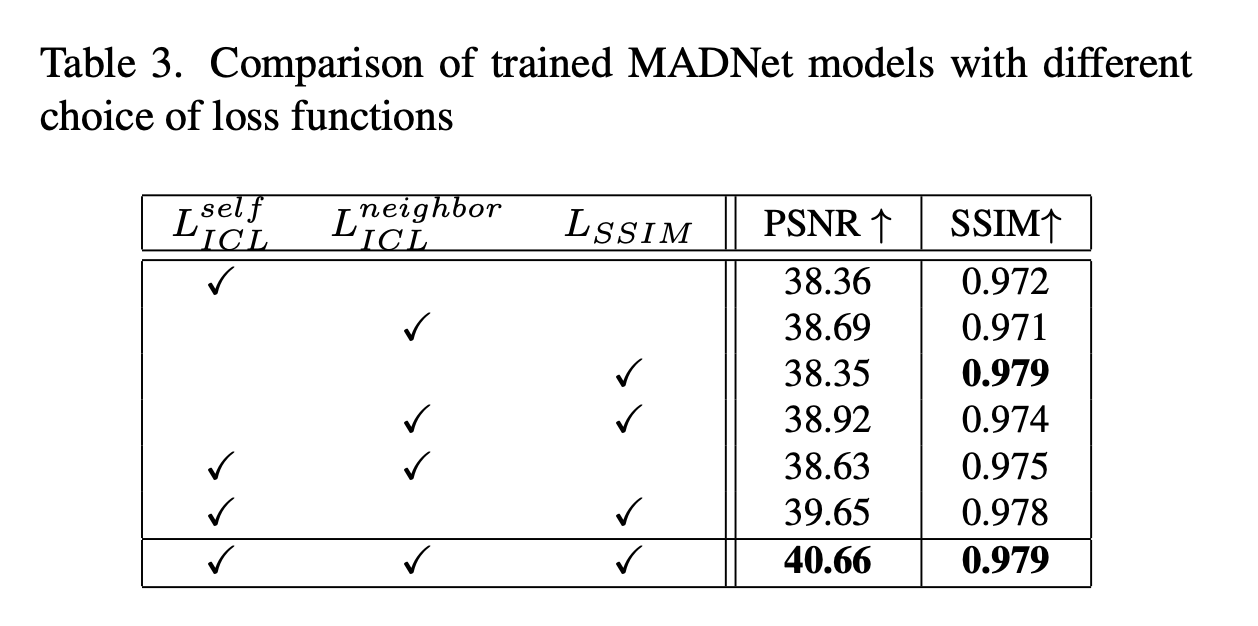
全变分(Total Variation)和通道间损失(ICL)目标的对比
我们在MADNet中的一个关键贡献是在训练中采用了自身通道间损失(Lself ICL)和相邻通道间损失(Lneighbor ICL)。正如2.3节所述,通道间损失(ICL)主要是受全变分损失的启发。在此,我们开展了一项实验,在公式(2)中用全变分正则化来替换相邻通道间损失(Lneighbor ICL),并对MADNet进行训练。全变分损失如下所示。
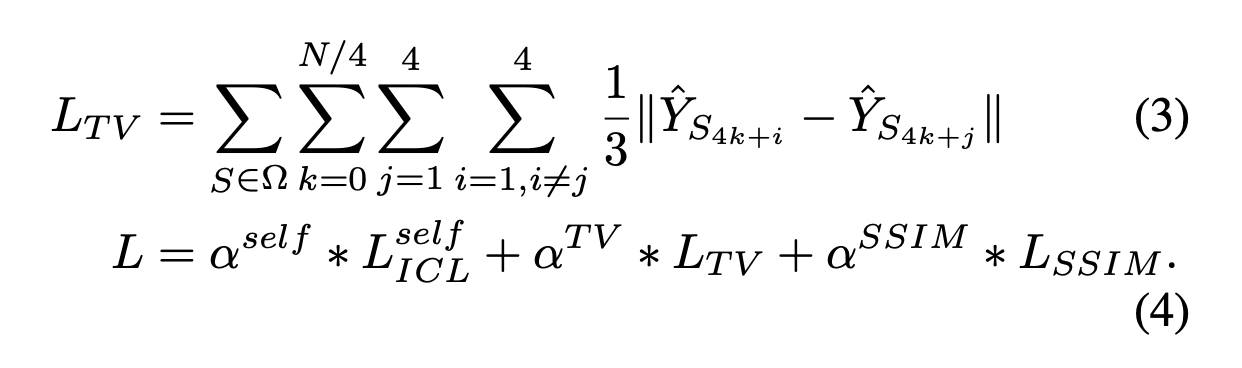
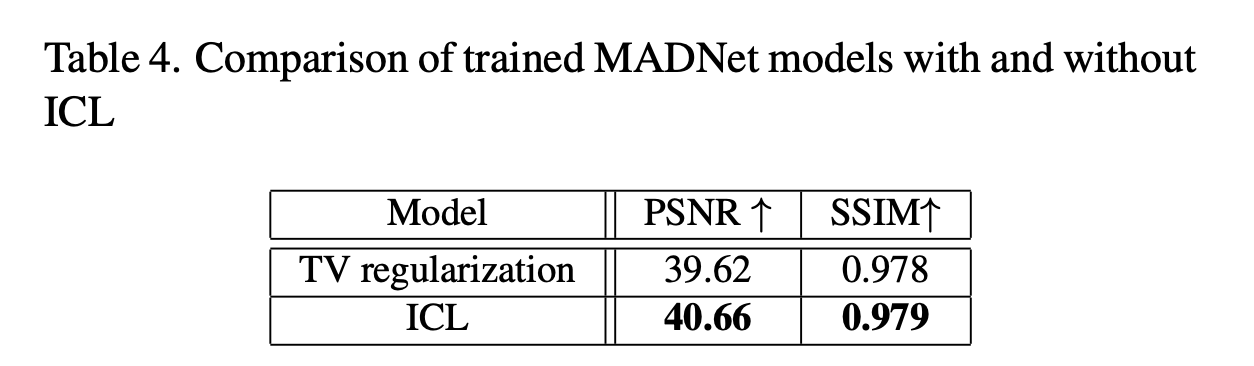
在我们的实验中,我们选择全变分系数(α_{TV})等于相邻系数(α_{neighbor})。需要注意的是,全变分损失(L_{TV})和相邻通道间损失(L_{neighbor}^{ICL})非常相似,全变分损失(L_{TV})完全是基于预测值(\hat{Y})进行计算的,而相邻通道间损失(L_{neighbor}^{ICL})则同时使用了真实值(Y)和预测值(\hat{Y})。客观结果展示在表4中。从该表中可以明显看出,与全变分正则化相比,通道间损失((LICL))能获得更高的峰值信噪比((PSNR))和结构相似性指数((SSIM))值。图8中的视觉对比也表明,与通道间损失((LICL))相比,全变分正则化生成的图像更平滑,但细节表现欠佳。

通道分组的影响
在本实验中,我们分析了2.1节中提出的通道分组机制。我们通过使用另外两种编码变化方式来训练MADNet,以此研究我们的通道分组所产生的影响:(a)无分组——在这种情况下,如图2 - a所示,输入的四拜耳图像未经修改就被直接输入网络;(b)16通道分组——这是图2 - c所展示的传统分组机制。这两种方法都比较直观,其中(a)方法产生的输入图像不存在空间下采样,且隐含层特征尺寸较大;而(b)方法产生的输入图像存在空间下采样,且隐含层特征尺寸较小。结果展示在表5和图9中。尽管(a)方法能获得最佳的图像质量,然而其代价是处理时间大幅增加。另一方面,16通道分组的速度最快,但正如在图9中所见,它会导致混叠伪影。在我们看来,所提出的4通道分组在图像质量和处理时间之间实现了较好的权衡。 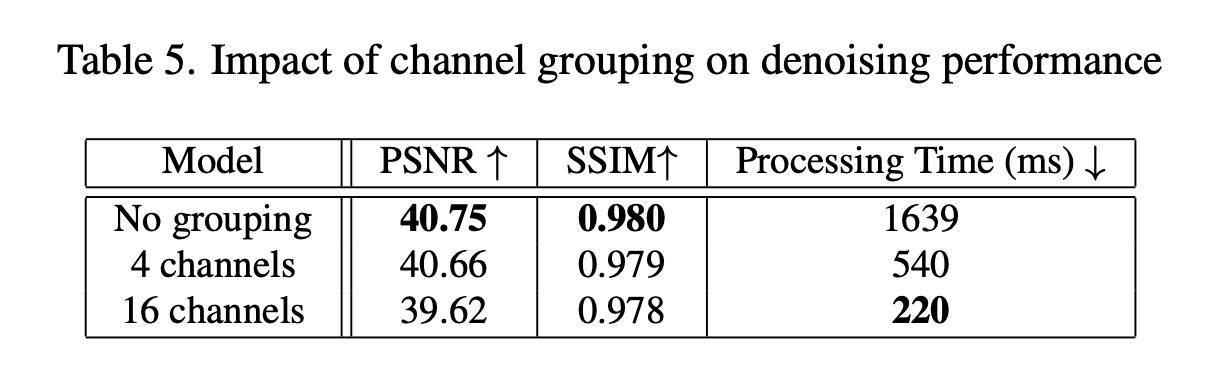

4. 结论
在本文中,我们提出了一个基于深度神经网络的框架,用于对近来流行的四拜耳原始图像进行去噪。我们在训练去噪网络时着重强调轻量化以及在智能手机上运行的能力,同时要保留图像中的细节。所提出的模型在训练过程中采用了一种新颖的通道分组机制以及一个新的通道间损失函数。此外,我们使用了一个包含总共5752对含噪 - 参考图像对的四拜耳数据集。这个四拜耳数据集是首个此类数据集,它包含长曝光和短曝光图像的组合,以捕捉广泛的噪声特性。我们对重建后的图像质量进行了全面评估,结果表明我们所提出的模型在峰值信噪比(PSNR)和结构相似性指数(SSIM)等客观指标以及视觉质量方面均优于当前最先进的方法。我们还开展了一系列消融实验,以分析通道分组和通道间损失函数的重要性。