LSQ+: Improving low-bit quantization through learnable offsets and better initializationn解读
Published:
论文、代码和ppt地址:LSQ+。代码地址: LSQplus
本文通过paper解读和代码的分析,来说明LSQ+算法。
Abstract
与ReLU不同,在流行的高效架构中经常使用的较新的激活函数(如Swish、H-swish、Mish)也可能产生负激活值,其正负取值范围是不对称的。典型的可学习量化方案[5, 7]对激活值采用无符号量化,并将所有负激活值量化为零,这会导致性能的重大损失。简单地使用有符号量化来容纳这些负激活值需要额外的符号位,对于低位(2位、3位、4位)量化来说成本很高。为解决这一问题,我们提出了LSQ+,它是LSQ[7]的自然扩展,在其中我们引入了一种通用的非对称量化方案,该方案带有可训练的缩放和偏移参数,能够学习适应负激活值。基于梯度的可学习量化方案通常还存在最终训练性能高度不稳定或差异较大的问题,因此需要大量的超参数调整才能达到令人满意的性能。LSQ+通过对量化参数采用基于均方误差(MSE)的初始化方案缓解了这一问题。我们表明,这种初始化方式使得多次训练运行中最终性能的差异显著降低。总体而言,LSQ+在EfficientNet和MixNet上展现出了最先进的结果,并且对于带有Swish激活函数的神经网络的低位量化(例如:在ImageNet数据集上对EfficientNet-B0进行W4A4量化时性能提升1.8%,进行W2A2量化时性能提升高达5.6%),LSQ+的表现也显著优于LSQ。据我们所知,我们的工作是首个将此类架构量化到极低比特宽度的研究。
1. Introduction
随着深度神经网络在各种应用场景中的广泛应用,如今人们对能让深度网络在资源受限的边缘设备上高效运行的方法的需求日益增长。这些方法包括模型剪枝、神经架构搜索(NAS)以及由新颖架构模块(例如深度可分离卷积、分组卷积、squeezeexcite blocks等)构建的手工打造的高效网络。最后,我们还可以进行模型量化,即将权重和激活值量化到更低的位宽,从而实现高效的定点推理并减少内存带宽的使用。
由于通过神经架构搜索发现了更多高效架构,更新、更通用的激活函数(如Swish [22]、H-swish [11]、Leaky-ReLU)正在取代传统的ReLU。与ReLU不同,这些激活函数也会取到零以下的值。当前诸如PACT [5]和LSQ [7]这样的最先进的量化方案在对激活值进行量化时假定采用无符号量化范围,所有小于零的激活值都会通过量化为零而被舍弃。这对于像ResNet [10]这样基于传统ReLU的架构效果很好,但当应用于采用Swish激活函数的现代架构(如EfficientNet [26]和MixNet [27])时,会导致大量信息丢失。例如,LSQ对预激活的ResNet50进行W4A4量化时能保证准确率无损失,但在将EfficientNet-B0量化到W4A4时,准确率会下降4.1%。简单地采用有符号量化范围来容纳这些负值同样会导致性能下降。
为了缓解在极低位(2位、3位、4位)量化中常见的这些性能下降问题,我们提议采用一种通用的非对称量化方案,该方案带有可学习的偏移参数以及可学习的缩放参数。我们表明,所提出的量化方案能针对不同层以不同方式学习适应负激活值,并恢复LSQ所造成的准确率损失,例如,在对EfficientNet - B0进行W4A4量化时,比LSQ的准确率提高了1.8%,在进行W2A2量化时,准确率提高多达5.6%。据我们所知,我们的工作是首个将诸如EfficientNet和MixNet这样的现代架构量化到极低位宽的研究。
任何基于梯度的可学习量化方案尤其面临的另一个问题是其对初始化的敏感性,这意味着不佳的初始化可能导致在多次训练运行中最终性能存在较大差异。这个问题在min-max初始化([1]中使用的方法)中尤为明显。我们表明,对偏移和缩放参数采用基于均方误差(MSE)最小化[24, 25]的初始化方案,相较于min-max量化,能使最终性能的稳定性显著提高。我们还将这种初始化方案与[7]中提出的方案进行了对比。
总之,我们提出的名为LSQ+的方法扩展了LSQ [7],通过为激活值量化添加一个简单却有效的可学习偏移参数,来恢复在采用类Swish激活函数的架构上损失的准确率。此外,我们的另一贡献在于揭示了适当初始化对于稳定训练的重要性,尤其是在低位量化的情况下。
2. 相关工作
文献[16]对量化基础知识进行了很好的概述,其中解释了非对称量化和对称量化之间的差异。一般来说,我们可以将量化方法分为无需微调即可工作的训练后量化方法,以及需要微调的量化感知训练方法。
训练后量化方法[2, 31, 6]在不进行完整训练且仅使用少量数据的情况下针对量化对神经网络进行优化。[20, 4]在完全不使用任何数据的情况下能将这一点做得更好。尽管这些方法在典型的8位量化上效果良好,但它们在极低比特(2位、3位、4位)量化时无法达到良好的准确率。
在给定足够优化时间的情况下,量化感知训练方法在低位任务上通常优于这些方法。文献[9, 12, 17]讨论了模拟量化感知训练方法及其改进措施。从本质上讲,是在神经网络计算图中添加了一些操作,用以模拟在实际设备上如何进行量化。近期的一些论文通过学习量化参数对这些方法进行了改进,例如QIL [14]、TQT [13]以及LSQ [7]。这正是我们在论文中所基于的方法,不过我们提出的类似非对称量化方案及初始化方法可用于任何其他方法。
在并行的研究方向上,一些研究工作[15, 18, 21]试图将知识蒸馏应用于量化,从而提升了性能。此外,近期也有一些工作[28]致力于自动学习位宽以及取值范围。请注意,我们提出的方法与这些工作是相互正交的,因此可以与它们联合使用。最后,有几篇论文引入了与我们所使用的均匀量化网格不同的量化网格。在[19]和[29]中,分别使用对数空间或完全自由格式的量化空间来对网络进行量化。在本文中,我们不考虑这种情况,因为针对这些的硬件实现效率极低,在运行时需要成本高昂的查找表或近似计算。
3. 方法
在LSQ[7]中,针对权重和激活值都提出了一种带有可训练缩放参数的对称量化方案。该方案定义如下: 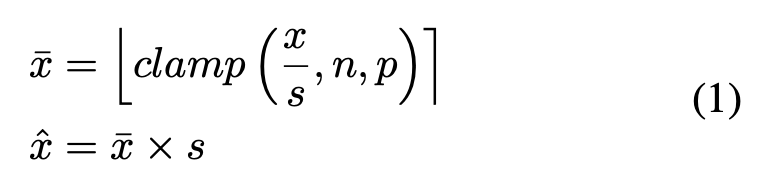
其中,⌊·⌉表示取整函数,而clamp(·)函数会将所有值限定在n和p之间。¯x和ˆx分别表示编码位和量化值。
LSQ可以使用有符号或无符号的量化范围。然而,对于像Swish或Leaky-ReLU这样正负取值范围不对称的激活函数来说,这两种方式都不是最优的。使用无符号量化范围,即n = 0,p = 2^b − 1,会将所有负激活值限定为零,从而导致大量信息丢失。相反,使用有符号量化范围,即n = −2^{b−1},p = 2^{b−1} − 1,会将所有负激活值量化到[−2^{b−1},0]范围内的整数,将所有正激活值量化到[0,2^{b−1} − 1]范围内,因此会对激活函数的正负部分给予同等的重视程度。不过,对于正动态范围明显大于负动态范围的不对称分布情况,这样会损失宝贵的精度。在第4.1节中,我们将展示在对带有Swish激活函数的架构进行量化时,这两种量化方案都会导致准确率的显著下降。
所提出的方法LSQ+通过一种更通用的可学习的非对称激活量化方案解决了上述问题,该方案将在第3.1节中进行描述。第3.2节描述了LSQ+中所使用的初始化方案。
3.1 可学习的非对称量化
作为上述问题的一种解决方案,我们提出了一种通用的非对称激活量化方案,在该方案中,不仅缩放参数,而且偏移参数都会在训练期间进行学习,以应对不对称的激活值分布情况。 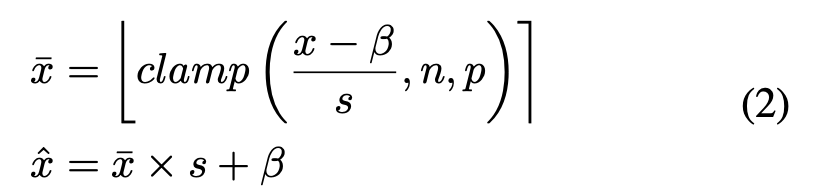
在此处,偏移参数β和缩放参数s都是可学习的。参数s的梯度更新是通过以下方式计算的: 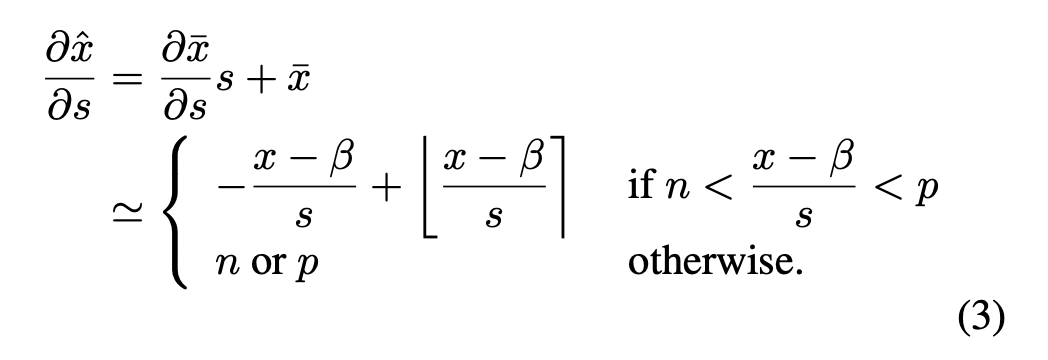
而β的梯度更新是通过以下方式计算的: 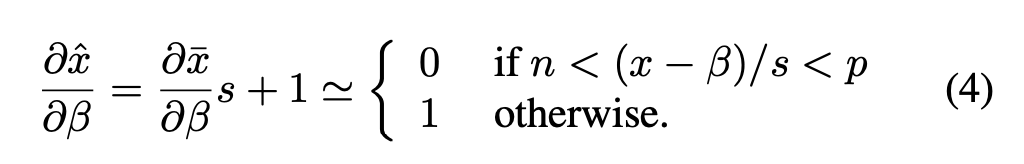
在公式(3)和(4)中,直通估计器(STE)[3]都被用于近似计算∂¯x/∂s以及∂¯x/∂β。
对于权重量化,我们采用对称有符号量化(公式(1)),因为从经验上可以观察到层权重是以零为中心对称分布的。正因如此,与对称量化相比,激活值的非对称量化在推理过程中不会产生额外成本,这是因为额外的偏移项可以在编译时预先计算并合并到偏差中。 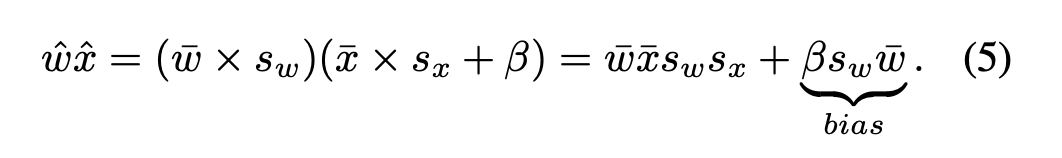
表1展示了针对公式(2)中所提出量化方案的四种可能的参数化设置。配置1和配置2未使用偏移参数,因此遵循了LSQ[7]中所提出的可学习对称量化方案。由于配置1在这种对称量化方案下使用的是无符号范围,它与LSQ中针对激活值量化所提出的参数化设置完全一致。配置3和配置4针对激活值量化同时学习缩放参数和偏移参数,二者唯一的区别在于有符号和无符号量化范围。我们将在实验部分对这些不同的参数化设置进行分析。

3.2 量化参数的初始化
随着我们使用基于梯度的可学习量化方法进入极低比特宽度的情况,训练后的最终性能对量化超参数的初始化变得高度敏感。在存在深度可分离卷积(已知其量化具有挑战性[30])的情况下,这种敏感性问题会被放大。在这项工作中,我们提出了一种针对缩放参数和偏移参数的初始化方案,与文献[12, 7]中提出的其他初始化方案(在保持量化配置不变的情况下)相比,该方案能实现更稳定且有时性能更佳的效果。
3.2.1 权重量化的scale初始化
如前文所述,在我们的方法中,对于权重采用有符号对称量化(与配置2类似)。因此,在权重量化时不使用偏移量。
LSQ[7]建议使用层权重的平方根归一化平均绝对值,即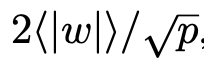 ,来初始化缩放参数。这会导致在进行2位、3位或4位量化时得到一个非常大的初始值,例如在4位量化的情况下,初始缩放参数
,来初始化缩放参数。这会导致在进行2位、3位或4位量化时得到一个非常大的初始值,例如在4位量化的情况下,初始缩放参数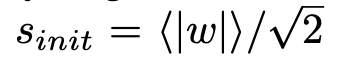 。从我们的实验来看,发现这种初始化方式得到的值与缩放参数的收敛值相差甚远。图1展示了这种现象的一个实例。
。从我们的实验来看,发现这种初始化方式得到的值与缩放参数的收敛值相差甚远。图1展示了这种现象的一个实例。 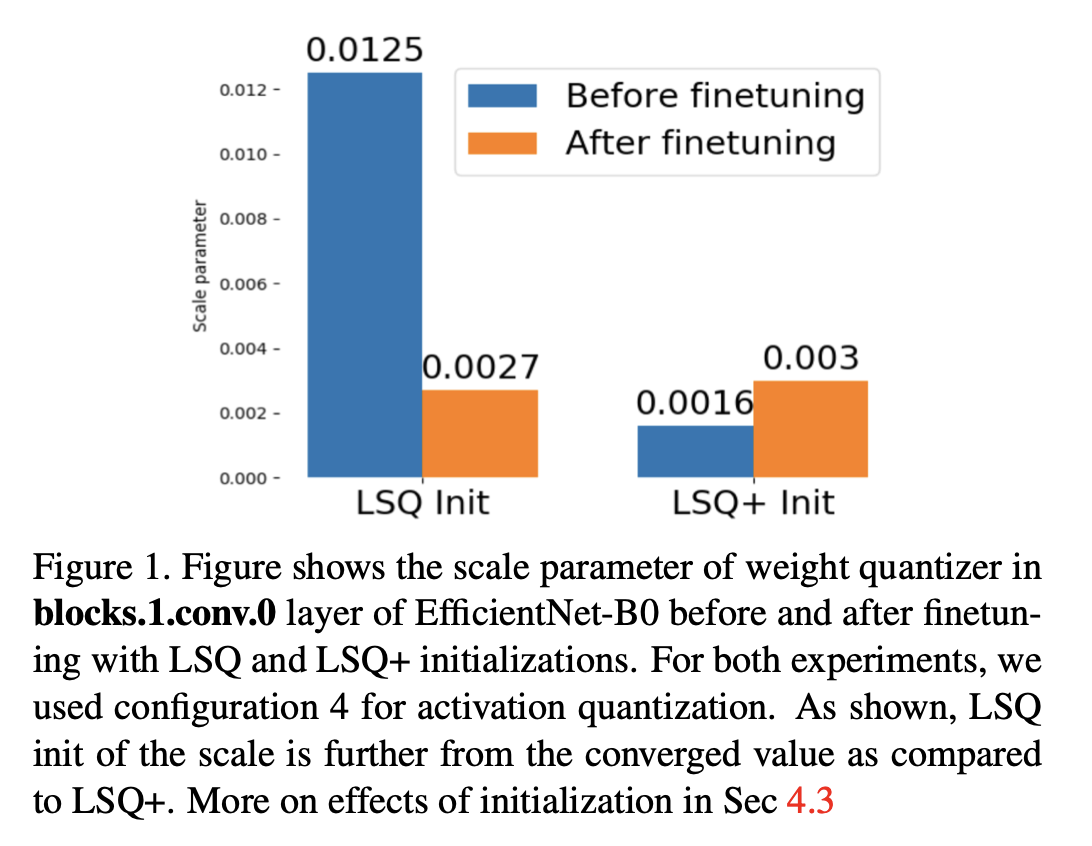 图1. 该图展示了在使用LSQ和LSQ+初始化方式进行微调前后,EfficientNet - B0的blocks.1.conv.0层中权重量化器的缩放参数。在这两项实验中,我们针对激活值量化都采用了配置4。如图所示,与LSQ+相比,LSQ对缩放参数的初始化值距离收敛值更远。有关初始化的影响详见第4.3节。
图1. 该图展示了在使用LSQ和LSQ+初始化方式进行微调前后,EfficientNet - B0的blocks.1.conv.0层中权重量化器的缩放参数。在这两项实验中,我们针对激活值量化都采用了配置4。如图所示,与LSQ+相比,LSQ对缩放参数的初始化值距离收敛值更远。有关初始化的影响详见第4.3节。
我们通过使用权重分布的统计信息而非实际权重值来进行初始化,从而解决了这个问题。与文献[20]类似,我们对每一层的权重分布采用高斯近似。在此基础上,我们通过以下方式为每一层初始化缩放参数: 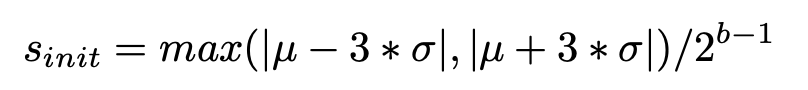
其中,(\mu)和(\sigma)分别是该层权重的均值(等同于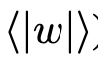 )和标准差。
)和标准差。
3.2.2 激活量化的scale/offset初始化
令x_{min}和x_{max}分别表示激活函数的最小值和最大值。例如,对于ReLU来说,x_{min} = 0;而对于Swish激活函数而言,x_{min} = -0.278 。直观地讲,当x_{min}被量化到量化范围的下限,且x_{max}被量化到量化范围的上限时,就能实现对量化范围的充分利用。遵循这一直观思路,(s)和(\beta)的初始化应满足:
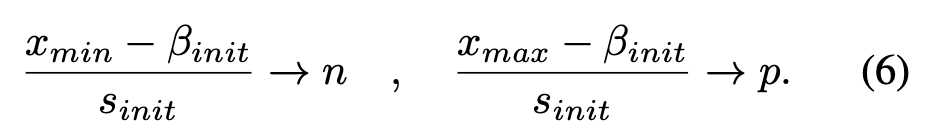
求解这些约束条件可得:
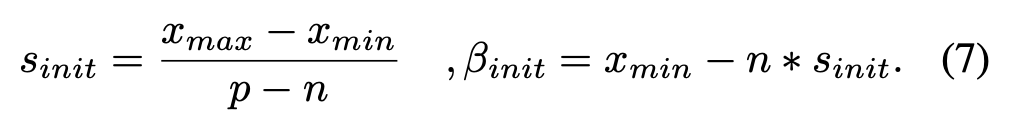
但上述初始化方式极易受到激活值分布中的异常值影响,尤其是在激活值范围是动态的情况下。为克服这一问题,我们提议通过优化均方误差(MSE)最小化问题,按每层来初始化缩放参数和偏移参数,这与文献[24, 25]中的做法类似。
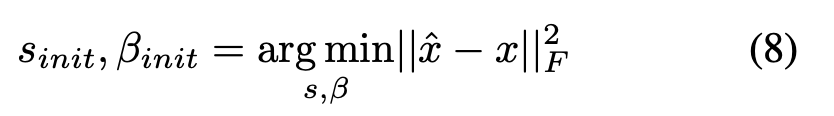
其中,hat{x}由公式(2)给出。公式(8)没有闭式解。因此,我们将公式(3)和(4)嵌入到PyTorch的自动求导功能中,以便利用几批数据对{s_{init}, beta_{init}进行优化。
4 实验
我们通过将带有Swish激活函数的架构量化到W2A2、W3A3和W4A4的方式来评估我们所提方法的有效性。据我们所知,我们的工作是首个将此类架构量化到极低比特宽度的研究。作为合理性检验,我们展示了LSQ+在带有ReLU激活函数的传统架构上也能维持LSQ [7]的性能表现。最后,我们展示了使用不同初始化方式对所提量化方法性能的影响。所有实验均在ImageNet [23]数据集上进行。
在所有配置以及所有实验中,权重参数均使用深度网络预训练的浮点权重进行初始化。尽管我们会在第4.3节比较不同初始化方式对缩放/偏移参数的有效性,但在第4.1节和第4.2节的实验中,我们使用的是第3.2节所提出的初始化方式。
4.1 Swish激活函数的结果
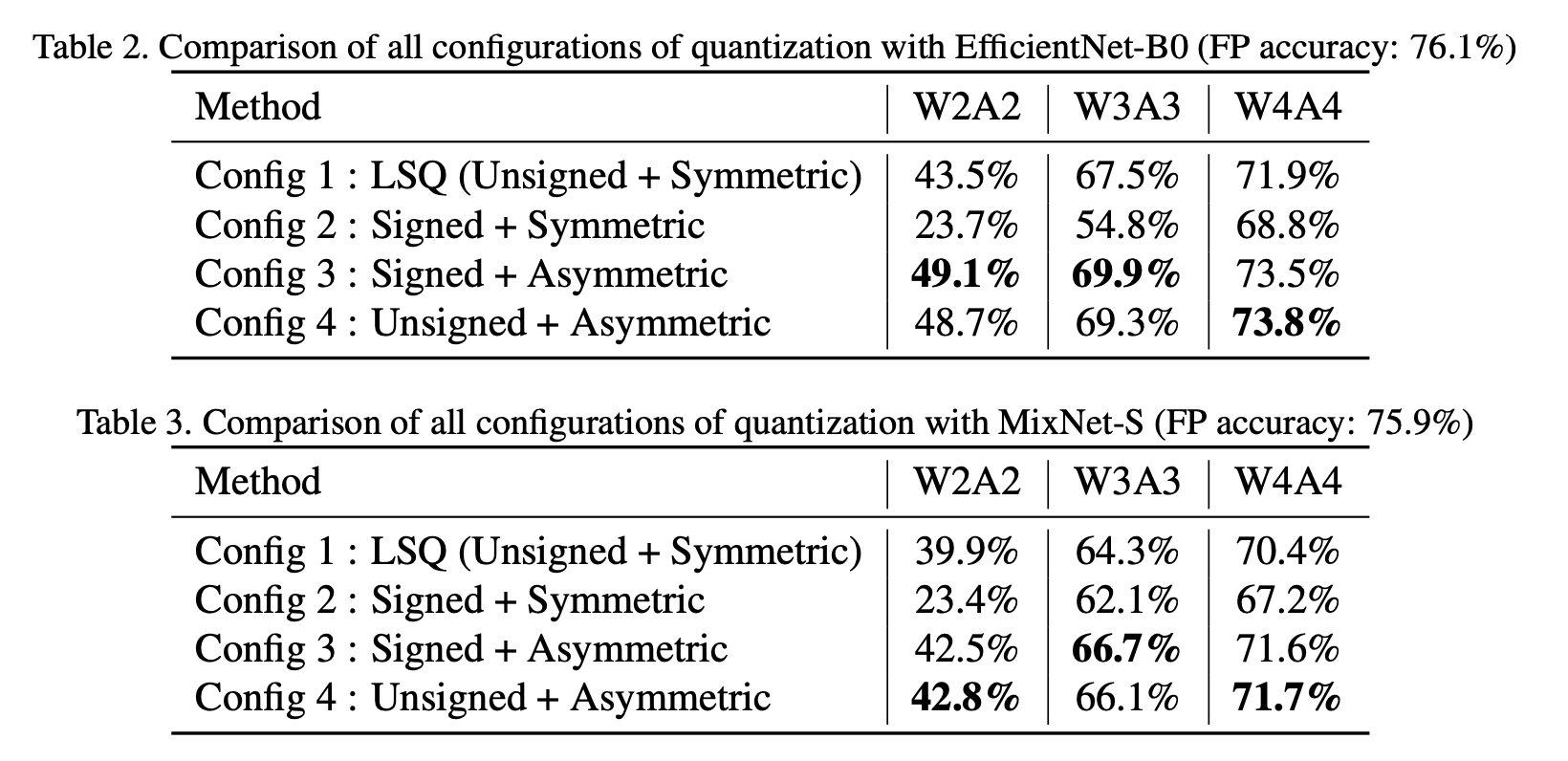
表2和表3分别展示了所提方法的所有配置对EfficientNet - B0 [26]和MixNet - S [27]进行量化时对性能产生的影响。MixNet - S在前3层使用ReLU激活函数,在其余层使用Swish激活函数。通过使用可学习的偏移参数,我们观察到在对EfficientNet - B0和MixNet - S进行W4A4量化时,性能分别提升了1.6 - 1.8%和1.2 - 1.3%(对比配置1(即LSQ)来看配置3和配置4)。使用我们提出的可学习非对称量化方案所带来的这种性能提升在W2A2量化的情况下最为显著。
对于所有位宽,配置3(有符号范围 + 可学习偏移量)和配置4(无符号范围 + 可学习偏移量)的性能几乎相同。这是因为,由于我们学习了偏移参数,无论量化范围是有符号的还是无符号的,激活值范围都能被恰当地映射到量化范围上。
另一个有趣的观察结果是,配置2的性能始终比其他所有配置都差。这是因为,由于缺少偏移参数,激活值范围的正部分仅能利用2^{b - 1}个量化级别,而如第3节所述,Swish激活函数的正部分要比负部分大得多。因此,与为整个激活值范围分配2^{b}个量化级别的配置3和配置4相比,配置2对其量化范围的利用率很低,从而导致性能更差。
4.2 ReLU激活函数的结果
LSQ论文[7]中展示的关于ResNet的结果使用的是ResNet架构的预激活版本[10],该版本在ImageNet数据集上的top - 1准确率比标准ResNet要高出约0.4 - 0.6%。因此,为了能与其他最先进的方法进行公平比较,我们在标准ResNet上运行了我们自己实现的LSQ(配置1)以及所有其他配置。表4展示了所提方法的所有配置在ResNet18上的量化性能。我们实现的LSQ(配置1)在进行W4A4量化时能够达到70.7%的准确率,这一准确率高于其全精度下70.1%的准确率。这是一项合理性检验,证明了我们的LSQ结果与原始LSQ论文[7]中的结果相当。此外,配置1、配置3和配置4的性能优于现有的最先进方法,即PACT[5]、DSQ[8]和QIL[14]。值得注意的是,与EfficientNet和MixNet不同,在对ResNet18进行量化时,配置1、配置3和配置4之间几乎不存在性能差距。我们将此归因于ReLU激活函数没有负向部分这一事实。 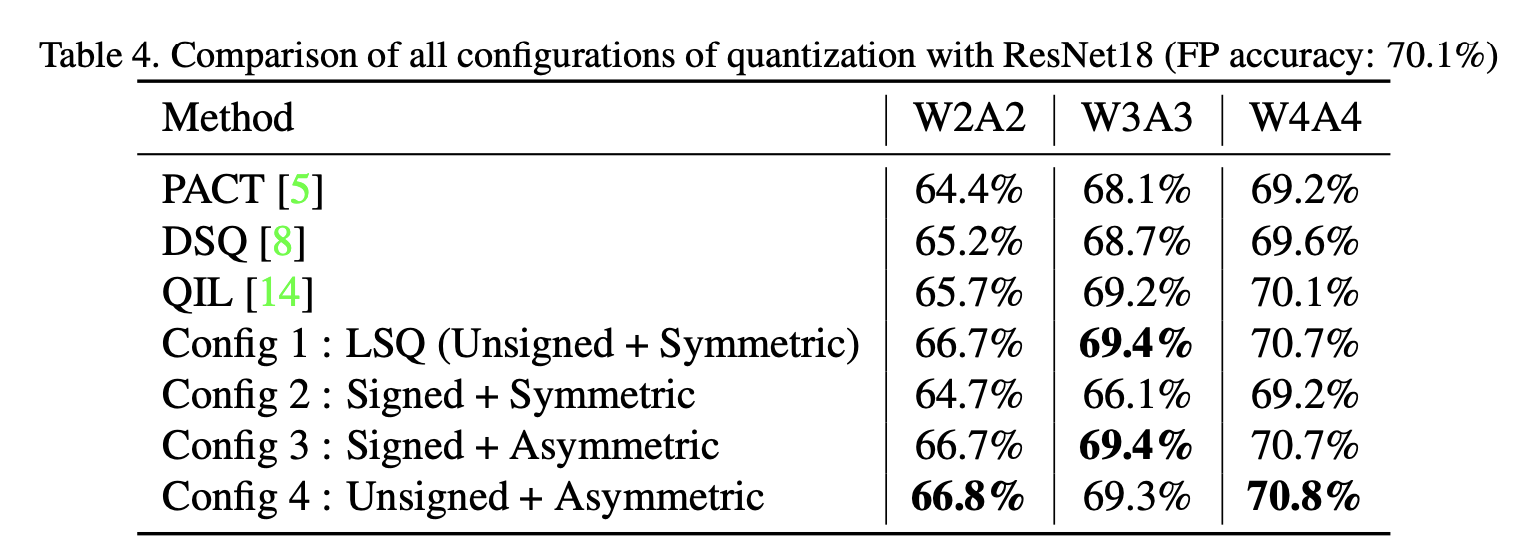
4.3 量化参数初始化的影响
在本节中,我们对三种用于初始化量化缩放参数和偏移参数的方案进行比较。由于我们对权重采用对称量化,所以在权重量化时不使用偏移量。此外,针对激活值量化的配置1和配置2也不使用偏移量。所比较的三种初始化方法如下:
min-max初始化。我们利用每层权重和激活值(通过第一批输入图像获取)的最小值和最大值来初始化量化缩放参数和偏移参数。这种初始化方案在公式(7)中有相应表述。
LSQ初始化。权重量化和激活值量化的缩放参数都初始化为
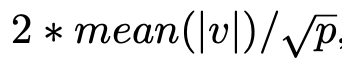 ,其中v表示层权重或激活值,p是量化范围的上限。
,其中v表示层权重或激活值,p是量化范围的上限。LSQ+ 初始化。我们按照第3.2节所提出的方法来初始化权重量化和激活值量化的参数。
在实验中,我们使用配置4对EfficientNet - B0进行量化,并针对每种初始化方法进行多次训练。表5展示了使用每种初始化方法进行5次训练后最终性能的变化量((\Delta acc))。我们可以观察到,在进行W2A2量化时最终性能具有高度的不稳定性,尤其是采用min-max量化时更是如此。这是因为在进行2位量化时,权重或激活值分布的尾部很容易影响缩放参数的初始化。LSQ初始化方法使用平方根归一化平均绝对值来初始化权重量化的缩放参数,其训练性能也具有较高的变化性。这是因为LSQ初始化会导致(s_{init})的值较大,且如图1所示,该值与收敛值相差甚远。
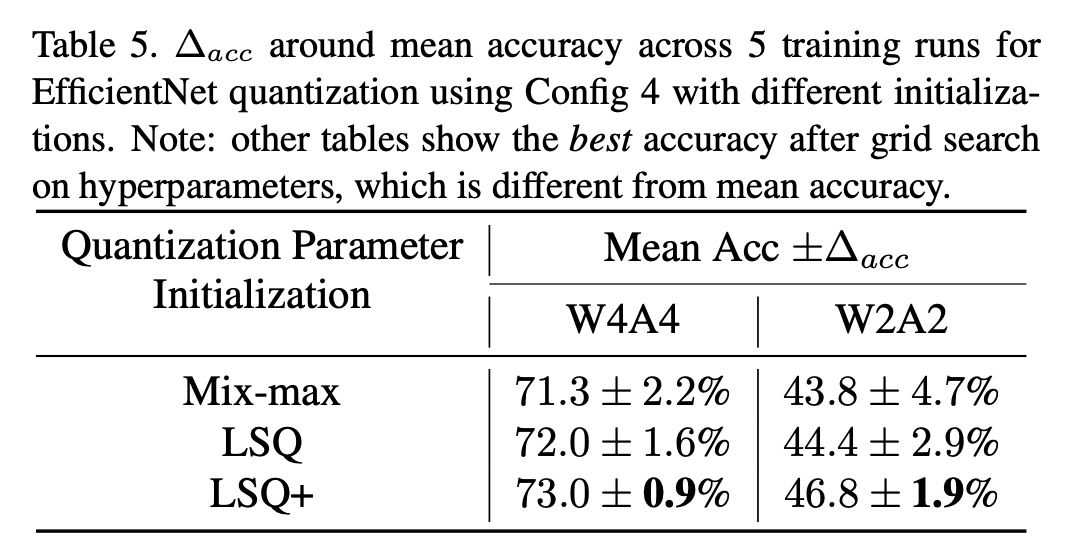 表5. 使用配置4并采用不同初始化方式对EfficientNet进行量化时,5次训练运行所得平均准确率周围的准确率变化量(∆acc)。注:其他表格展示的是在超参数上进行网格搜索后得到的最佳准确率,这与平均准确率有所不同。
表5. 使用配置4并采用不同初始化方式对EfficientNet进行量化时,5次训练运行所得平均准确率周围的准确率变化量(∆acc)。注:其他表格展示的是在超参数上进行网格搜索后得到的最佳准确率,这与平均准确率有所不同。
5 讨论
5.1 可学习的offset
观察网络学习到的逐层偏移值是一件很有意思的事。图2展示了这样一个示例,即针对EfficientNet - B0采用配置4进行W4A4量化的情况。需要注意的是,在对squeeze-excite层进行量化时不使用偏移量,因为Sigmoid激活函数没有负向部分。此外,在EfficientNet的瓶颈模块末尾并没有应用激活操作,因此对于那些激活层我们采用对称有符号量化。这些层在图中并未展示出来。
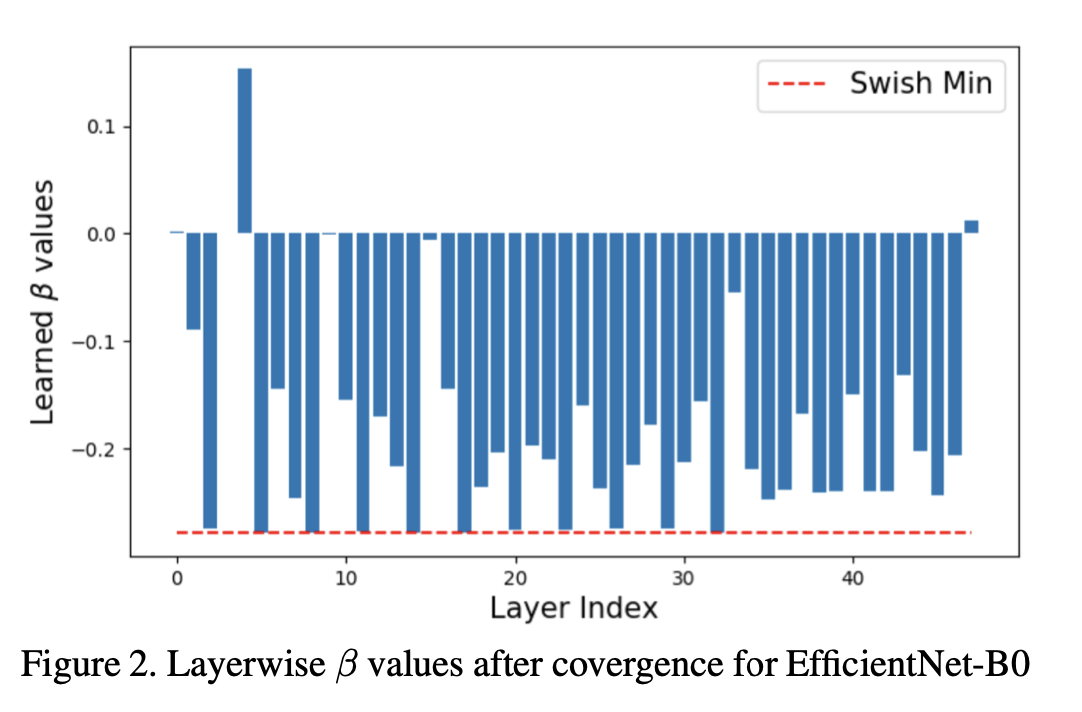
我们可以观察到,大多数β值都是负的,这意味着在激活值进行缩放并被限制在量化范围之间之前,它们会被“向上”平移。这表明量化层学会了适应负向激活值。所学习到的β值没有一个低于Swish激活函数的最小值(红色虚线所示)。因为,根据公式(4)
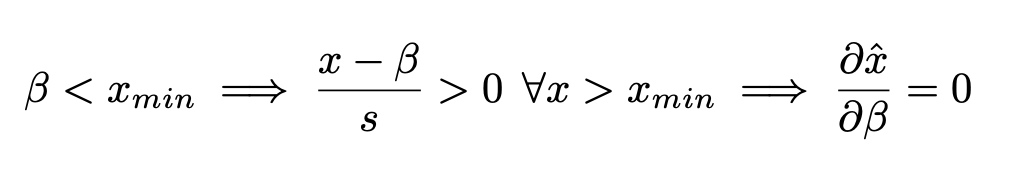
因此,一旦β < xmin,β的梯度就变为零。
5.2 可学习的 vs 固定的 offset
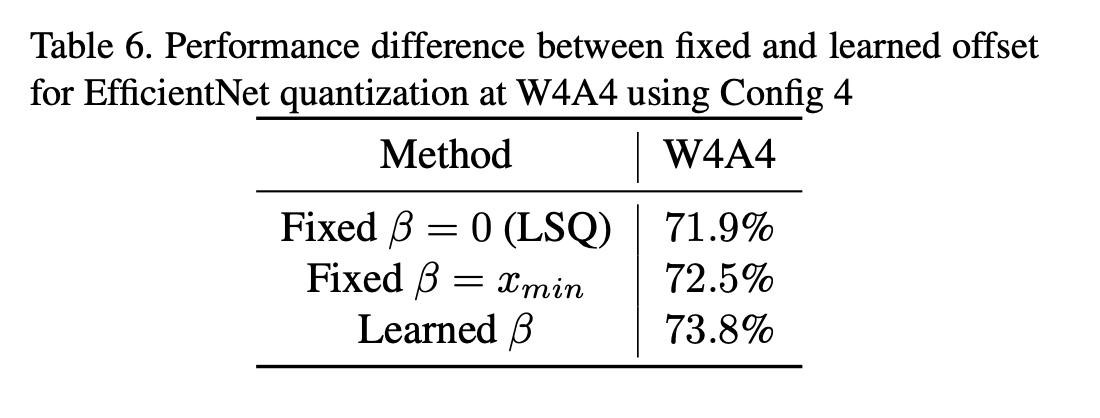
进一步观察图2可以发现,大多数层学习到的偏移量都偏离了Swish激活函数的最小值。这是因为,如果我们试图使用量化网格(参考公式(6))来表示整个激活值范围,由于比特数是固定的,这会导致表示较为粗糙,从而产生更高的量化误差。学习(s)和(\beta)值的目的在于权衡量化网格的分辨率以及由量化网格所表示的激活值范围占比这两者之间的关系。因此,学习到的(\beta)值并不完全等于激活函数的最小值。但人们可能会好奇,当每层的(\beta)都固定为(x_{min})时所能达到的性能情况。表6展示了固定偏移量方法和可学习偏移量方法在性能上的差异。
6. 总结
在这项工作中,针对低比特量化领域,我们解决了两个问题:(1)对带有有符号激活函数的深度神经网络进行量化;(2)量化训练性能的稳定性问题。为此,我们提出了一种通用的非对称量化方案,该方案带有可训练的缩放参数和偏移参数,能够在不使用额外符号位的情况下学会适应负向激活值。在公式(5)中,我们表明针对激活值使用这种非对称量化在运行时不会产生额外开销。我们的工作率先将诸如EfficientNet和MixNet这类现代高效架构量化到极低比特位。我们展示了LSQ+显著提升了这些架构在2位、3位和4位量化时的性能。我们针对基于ReLU的传统ResNet18架构所做的实验表明,我们可以在各处用LSQ+替代LSQ,且不会影响性能。最后,我们表明针对激活值量化参数使用基于均方误差最小化的初始化方案能使性能更加稳定,这对于低比特量化感知训练而言非常重要。