HRNet,Deep High-Resolution Representation Learning for Visual Recognition解读
Published:
本文通过paper解读和代码实例以及onnx模型的分析,来说明hrnet模型。
摘要——高分辨率表征对于诸如人体姿态估计、语义分割和目标检测等对位置敏感的视觉问题至关重要。现有的最先进框架首先通过一个子网(该子网由高低分辨率卷积串联而成,例如ResNet、VGGNet)将输入图像编码为低分辨率表征,然后再从编码后的低分辨率表征中恢复高分辨率表征。与之不同的是,我们所提出的名为高分辨率网络(HRNet)的网络在整个过程中都维持着高分辨率表征。它有两个关键特性:(i)并行连接高低分辨率卷积流;(ii)跨分辨率反复交换信息。这样做的好处是,最终得到的表征在语义上更加丰富,在空间上也更加精确。我们展示了所提出的高分辨率网络(HRNet)在众多应用中的优势,包括人体姿态估计、语义分割和目标检测,这表明HRNet是解决计算机视觉问题的一个更强大的骨干网络。所有代码均可在https://github.com/HRNet获取。
1. INTRODUCTION
深度卷积神经网络(DCNNs)在许多计算机视觉任务中取得了最先进的成果,如图像分类、目标检测、语义分割、人体姿态估计等等。其优势在于,深度卷积神经网络能够学习到比传统手工特征表示更丰富的表征。
大多数近期开发的分类网络,包括AlexNet[77]、VGGNet[126]、GoogleNet[133]、ResNet[54]等等,都遵循LeNet-5[81]的设计规则。该规则如图1(a)所示:逐步减小特征图的空间尺寸,将从高分辨率到低分辨率的卷积依次串联起来,进而得到一个低分辨率表征,该表征会被进一步处理用于分类。
对于位置敏感型任务,例如语义分割、人体姿态估计和目标检测,高分辨率表征是必需的。先前的最先进方法采用高分辨率恢复流程,以便将分类网络或类似分类网络输出的低分辨率表征的分辨率提高,如图1(b)所示,例如Hourglass[105]、SegNet[3]、DeconvNet[107]、U-Net[119]、SimpleBaseline[152]以及编码器 - 解码器[112]。此外,扩张卷积被用于去除一些下采样层,从而生成中等分辨率表征[19]、[181]。
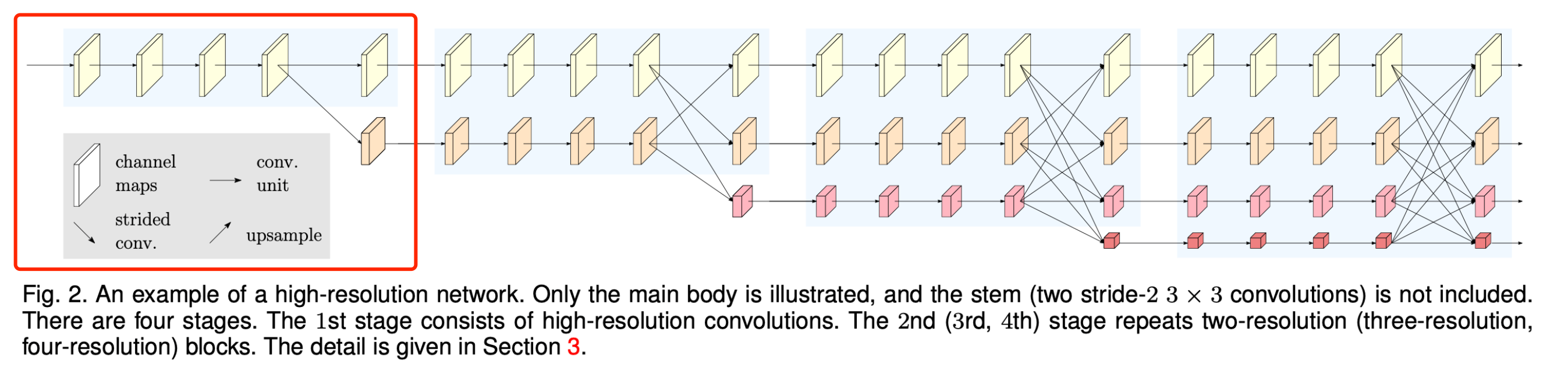
我们提出了一种新颖的架构,即高分辨率网络(HRNet),它能够在整个过程中维持高分辨率表征。我们从一个高分辨率卷积流开始,逐步逐个添加从高到低分辨率的卷积流,并并行连接多分辨率流。最终的网络由几个(本文中为4个)阶段组成,如图2所示,第n个阶段包含对应n个分辨率的n个流。我们通过反复在并行流之间交换信息来进行多次多分辨率融合。
从高分辨率网络(HRNet)学习到的高分辨率表征不仅语义丰富,而且在空间上也很精确。这体现在两个方面。(i)我们的方法并行连接从高到低分辨率的卷积流,而非串联。因此,我们的方法能够维持高分辨率,而不是从低分辨率恢复高分辨率,相应地,学习到的表征在空间上可能更加精确。(ii)大多数现有的融合方案是对上采样低分辨率表征所获得的高分辨率低级表征和高级表征进行聚合。与之不同的是,我们反复进行多分辨率融合,借助低分辨率表征来增强高分辨率表征,反之亦然。结果就是,所有从高到低分辨率的表征在语义上都很强。
我们提出了高分辨率网络(HRNet)的两个版本。第一个版本,名为HRNetV1,仅输出从高分辨率卷积流计算得到的高分辨率表征。我们按照热图估计框架将其应用于人体姿态估计。我们通过实验证明了它在COCO关键点检测数据集[94]上卓越的姿态估计性能。
另一个版本,名为HRNetV2,它合并了来自所有从高到低分辨率并行流的表征。我们通过从合并后的高分辨率表征估计分割图,将其应用于语义分割。所提出的方法在PASCAL-Context、Cityscapes和LIP数据集上,以相近的模型尺寸和更低的计算复杂度取得了最先进的成果。我们发现在COCO姿态估计任务中,HRNetV1和HRNetV2有着相近的性能,而在语义分割方面,HRNetV2优于HRNetV1。
此外,我们从HRNetV2输出的高分辨率表征构建了一个多级表征,名为HRNetV2p,并将其应用于最先进的检测框架,包括Faster R-CNN、Cascade R-CNN[12]、FCOS[136]和CenterNet[36],以及最先进的联合检测和实例分割框架,包括Mask R-CNN[53]、Cascade Mask R-CNN和Hybrid Task Cascade[16]。结果表明,我们的方法提升了检测性能,尤其对小物体的检测性能有显著提升。
 图1. 从低分辨率恢复高分辨率的结构。(a)一个低分辨率表征学习子网(例如VGGNet[126]、ResNet[54]),它是通过将高分辨率到低分辨率的卷积依次串联而形成的。(b)一个高分辨率表征恢复子网,它是通过将低分辨率到高分辨率的卷积依次串联而形成的。具有代表性的示例包括SegNet[3]、DeconvNet[107]、U-Net[119]、Hourglass[105]、编码器 - 解码器[112]以及SimpleBaseline[152]。
图1. 从低分辨率恢复高分辨率的结构。(a)一个低分辨率表征学习子网(例如VGGNet[126]、ResNet[54]),它是通过将高分辨率到低分辨率的卷积依次串联而形成的。(b)一个高分辨率表征恢复子网,它是通过将低分辨率到高分辨率的卷积依次串联而形成的。具有代表性的示例包括SegNet[3]、DeconvNet[107]、U-Net[119]、Hourglass[105]、编码器 - 解码器[112]以及SimpleBaseline[152]。
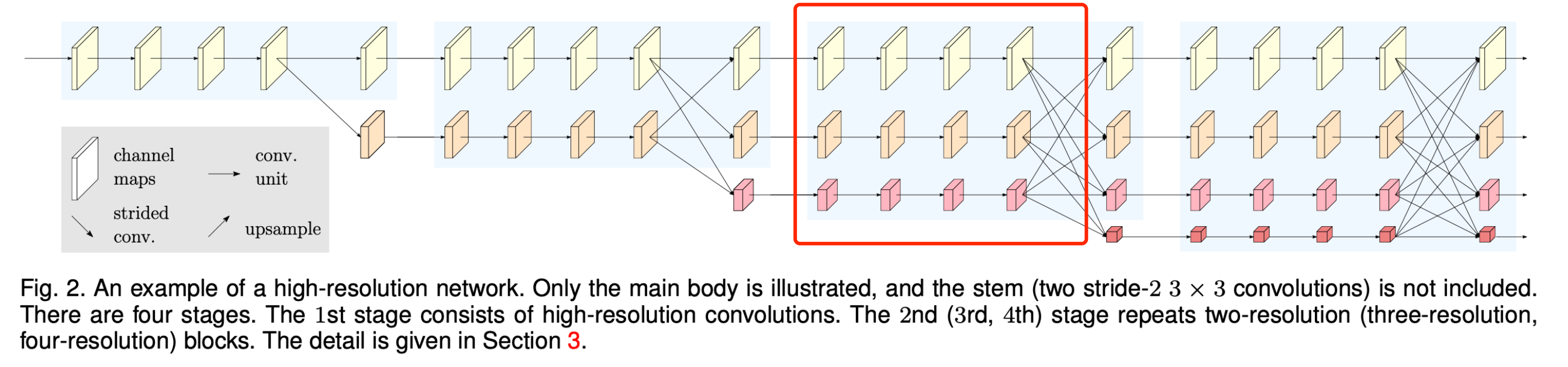
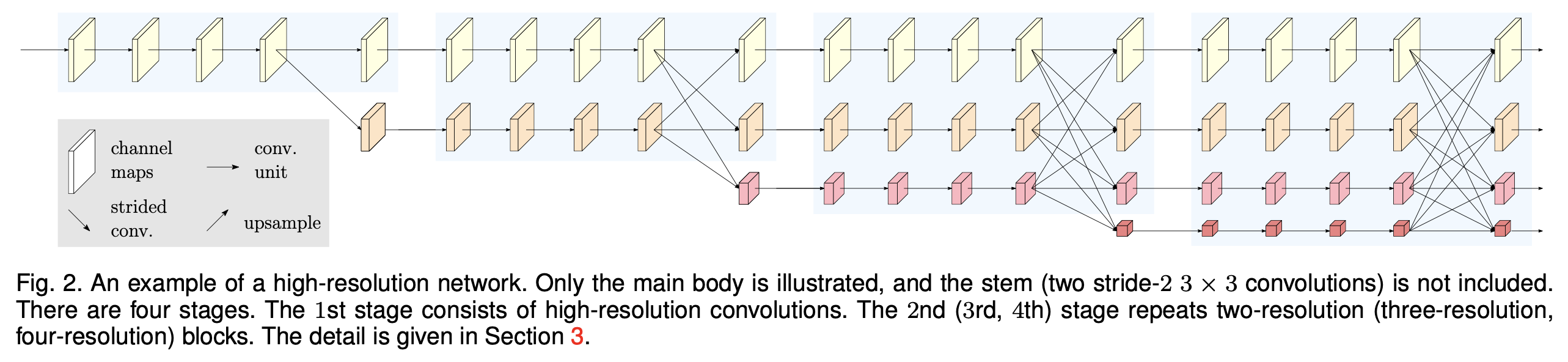 图2. 高分辨率网络的一个示例。这里仅展示了主体部分,未包含主干部分(两个步长为2的3×3卷积)。 该网络包含四个阶段。第一阶段由高分辨率卷积组成。第二(第三、第四)阶段会重复使用二分辨率(三分辨率、四分辨率)模块。详细内容见第3节。
图2. 高分辨率网络的一个示例。这里仅展示了主体部分,未包含主干部分(两个步长为2的3×3卷积)。 该网络包含四个阶段。第一阶段由高分辨率卷积组成。第二(第三、第四)阶段会重复使用二分辨率(三分辨率、四分辨率)模块。详细内容见第3节。
2. 相关工作
我们从三个方面详细回顾了主要为人体姿态估计[57]、语义分割和目标检测而开发的密切相关的表征学习技术,这三个方面分别是:低分辨率表征学习、高分辨率表征恢复以及高分辨率表征维持。此外,我们还提及了一些与多尺度融合相关的工作。
学习低分辨率表征: 全卷积网络方法[99]、[124]通过移除分类网络中的全连接层来计算低分辨率表征,并估计其粗略的分割图。通过结合从中间低层级中等分辨率表征估计出的精细分割得分图[99],或者对相关过程进行迭代[76],可以对估计出的分割图进行改进。类似的技术也已应用于边缘检测,例如整体边缘检测[157]。
全卷积网络通过将少数(通常为两个)步长卷积以及相关卷积替换为扩张卷积,扩展为扩张版本,从而产生中等分辨率表征[18]、[19]、[86]、[168]、[181]。这些表征通过特征金字塔进一步扩充为多尺度上下文表征[19]、[21]、[181],以便对多尺度的目标进行分割。
恢复高分辨率表征: 可以使用上采样过程从低分辨率表征逐步恢复高分辨率表征。上采样子网络可以是下采样过程(例如VGGNet)的对称版本,通过在一些镜像层上设置跳跃连接来转换池化索引,例如SegNet[3]和DeconvNet[107];或者是复制特征图,例如U-Net[119]、Hourglass[8]、[9]、[27]、[31]、[68]、[105]、[134]、[163]、[165]、编码器 - 解码器[112]等等。U-Net的一个扩展——全分辨率残差网络[114]引入了一个额外的全分辨率流,该流承载全图像分辨率下的信息,用于替代跳跃连接,并且下采样和上采样子网络中的每个单元都从全分辨率流接收信息并向其发送信息。
非对称上采样过程也得到了广泛研究。RefineNet[90]改进了上采样表征与从下采样过程中复制的相同分辨率表征的组合方式。其他相关工作包括:轻量级上采样过程[7]、[24]、[92]、[152],可能会在骨干网络中使用扩张卷积[63]、[89]、[113];轻量级下采样和重量级上采样过程[141]、重组器网络[55];使用更多或更复杂的卷积单元改进跳跃连接[64]、[111]、[180],以及将信息从低分辨率跳跃连接发送到高分辨率跳跃连接[189]或在它们之间交换信息[49];研究上采样过程的细节[147];组合多尺度金字塔表征[22]、[154];堆叠多个DeconvNets/U-Nets/Hourglass[44]、[149]并带有密集连接[135]。
维持高分辨率表征: 我们的工作与一些同样能够生成高分辨率表征的工作密切相关,例如卷积神经结构[123]、互联卷积神经网络[188]、GridNet[42]以及多尺度密集网络[58]。
早期的两项工作,卷积神经结构[123]和互联卷积神经网络[188],在何时开始低分辨率并行流以及如何、在何处跨并行流交换信息方面缺乏精心设计,并且没有使用批量归一化和残差连接,因此未能展现出令人满意的性能。GridNet[42]就像是多个U-Net的组合,它包含两个对称的信息交换阶段:第一阶段仅将信息从高分辨率传递到低分辨率,第二阶段仅将信息从低分辨率传递到高分辨率。这限制了它的分割质量。多尺度密集网络[58]由于无法从低分辨率表征接收信息,所以无法学习到强大的高分辨率表征。
多尺度融合: 多尺度融合受到了广泛研究[11]、[19]、[24]、[42]、[58]、[66]、[122]、[123]、[157]、[161]、[181]、[188]。一种直接的方法是将多分辨率图像分别输入到多个网络中,然后聚合输出的响应图[137]。Hourglass[105]、U-Net[119]和SegNet[3]通过跳跃连接,在从高到低的下采样过程中将低级特征逐步合并到从低到高的上采样过程中的相同分辨率高级特征中。PSPNet[181]和DeepLabV2/3[19]融合了由金字塔池化模块和空洞空间金字塔池化所获得的金字塔特征。我们的多尺度(分辨率)融合模块与这两个池化模块类似。不同之处在于:(1)我们的融合输出的是四种分辨率的表征,而不只是一种;(2)我们的融合模块受深度融合[129]、[143]、[155]、[178]、[184]的启发会重复多次。
我们的方法: 我们的网络并行连接从高到低的卷积流。它在整个过程中维持高分辨率表征,并通过反复融合来自多分辨率流的表征,生成具有强位置敏感性的可靠高分辨率表征。
本文是对我们之前会议论文[130]的一次重大扩展,补充了我们未发表的技术报告[131]中的额外内容,以及在近期开发的最先进的目标检测和实例分割框架下更多的目标检测结果。与[130]相比,主要的技术创新体现在三个方面。(1)我们将[130]中提出的网络(名为HRNetV1)扩展为两个版本:HRNetV2和HRNetV2p,这两个版本探索了全部四种分辨率表征。(2)我们建立了多尺度融合与常规卷积之间的联系,这为在HRNetV2和HRNetV2p中探索全部四种分辨率表征的必要性提供了依据。(3)我们展示了HRNetV2和HRNetV2p相对于HRNetV1的优势,并呈现了HRNetV2和HRNetV2p在包括语义分割和目标检测在内的众多视觉问题中的应用。
3. HIGH-RESOLUTION Networks
我们将图像输入到一个主干部分,该主干部分由两个步长为2的3×3卷积组成,它会将图像分辨率降低至原来的1/4,随后图像会进入主体部分,主体部分输出的表征具有相同的分辨率(即1/4)。主体部分(如图2所示,详细内容如下所述)由几个组件构成:并行多分辨率卷积、重复多分辨率融合以及如图4所示的表征头。
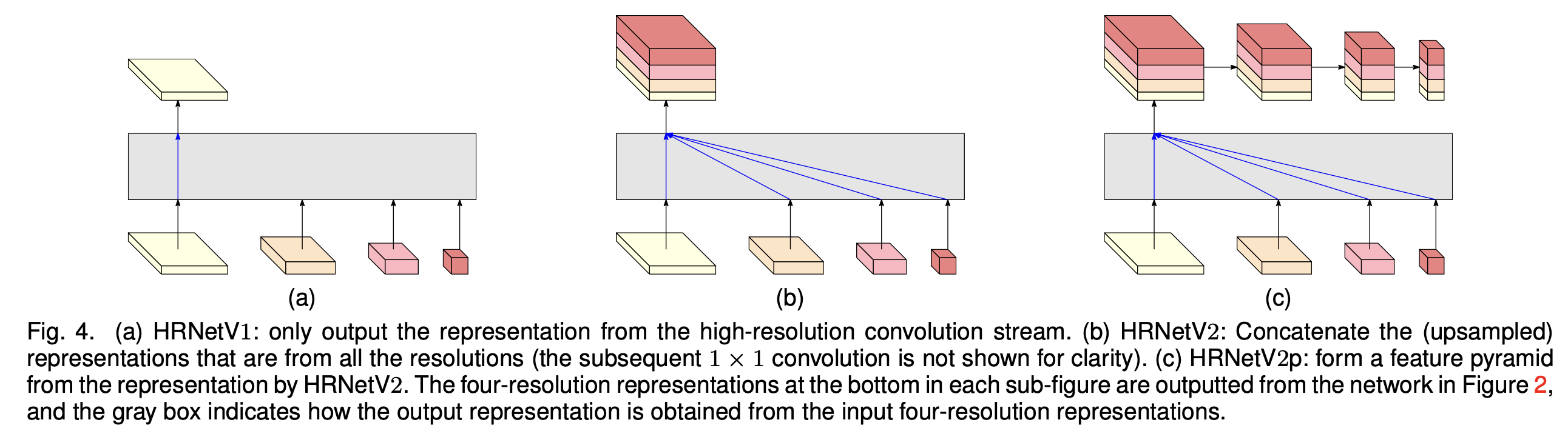 图4. (a)HRNetV1:仅输出来自高分辨率卷积流的表征。(b)HRNetV2:将来自所有分辨率的(上采样后的)表征进行拼接(为清晰起见,后续的1×1卷积未展示)。(c)HRNetV2p:利用HRNetV2输出的表征构建一个特征金字塔。每个子图底部的四种分辨率表征是由图2所示网络输出的,灰色框展示了如何从输入的四种分辨率表征中获取输出表征。
图4. (a)HRNetV1:仅输出来自高分辨率卷积流的表征。(b)HRNetV2:将来自所有分辨率的(上采样后的)表征进行拼接(为清晰起见,后续的1×1卷积未展示)。(c)HRNetV2p:利用HRNetV2输出的表征构建一个特征金字塔。每个子图底部的四种分辨率表征是由图2所示网络输出的,灰色框展示了如何从输入的四种分辨率表征中获取输出表征。
3.1. Parallel Multi-Resolution Convolutions
我们从作为第一阶段的高分辨率卷积流开始,逐步逐个添加从高到低分辨率的流,从而形成新的阶段,并并行连接多分辨率流。这样一来,后续阶段并行流的分辨率就包含了前一阶段的分辨率,以及一个额外更低的分辨率。
图2所示的示例网络结构包含4个并行流,其逻辑如下, 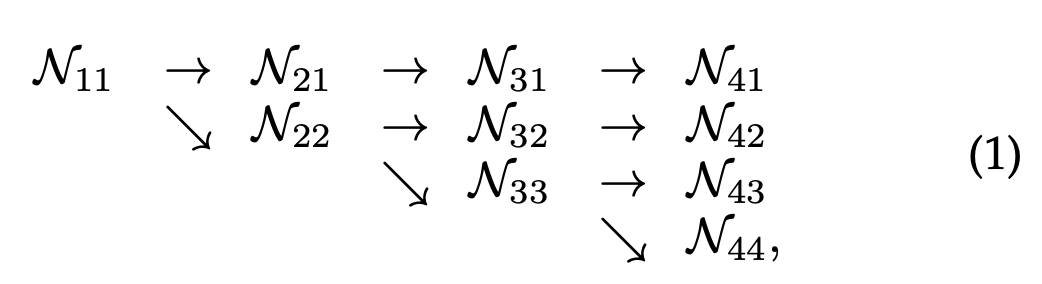
其中N_sr表示第s阶段中的子流,r为分辨率索引。第一个流的分辨率索引r = 1。索引r对应的分辨率是第一个流分辨率的1 / (2^{r-1})
3.2. Repeated Multi-Resolution Fusions
融合模块的目标是在多分辨率表征之间交换信息。它会被重复多次(例如,每4个残差单元重复一次)。
让我们来看一个融合3种分辨率表征的示例,如图3所示。融合2种以及4种表征的情况可以很容易由此推导出来。输入包含三种表征: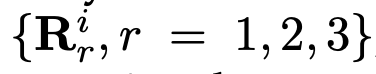 ,其中r为分辨率索引,与之相关的输出表征为
,其中r为分辨率索引,与之相关的输出表征为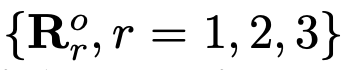 。每个输出表征都是对三个输入表征进行变换后相加的结果,即
。每个输出表征都是对三个输入表征进行变换后相加的结果,即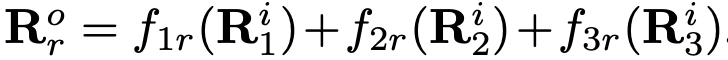 。跨阶段(从第3阶段到第4阶段)的融合会有一个额外输出:
。跨阶段(从第3阶段到第4阶段)的融合会有一个额外输出: 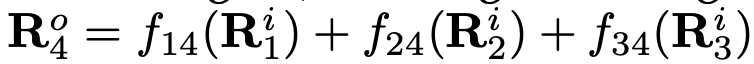
变换函数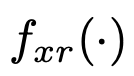 的选择取决于输入分辨率索引x和输出分辨率索引r。如果x = r,那么
的选择取决于输入分辨率索引x和输出分辨率索引r。如果x = r,那么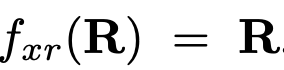 。如果x < r,
。如果x < r,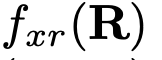 会通过(r - s)个步长为2的3×3卷积对输入表征R进行下采样。例如,进行2倍下采样时使用一个步长为2的3×3卷积,进行4倍下采样时使用两个连续的步长为2的3×3卷积。如果x > r,会先通过双线性上采样对输入表征R进行上采样,然后使用一个1×1卷积来对齐通道数量。这些函数如图3所示。
会通过(r - s)个步长为2的3×3卷积对输入表征R进行下采样。例如,进行2倍下采样时使用一个步长为2的3×3卷积,进行4倍下采样时使用两个连续的步长为2的3×3卷积。如果x > r,会先通过双线性上采样对输入表征R进行上采样,然后使用一个1×1卷积来对齐通道数量。这些函数如图3所示。
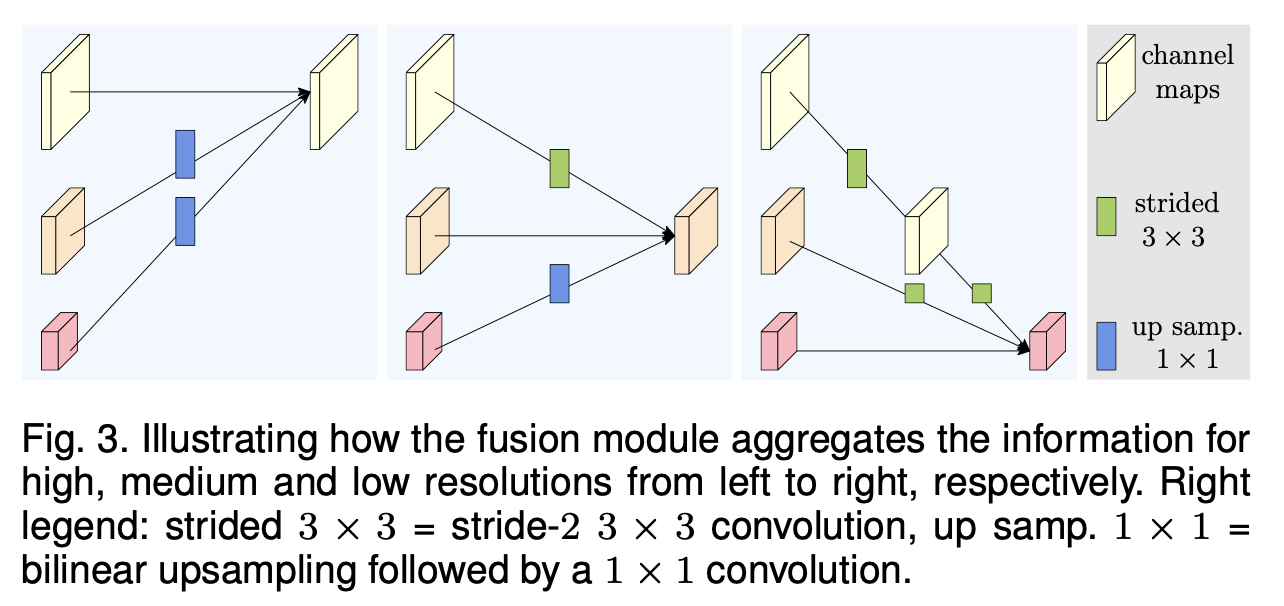 图3. 展示融合模块如何分别从左至右聚合高、中、低分辨率的信息。右侧图例:步长为2的3×3 = 步长为2的3×3卷积,上采样1×1 = 双线性上采样后接一个1×1卷积。
图3. 展示融合模块如何分别从左至右聚合高、中、低分辨率的信息。右侧图例:步长为2的3×3 = 步长为2的3×3卷积,上采样1×1 = 双线性上采样后接一个1×1卷积。
3.3 表征头 Representation Head
我们有三种表征头,如图4所示,分别将它们称作HRNetV1、HRNetV2和HRNetV2p。
HRNetV1:输出仅来自高分辨率流的表征,其他三种表征会被忽略。这在图4(a)中有展示。
HRNetV2:我们通过双线性上采样将低分辨率表征重新缩放到高分辨率(通道数量保持不变),然后将这四种表征进行拼接,接着使用一个1×1卷积来混合这四种表征。这在图4(b)中有展示。
HRNetV2p:我们通过将HRNetV2输出的高分辨率表征下采样到多个层级来构建多级表征。这在图4(c)中有展示。
在本文中,我们将展示把HRNetV1应用于人体姿态估计、把HRNetV2应用于语义分割以及把HRNetV2p应用于目标检测的相关结果。
3.4 Instantiation 具体描述
主体部分包含四个阶段,每个阶段有四个并行的卷积流。其分辨率分别为1/4、1/8、1/16和1/32。
第一阶段包含4个残差单元,每个单元由一个宽度为64的瓶颈结构组成,随后紧跟一个3×3卷积,该卷积会将特征图的宽度变为C。第二、第三、第四阶段分别包含1个、4个、3个模块化块。模块化块的多分辨率并行卷积中的每个分支都包含4个残差单元。每个单元针对每个分辨率都包含两个3×3卷积,且每个卷积之后都会进行批量归一化以及非线性激活ReLU操作。这四种分辨率的卷积的宽度(通道数量)分别为C、2C、4C和8C。示例见图2。
3.5 分析
我们对模块化块进行分析,它可分为两个组件:多分辨率并行卷积(图5(a))以及多分辨率融合(图5(b))。
多分辨率并行卷积与分组卷积类似。它将输入通道划分为若干个通道子集,并针对每个子集在不同的空间分辨率下分别执行常规卷积,而在分组卷积中,分辨率是相同的。这种关联意味着多分辨率并行卷积具备分组卷积的一些优势。
多分辨率融合单元与常规卷积的多分支全连接形式相似,如图5(c)所示。正如[178]中所解释的那样,一个常规卷积可以拆分为多个小卷积。输入通道被划分为若干个子集,输出通道同样也被划分为若干个子集。输入和输出子集以全连接的方式相连,并且每条连接都是常规卷积。输出通道的每个子集是对输入通道每个子集上卷积输出结果的求和。不同之处在于,我们的多分辨率融合需要处理分辨率的变化。多分辨率融合与常规卷积之间的联系为在HRNetV2和HRNetV2p中探索全部四种分辨率表征提供了依据。
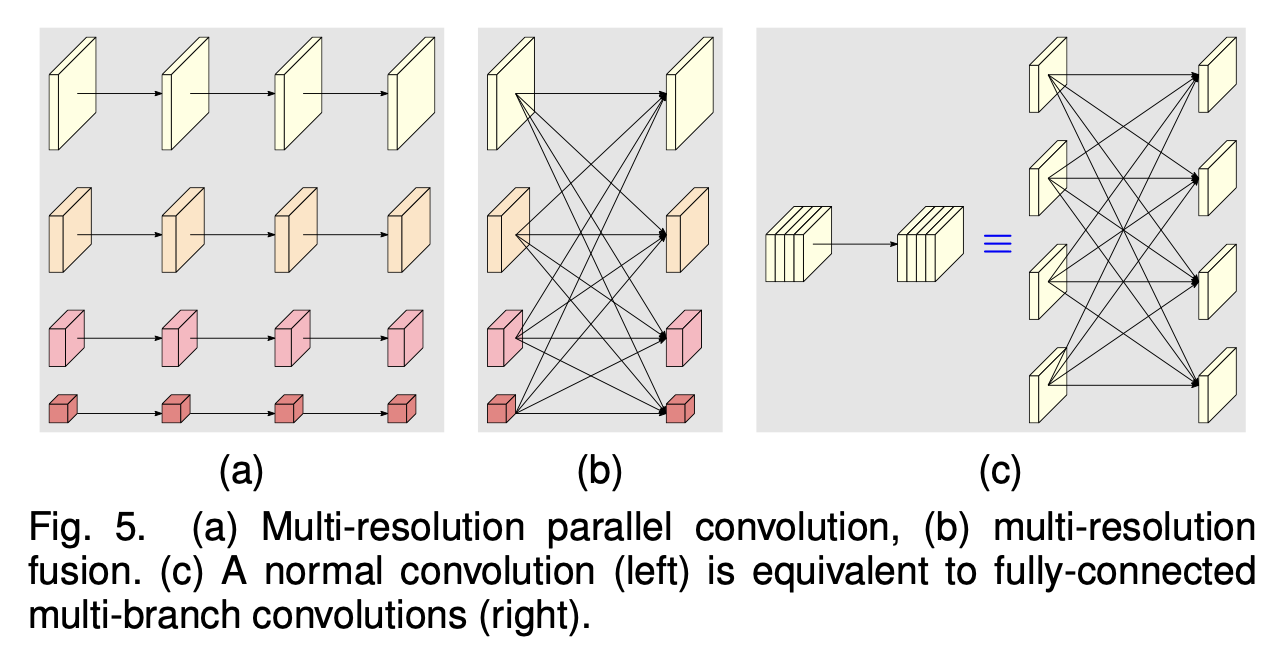 图5. (a)多分辨率并行卷积,(b)多分辨率融合。(c)一个常规卷积(左图)等同于全连接多分支卷积(右图)。
图5. (a)多分辨率并行卷积,(b)多分辨率融合。(c)一个常规卷积(左图)等同于全连接多分支卷积(右图)。
4. HUMAN POSE ESTIMATION
人体姿态估计,又称关键点检测,旨在从尺寸为宽(W)×高(H)×3的图像I中检测出K个关键点或身体部位(例如肘部、腕部等)的位置。我们遵循最先进的框架,将这个问题转化为估计尺寸为W/4×H/4的K个热图{H1, H2, …, HK},其中每个热图Hk表示第k个关键点的位置置信度。
我们基于HRNetV1输出的高分辨率表征来回归热图。我们通过实验观察到,HRNetV1和HRNetV2的性能几乎相同,因此我们选择HRNetV1,因为它的计算复杂度稍低一些。损失函数定义为均方误差,用于比较预测热图和真实热图。真实热图是通过以每个关键点的真实位置为中心、标准差为2像素的二维高斯函数生成的。一些示例结果见图6。
数据集:COCO数据集[94]包含超过20万张图像以及25万个标注了17个关键点的人物实例。我们在COCO的train2017集(包含5.7万张图像和15万个人物实例)上训练我们的模型,并在val2017集(包含5000张图像)和test-dev2017集(包含2万张图像)上评估我们的方法。
评估指标:标准评估指标基于目标关键点相似度(OKS):OKS = ∑i exp(−d²i / 2s²k²i )δ(vi > 0) / ∑i δ(vi > 0)。这里di是检测到的关键点与对应的真实位置之间的欧几里得距离,vi是真实位置的可见性标志,s是目标尺度,ki是控制衰减的每个关键点的常数。我们报告标准平均精度和召回率得分:AP50(OKS = 0.50时的平均精度)、AP75、AP(在10个OKS取值位置(0.50、0.55、…、0.90、0.95)上的平均精度得分的平均值);APM(针对中等尺寸目标)、APL(针对大型目标)以及AR(在10个OKS取值位置(0.50、0.55、…、0.90、0.95)上的平均召回率得分的平均值)。
训练:我们将人体检测框在高度或宽度方向上扩展到固定的宽高比(高度 : 宽度 = 4 : 3),然后从图像中裁剪出该检测框,并将其调整为固定尺寸(256×192或384×288)。数据增强方案包括随机旋转(范围在[−45°,45°])、随机缩放(范围在[0.65,1.35])以及翻转。依照[146],还涉及半身数据增强。
我们使用Adam优化器[71]。学习计划遵循[152]中的设置。基础学习率设置为1e−3,在第170个和第200个训练周期时分别降至1e−4和1e−5。训练过程在210个周期内结束。模型在4块V100 GPU上进行训练,HRNet-W32(HRNet-W48)的训练耗时大约为60(80)小时。
测试:采用与[24]、[109]、[152]类似的两阶段自上而下的范式:先用人物检测器检测人物实例,然后预测检测关键点。
我们对val集和test-dev集都使用SimpleBaseline³提供的相同人物检测器。依照[24]、[105]、[152],我们通过对原始图像和翻转图像的热图取平均值来计算热图。每个关键点位置通过在从最高响应到次高响应的方向上以四分之一偏移量来调整最高热值位置进行预测。
val集上的结果:我们在表1中报告了我们的方法以及其他最先进方法的结果。网络——HRNetV1-W32,以256×192的输入尺寸从头开始训练,获得了73.4的平均精度(AP)得分,优于具有相同输入尺寸的其他方法。(i)与Hourglass [105]相比,我们的网络将平均精度提高了6.5个百分点,并且我们网络的浮点运算次数(GFLOP)低得多,还不到其一半,而参数数量相似,我们的略多一点。(ii)与无OHKM和有OHKM的CPN [24]相比,我们的网络(模型尺寸稍大且复杂度稍高一点)分别获得了4.8和4.0个百分点的提升。(iii)与之前性能最佳的方法SimpleBaseline [152]相比,我们的HRNetV1-W32取得了显著改进:对于具有相似模型尺寸和浮点运算次数的ResNet-50骨干网络,提升了3.0个百分点;对于模型尺寸(参数数量)和浮点运算次数是我们两倍的ResNet-152骨干网络,提升了1.4个百分点。
我们的网络可以受益于:(i)使用在ImageNet上预训练的模型进行训练:对于HRNetV1-W32,提升了1.0个百分点;(ii)通过增加宽度来提升容量:HRNetV1-W48在输入尺寸为256×192和384×288时分别获得了0.7和0.5个百分点的提升。
考虑输入尺寸为384×288的情况,我们的HRNetV1-W32和HRNetV1-W48分别获得了75.8和76.3的平均精度,相较于输入尺寸为256×192时,分别有1.4和1.2的提升。与以ResNet-152作为骨干网络的SimpleBaseline [152]相比,我们的HRNetV1-W32和HRNetV1-W48在平均精度方面分别以45%和92.4%的计算成本获得了1.5和2.0个百分点的提升。
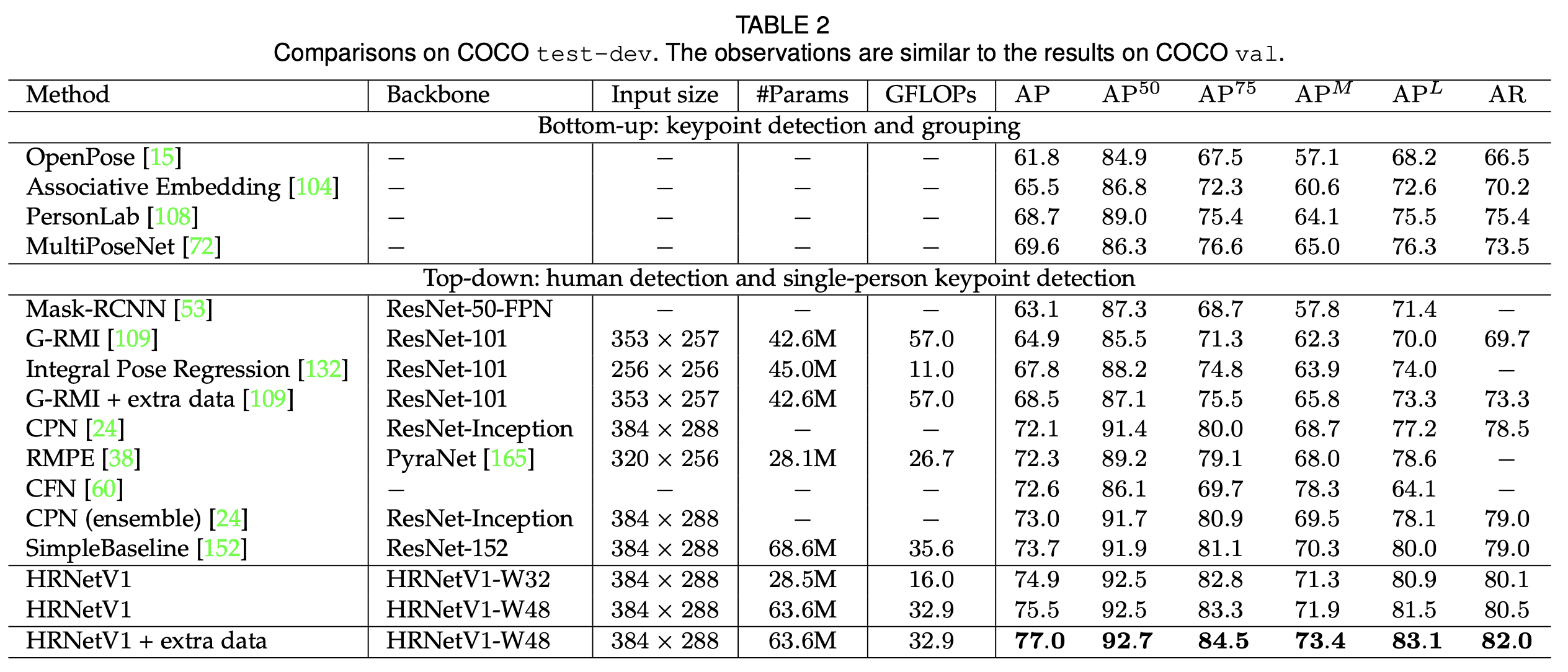
test-dev集上的结果:表2报告了我们的方法以及现有最先进方法的姿态估计性能。我们的方法明显优于自下而上的方法。另一方面,我们的小型网络HRNetV1-W32获得了74.9的平均精度,它优于所有其他自上而下的方法,并且在模型尺寸(参数数量)和计算复杂度(浮点运算次数)方面更高效。我们的大型模型HRNetV1-W48获得了最高的平均精度得分75.5。与具有相同输入尺寸的SimpleBaseline [152]相比,我们的小型和大型网络分别获得了1.2和1.8个百分点的提升。通过使用来自AI Challenger [148]的额外数据进行训练,我们的单个大型网络可以获得77.0的平均精度。

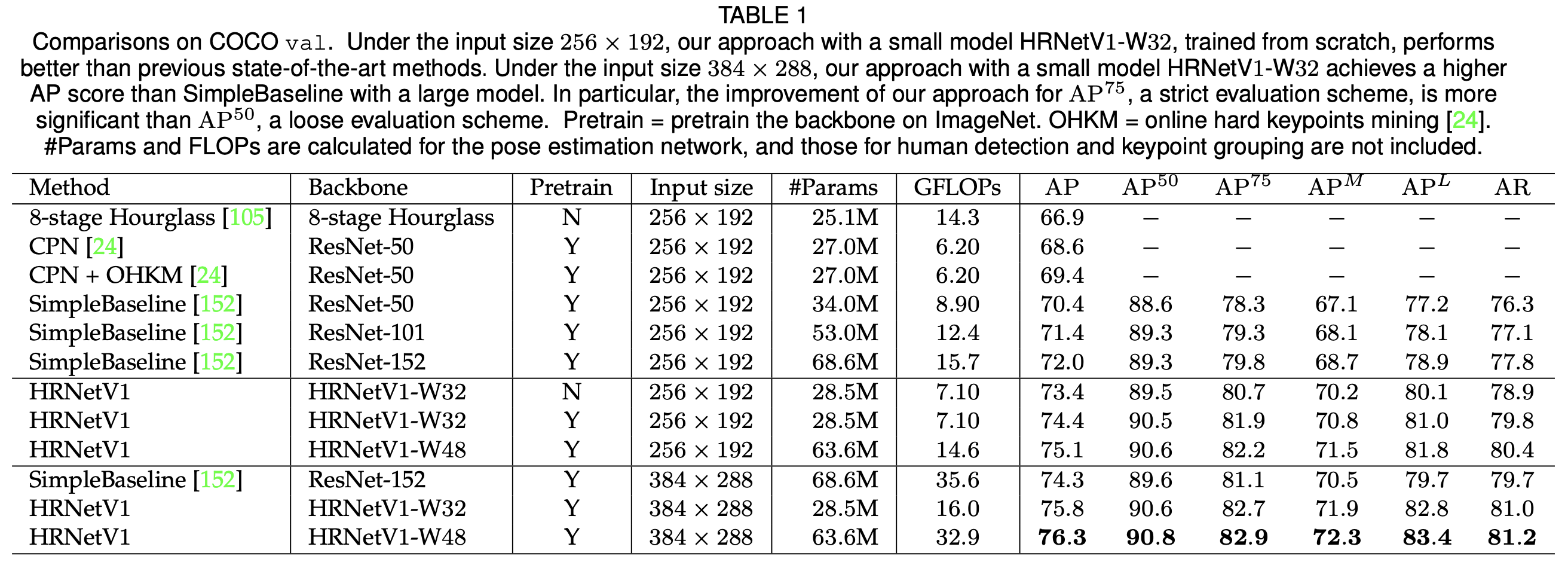 表1,在COCO验证集(val)上的对比情况。在输入尺寸为256×192的情况下,我们采用小型模型HRNetV1-W32且从头开始训练的方法,其性能优于之前的最先进方法。在输入尺寸为384×288时,我们使用小型模型HRNetV1-W32的方法所取得的平均精度(AP)得分高于采用大型模型的SimpleBaseline方法。尤其需要指出的是,我们的方法在平均精度75(AP75,一种严格的评估方案)方面的提升比平均精度50(AP50,一种宽松的评估方案)方面的提升更为显著。“Pretrain”表示在ImageNet上对骨干网络进行预训练。“OHKM”表示在线困难关键点挖掘[24]。参数数量(#Params)和浮点运算次数(FLOPs)是针对姿态估计网络进行计算的,而人体检测和关键点分组所涉及的相关运算量并未包含在内。
表1,在COCO验证集(val)上的对比情况。在输入尺寸为256×192的情况下,我们采用小型模型HRNetV1-W32且从头开始训练的方法,其性能优于之前的最先进方法。在输入尺寸为384×288时,我们使用小型模型HRNetV1-W32的方法所取得的平均精度(AP)得分高于采用大型模型的SimpleBaseline方法。尤其需要指出的是,我们的方法在平均精度75(AP75,一种严格的评估方案)方面的提升比平均精度50(AP50,一种宽松的评估方案)方面的提升更为显著。“Pretrain”表示在ImageNet上对骨干网络进行预训练。“OHKM”表示在线困难关键点挖掘[24]。参数数量(#Params)和浮点运算次数(FLOPs)是针对姿态估计网络进行计算的,而人体检测和关键点分组所涉及的相关运算量并未包含在内。
8 总结
在本文中,我们提出了一种用于视觉识别问题的高分辨率网络。它与现有的低分辨率分类网络和高分辨率表征学习网络存在三个根本差异:(i)并行连接高分辨率和低分辨率卷积,而非串联;(ii)在整个过程中维持高分辨率,而非从低分辨率恢复高分辨率;(iii)反复融合多分辨率表征,从而生成具有强位置敏感性的丰富的高分辨率表征。
在众多视觉识别问题上取得的优异结果表明,我们所提出的高分辨率网络(HRNet)是解决计算机视觉问题的一种更强大的骨干网络。我们的研究也鼓励人们投入更多的研究精力去直接针对特定视觉问题设计网络架构,而不是对从低分辨率网络(例如ResNet或VGGNet)中学到的表征进行扩展、修正或修复。
讨论:可能存在一种误解:认为由于分辨率更高,高分辨率网络(HRNet)的内存开销更大。实际上,在人体姿态估计、语义分割和目标检测这三种应用中,高分辨率网络(HRNet)的内存开销与最先进的方法相当,只是在目标检测中的训练内存开销略大一些。
此外,我们总结了在PyTorch 1.0平台上运行时开销的对比情况。高分辨率网络(HRNet)的训练和推理时间开销与之前的最先进方法相当,除了以下两点:(1)高分辨率网络(HRNet)用于分割任务的推理时间要少得多;(2)高分辨率网络(HRNet)用于姿态估计的训练时间略长一些,不过在支持静态图推理的MXNet 1.5.1平台上,其开销与SimpleBaseline相似。我们想要强调的是,在语义分割方面,其推理开销明显小于PSPNet和DeepLabv3。表13总结了内存和时间开销的对比情况[5]。
未来及后续工作:我们将研究把高分辨率网络(HRNet)与其他技术相结合,用于语义分割和实例分割。目前,通过将高分辨率网络(HRNet)与目标上下文表征(OCR)方案[170][6](目标上下文[59][171]的一种变体)相结合,我们已经取得了一些结果(平均交并比,即mIoU),这些结果在表3、4、5、6中有展示。我们将通过进一步提高表征的分辨率(例如提高到1/2甚至全分辨率)来开展相关研究。
高分辨率网络(HRNet)的应用并不局限于我们已经开展的上述应用,它适用于其他对位置敏感的视觉应用,例如面部关键点检测[7]、超分辨率、光流估计、深度估计等等。目前已经有了一些后续工作,例如图像风格化[83]、图像修复[50]、图像增强[62]、图像去雾[1]、时序姿态估计[6]以及无人机目标检测[190]。
据[26]报道,一个经过轻微修改的高分辨率网络(HRNet)与空洞空间金字塔池化(ASPP)相结合,在单模型情况下实现了Mapillary全景分割的最佳性能。在2019年国际计算机视觉大会(ICCV)的COCO + Mapillary联合识别挑战赛研讨会中,COCO密集姿态挑战赛的获胜者以及几乎所有COCO关键点检测挑战赛的参与者都采用了高分辨率网络(HRNet)。OpenImage实例分割挑战赛(ICCV 2019)的获胜者也使用了高分辨率网络(HRNet)。
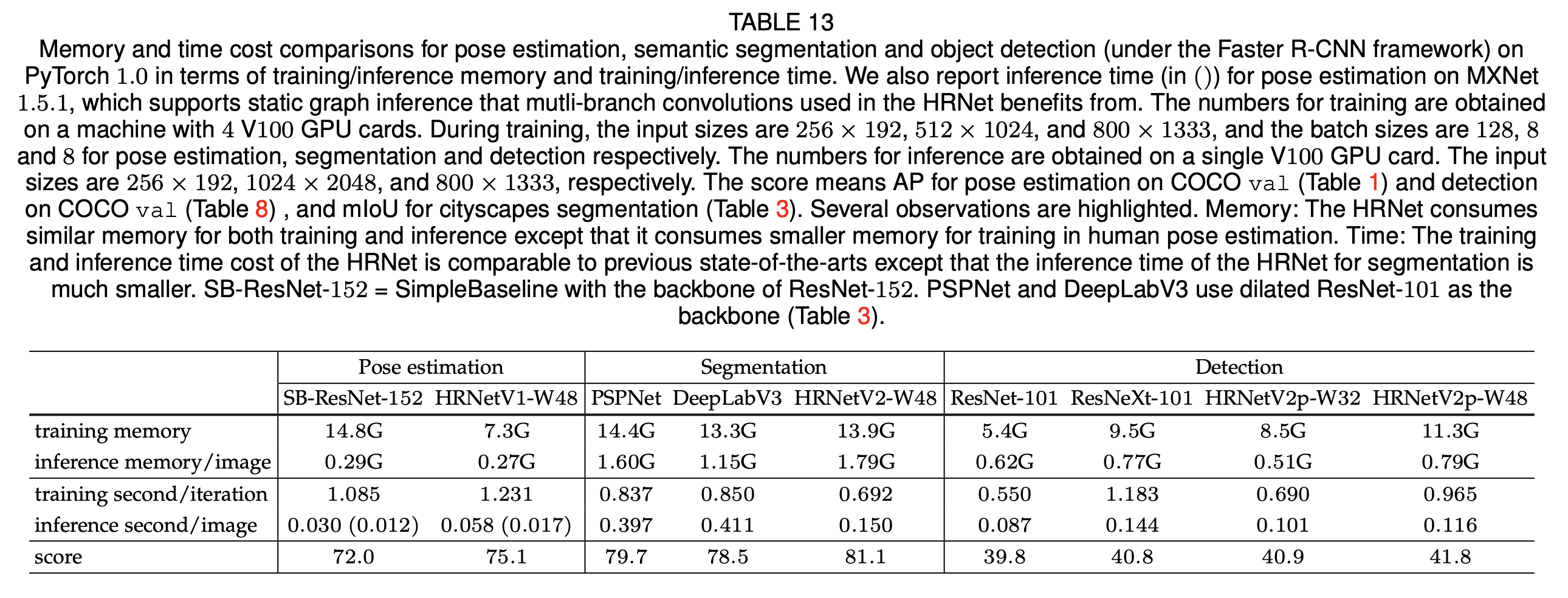 表13,在PyTorch 1.0平台上,针对人体姿态估计、语义分割以及目标检测(在Faster R-CNN框架下),从训练/推理内存以及训练/推理时间方面进行内存和时间开销的对比。我们还报告了在MXNet 1.5.1平台上人体姿态估计的推理时间(括号内所示),MXNet 1.5.1支持静态图推理,高分辨率网络(HRNet)中使用的多分支卷积可从中受益。 训练相关的数据是在一台配备4块V100 GPU显卡的机器上获取的。在训练期间,人体姿态估计、语义分割和目标检测的输入尺寸分别为256×192、512×1024和800×1333,批量大小分别为128、8和8。推理相关的数据是在单块V100 GPU显卡上获取的,输入尺寸分别为256×192、1024×2048和800×1333。得分方面,对于人体姿态估计指的是在COCO验证集(表1)上的平均精度(AP),对于目标检测指的是在COCO验证集(表8)上的平均精度,对于城市景观(Cityscapes)语义分割指的是平均交并比(mIoU,表3)。有几点值得强调的观察结果如下: 内存方面:高分辨率网络(HRNet)在训练和推理时消耗的内存与其他方法相近,不过在人体姿态估计的训练中,它消耗的内存更少。 时间方面:高分辨率网络(HRNet)的训练和推理时间开销与之前的最先进方法相当,不过它用于语义分割任务时的推理时间要少得多。 SB-ResNet-152表示以ResNet - 152作为骨干网络的SimpleBaseline。PSPNet和DeepLabV3使用扩张的ResNet - 101作为骨干网络(表3)。
表13,在PyTorch 1.0平台上,针对人体姿态估计、语义分割以及目标检测(在Faster R-CNN框架下),从训练/推理内存以及训练/推理时间方面进行内存和时间开销的对比。我们还报告了在MXNet 1.5.1平台上人体姿态估计的推理时间(括号内所示),MXNet 1.5.1支持静态图推理,高分辨率网络(HRNet)中使用的多分支卷积可从中受益。 训练相关的数据是在一台配备4块V100 GPU显卡的机器上获取的。在训练期间,人体姿态估计、语义分割和目标检测的输入尺寸分别为256×192、512×1024和800×1333,批量大小分别为128、8和8。推理相关的数据是在单块V100 GPU显卡上获取的,输入尺寸分别为256×192、1024×2048和800×1333。得分方面,对于人体姿态估计指的是在COCO验证集(表1)上的平均精度(AP),对于目标检测指的是在COCO验证集(表8)上的平均精度,对于城市景观(Cityscapes)语义分割指的是平均交并比(mIoU,表3)。有几点值得强调的观察结果如下: 内存方面:高分辨率网络(HRNet)在训练和推理时消耗的内存与其他方法相近,不过在人体姿态估计的训练中,它消耗的内存更少。 时间方面:高分辨率网络(HRNet)的训练和推理时间开销与之前的最先进方法相当,不过它用于语义分割任务时的推理时间要少得多。 SB-ResNet-152表示以ResNet - 152作为骨干网络的SimpleBaseline。PSPNet和DeepLabV3使用扩张的ResNet - 101作为骨干网络(表3)。
9 代码和onnx模型
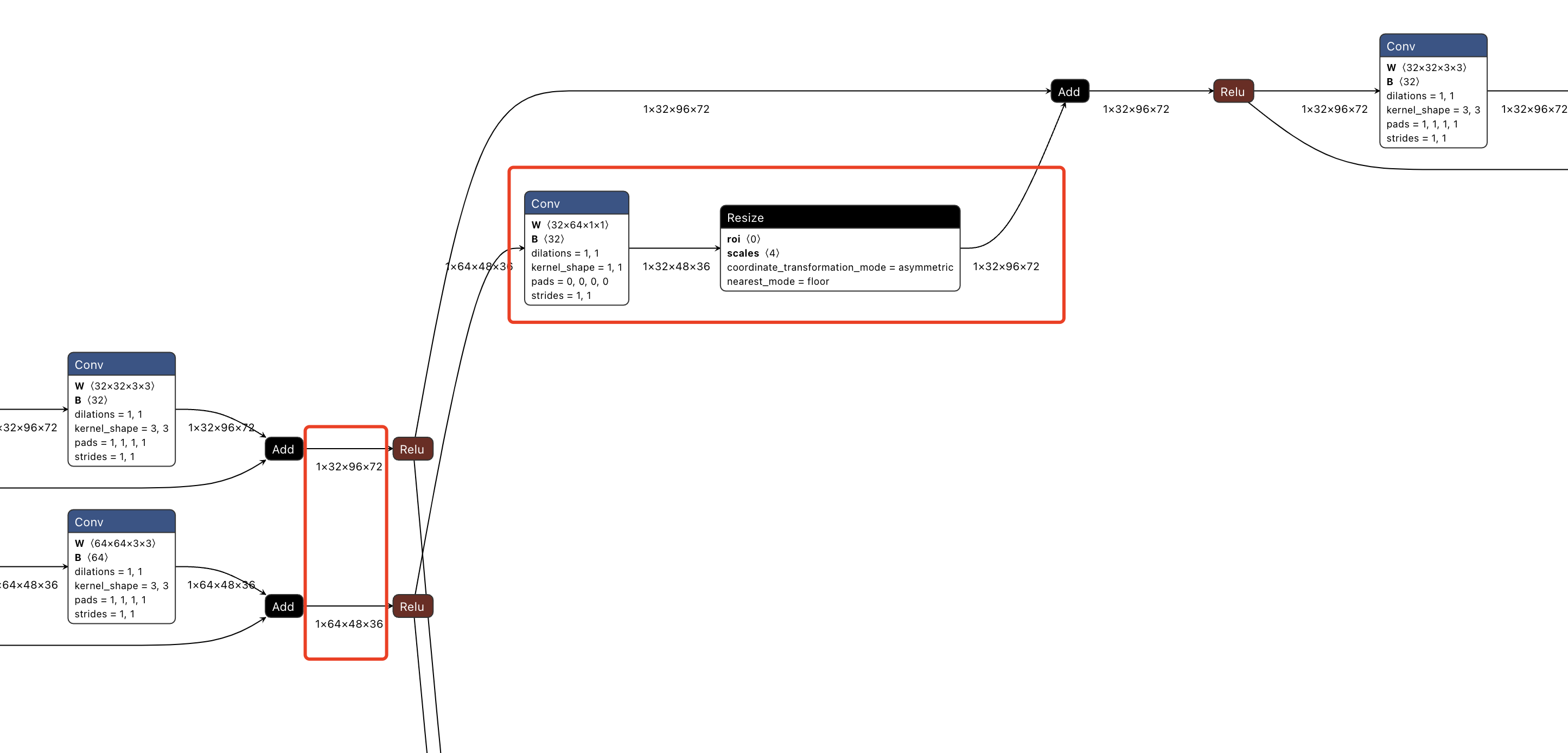
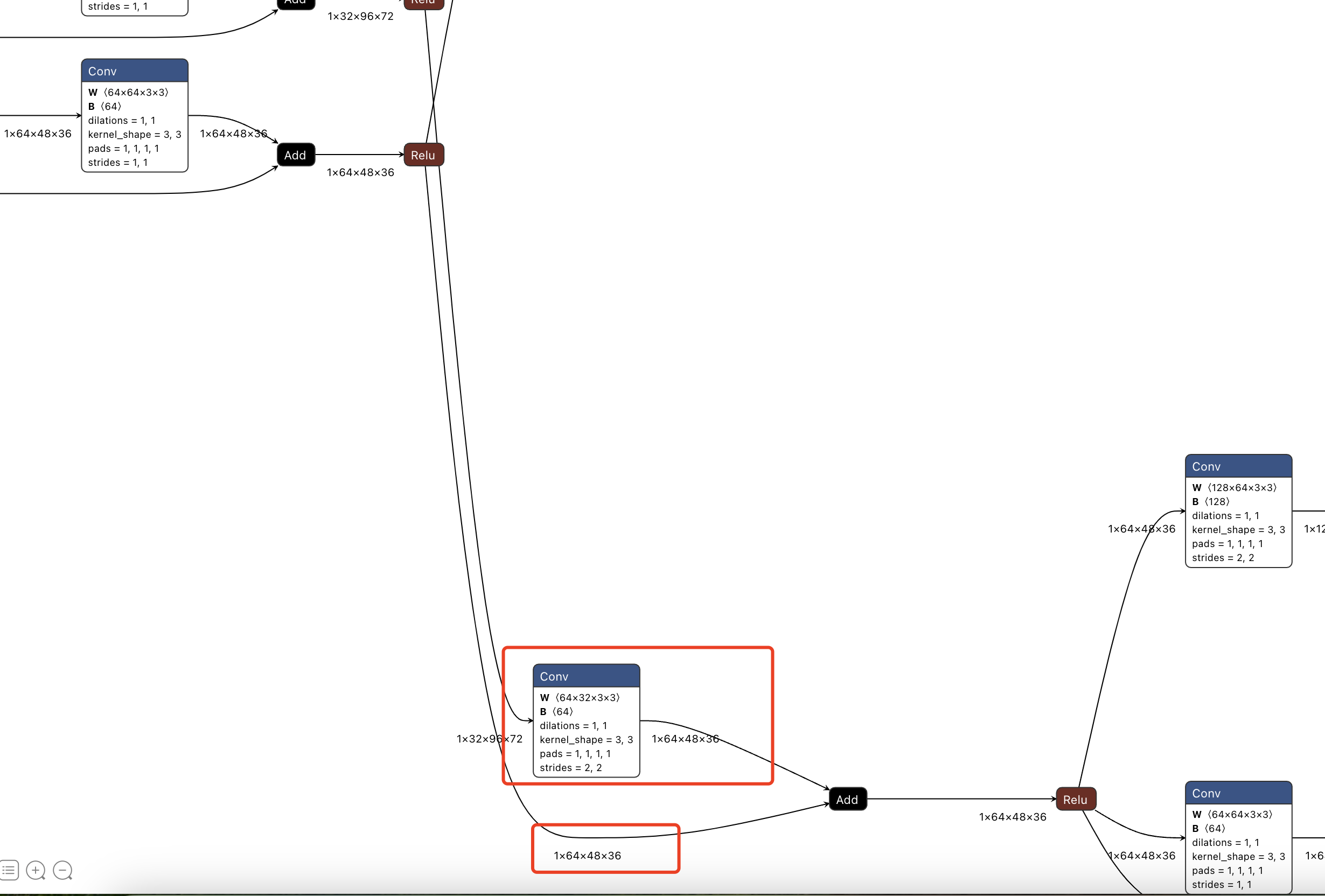
从图2可以看到整个hrnet模型的结构。其结构的主要特点是由4个阶段组成,第234阶段会逐渐多一个1/2, 1/4, 1/8分辨率的分支。
我们结合代码和onnx看一下。
class HRNet(nn.Module):
def __init__(self, c=48, nof_joints=17, bn_momentum=0.1):
super(HRNet, self).__init__()
# Input (stem net)
self.conv1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
self.bn1 = nn.BatchNorm2d(64, eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True)
self.conv2 = nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
self.bn2 = nn.BatchNorm2d(64, eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True)
self.relu = nn.ReLU(inplace=True)
# Stage 1 (layer1) - First group of bottleneck (resnet) modules
downsample = nn.Sequential(
nn.Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False),
nn.BatchNorm2d(256, eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True),
)
self.layer1 = nn.Sequential(
Bottleneck(64, 64, downsample=downsample),
Bottleneck(256, 64),
Bottleneck(256, 64),
Bottleneck(256, 64),
)
# Fusion layer 1 (transition1) - Creation of the first two branches (one full and one half resolution)
self.transition1 = nn.ModuleList([
nn.Sequential(
nn.Conv2d(256, c, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
nn.BatchNorm2d(c, eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
),
nn.Sequential(nn.Sequential( # Double Sequential to fit with official pretrained weights
nn.Conv2d(256, c * (2 ** 1), kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False),
nn.BatchNorm2d(c * (2 ** 1), eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
)),
])
# Stage 2 (stage2) - Second module with 1 group of bottleneck (resnet) modules. This has 2 branches
self.stage2 = nn.Sequential(
StageModule(stage=2, output_branches=2, c=c, bn_momentum=bn_momentum),
)
# Fusion layer 2 (transition2) - Creation of the third branch (1/4 resolution)
self.transition2 = nn.ModuleList([
nn.Sequential(), # None, - Used in place of "None" because it is callable
nn.Sequential(), # None, - Used in place of "None" because it is callable
nn.Sequential(nn.Sequential( # Double Sequential to fit with official pretrained weights
nn.Conv2d(c * (2 ** 1), c * (2 ** 2), kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False),
nn.BatchNorm2d(c * (2 ** 2), eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
)), # ToDo Why the new branch derives from the "upper" branch only?
])
# Stage 3 (stage3) - Third module with 4 groups of bottleneck (resnet) modules. This has 3 branches
self.stage3 = nn.Sequential(
StageModule(stage=3, output_branches=3, c=c, bn_momentum=bn_momentum),
StageModule(stage=3, output_branches=3, c=c, bn_momentum=bn_momentum),
StageModule(stage=3, output_branches=3, c=c, bn_momentum=bn_momentum),
StageModule(stage=3, output_branches=3, c=c, bn_momentum=bn_momentum),
)
# Fusion layer 3 (transition3) - Creation of the fourth branch (1/8 resolution)
self.transition3 = nn.ModuleList([
nn.Sequential(), # None, - Used in place of "None" because it is callable
nn.Sequential(), # None, - Used in place of "None" because it is callable
nn.Sequential(), # None, - Used in place of "None" because it is callable
nn.Sequential(nn.Sequential( # Double Sequential to fit with official pretrained weights
nn.Conv2d(c * (2 ** 2), c * (2 ** 3), kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False),
nn.BatchNorm2d(c * (2 ** 3), eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
)), # ToDo Why the new branch derives from the "upper" branch only?
])
# Stage 4 (stage4) - Fourth module with 3 groups of bottleneck (resnet) modules. This has 4 branches
self.stage4 = nn.Sequential(
StageModule(stage=4, output_branches=4, c=c, bn_momentum=bn_momentum),
StageModule(stage=4, output_branches=4, c=c, bn_momentum=bn_momentum),
StageModule(stage=4, output_branches=1, c=c, bn_momentum=bn_momentum),
)
# Final layer (final_layer)
self.final_layer = nn.Conv2d(c, nof_joints, kernel_size=(1, 1), stride=(1, 1))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.layer1(x)
x = [trans(x) for trans in self.transition1] # Since now, x is a list (# == nof branches)
x = self.stage2(x)
# x = [trans(x[-1]) for trans in self.transition2] # New branch derives from the "upper" branch only
x = [
self.transition2[0](x[0]),
self.transition2[1](x[1]),
self.transition2[2](x[-1])
] # New branch derives from the "upper" branch only
x = self.stage3(x)
# x = [trans(x) for trans in self.transition3] # New branch derives from the "upper" branch only
x = [
self.transition3[0](x[0]),
self.transition3[1](x[1]),
self.transition3[2](x[2]),
self.transition3[3](x[-1])
] # New branch derives from the "upper" branch only
x = self.stage4(x)
x = self.final_layer(x[0])
return x
9.1 首先是bottleneck部分,也就是图2的网络结构中的第1阶段。
# Stage 1 (layer1) - First group of bottleneck (resnet) modules
downsample = nn.Sequential(
nn.Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False),
nn.BatchNorm2d(256, eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True),
)
self.layer1 = nn.Sequential(
Bottleneck(64, 64, downsample=downsample),
Bottleneck(256, 64),
Bottleneck(256, 64),
Bottleneck(256, 64),
)

从onnx上,这部分网络是resnet结构,在传递过程中,保证了特征图分辨率的一致,与图2的网络结构图示相同。
9.2 全分辨率和1/2分辨率阶段,即图2的第2阶段
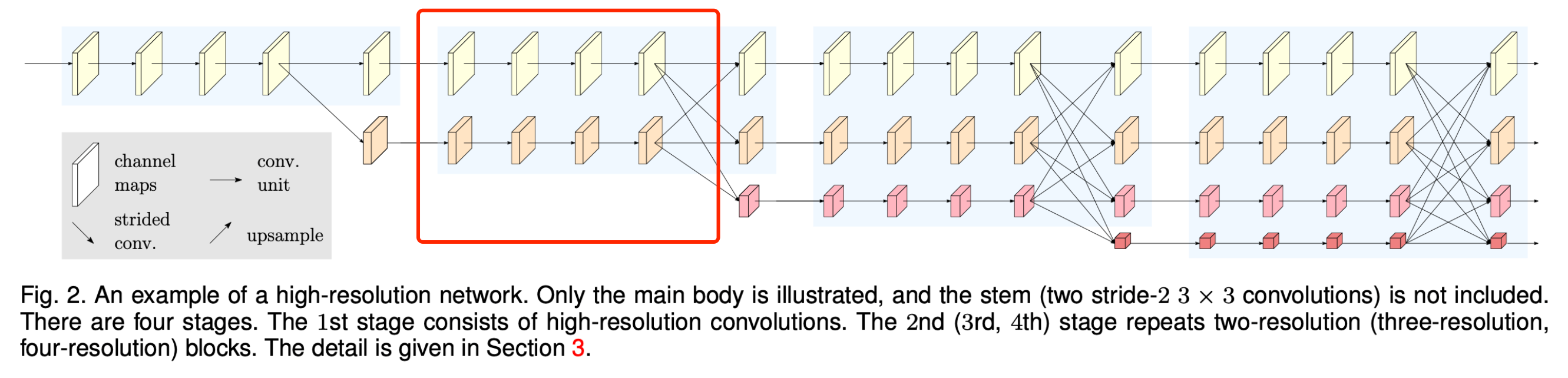
# Fusion layer 1 (transition1) - Creation of the first two branches (one full and one half resolution)
self.transition1 = nn.ModuleList([
nn.Sequential(
nn.Conv2d(256, c, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
nn.BatchNorm2d(c, eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
),
nn.Sequential(nn.Sequential( # Double Sequential to fit with official pretrained weights
nn.Conv2d(256, c * (2 ** 1), kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False),
nn.BatchNorm2d(c * (2 ** 1), eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
)),
])
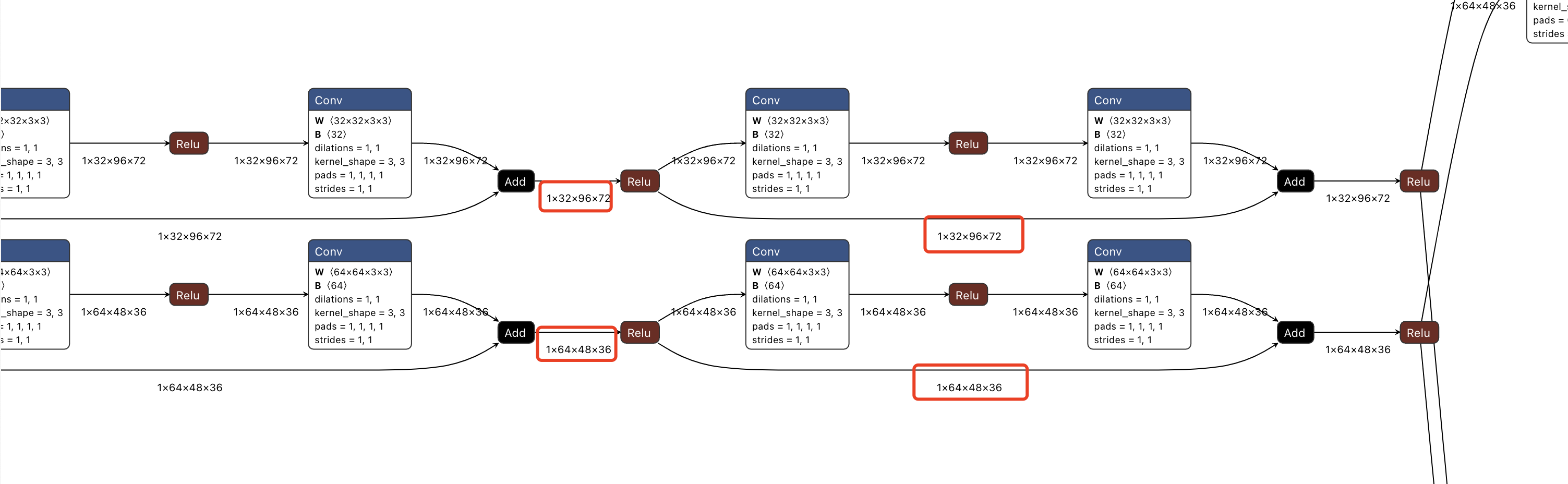
从onnx看,这部分是两个分支,一个是全分辨率分支,一个是1/2分辨率分支。两个分支分别在前向传递过程中,保持了分辨率的一致。
9.3 全分辨率、1/2分辨率和1/4分辨率阶段,即图2的第3阶段
# Fusion layer 2 (transition2) - Creation of the third branch (1/4 resolution)
self.transition2 = nn.ModuleList([
nn.Sequential(), # None, - Used in place of "None" because it is callable
nn.Sequential(), # None, - Used in place of "None" because it is callable
nn.Sequential(nn.Sequential( # Double Sequential to fit with official pretrained weights
nn.Conv2d(c * (2 ** 1), c * (2 ** 2), kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False),
nn.BatchNorm2d(c * (2 ** 2), eps=1e-05, momentum=bn_momentum, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
)), # ToDo Why the new branch derives from the "upper" branch only?
])
从onnx看,一共三个分支,分别是全分辨率、1/2、1/4分辨率。
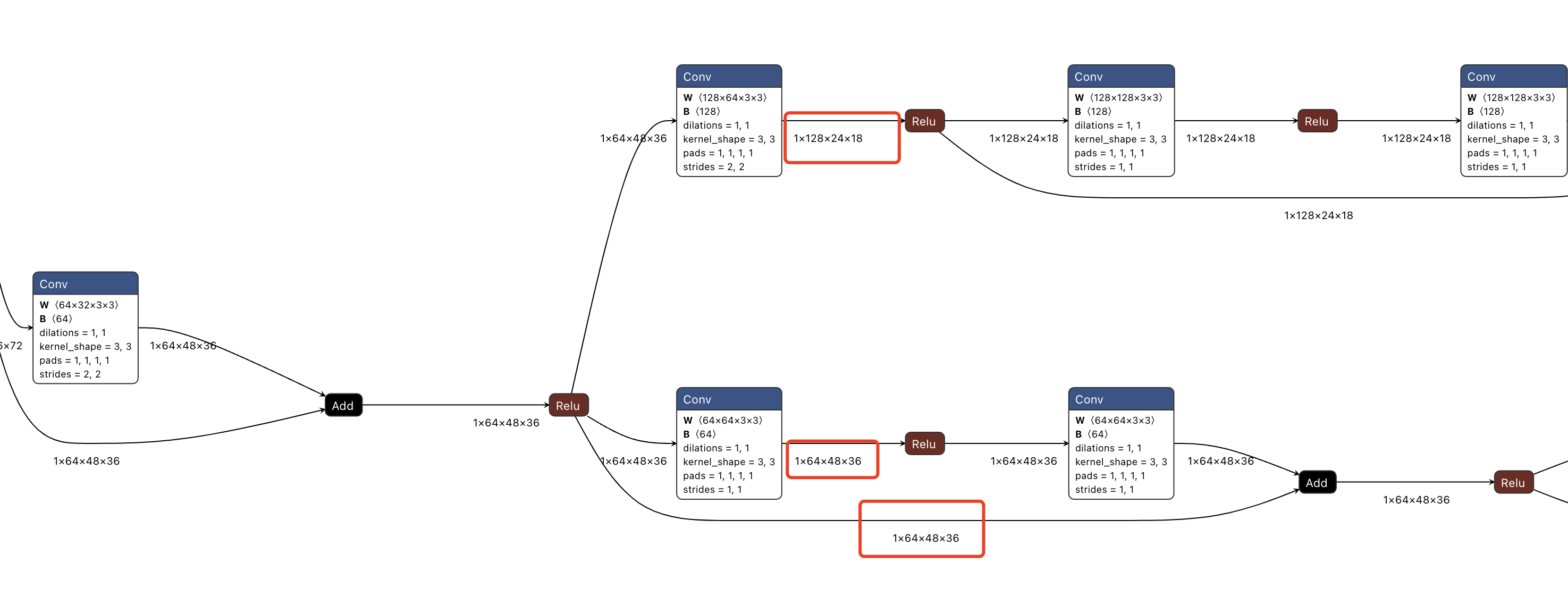
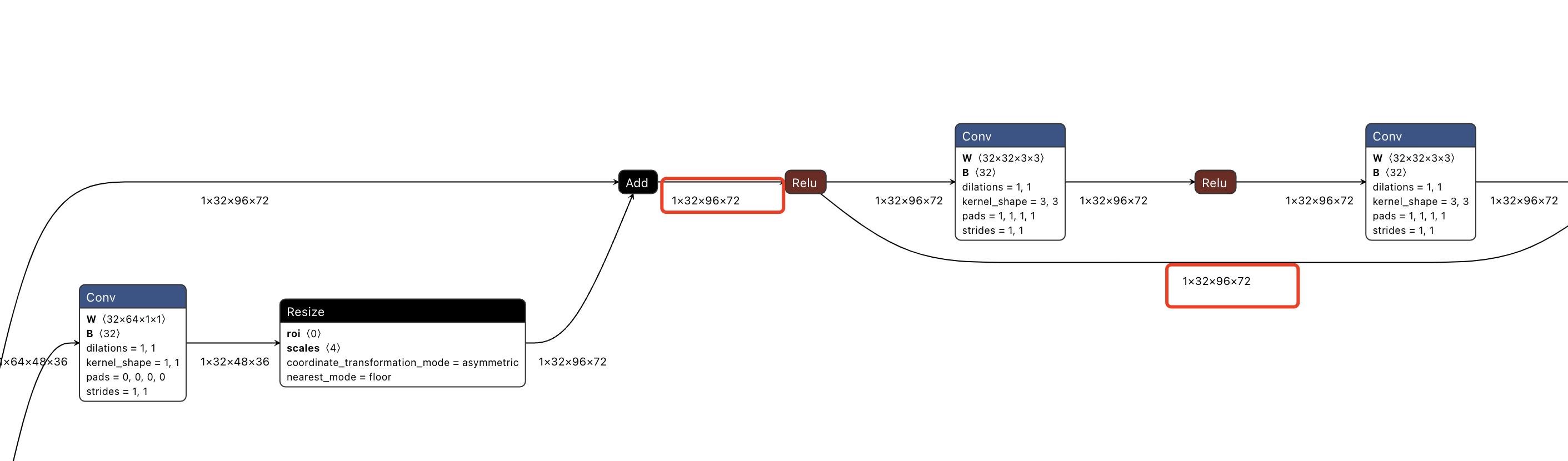
但是注意在由第2阶段的双分支转为第3阶段的三分支时,全分辨率分支和1/2分辨率分支,全部通过插值或者降采样的方式,参与了新的3个分支的计算,如下面的onnx模型结构所示。