使用pytorch从头实现一个vit
Published:
我们实现的目标是做image classification,使用MINIST数据集。
首先把必要的库导入进来。
import numpy as np
from tqdm import tqdm, trange
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.nn import CrossEntropyLoss
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
from torchvision.datasets.mnist import MNIST
import platform
np.random.seed(0)
torch.manual_seed(0)
然后创建一个主函数,该函数准备MNIST数据集,实例化一个模型,并训练5个epoch。之后,在测试集上测量损失和准确率。
def main():
# Loading data
transform = ToTensor()
train_set = MNIST(root='./../datasets', train=True, download=True, transform=transform)
test_set = MNIST(root='./../datasets', train=False, download=True, transform=transform)
train_loader = DataLoader(train_set, shuffle=True, batch_size=128)
test_loader = DataLoader(test_set, shuffle=False, batch_size=128)
# Defining model and training options
if platform.system() == 'Darwin':
# MacOS系统,使用MPS后端
if torch.backends.mps.is_available():
device = torch.device('mps')
else:
device = torch.device('cpu')
else:
# Linux或Windows系统,使用CUDA后端
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
print('Device:', device)
model = MyViT((1, 28, 28), n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10).to(device)
N_EPOCHS = 5
LR = 0.005
# Training loop
optimizer = Adam(model.parameters(), lr=LR)
criterion = CrossEntropyLoss()
for epoch in trange(N_EPOCHS, desc="Training"):
train_loss = 0.0
for batch in tqdm(train_loader, desc=f"Epoch {epoch + 1} in training", leave=False):
x, y = batch
x, y = x.to(device), y.to(device)
y_hat = model(x)
loss = criterion(y_hat, y)
train_loss += loss.detach().cpu().item() / len(train_loader)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}/{N_EPOCHS} loss: {train_loss:.2f}")
# Test loop
with torch.no_grad():
correct, total = 0, 0
test_loss = 0.0
for batch in tqdm(test_loader, desc="Testing"):
x, y = batch
x, y = x.to(device), y.to(device)
y_hat = model(x)
loss = criterion(y_hat, y)
test_loss += loss.detach().cpu().item() / len(test_loader)
correct += torch.sum(torch.argmax(y_hat, dim=1) == y).detach().cpu().item()
total += len(x)
print(f"Test loss: {test_loss:.2f}")
print(f"Test accuracy: {correct / total * 100:.2f}%")
现在我们有了这个模板,从现在开始,我们可以只关注模型(ViT),它将对形状为(N x 1 x 28 x 28)的图像进行分类。 让我们先定义一个空的nn.Module。然后我们将逐步填充这个类。
class MyViT(nn.Module):
def __init__(self):
# Super constructor
super(MyViT, self).__init__()
def forward(self, images):
pass
forward计算
由于PyTorch以及大多数深度学习框架都提供了自动梯度计算,我们只需要关注实现ViT模型的前向传播。由于我们已经定义了模型的优化器,框架将负责梯度的反向传播和训练模型的参数。
我们将实现Bazi等人的paper Vision Transformers for Remote Sensing Image Classification中的vit的结构,如下图所示
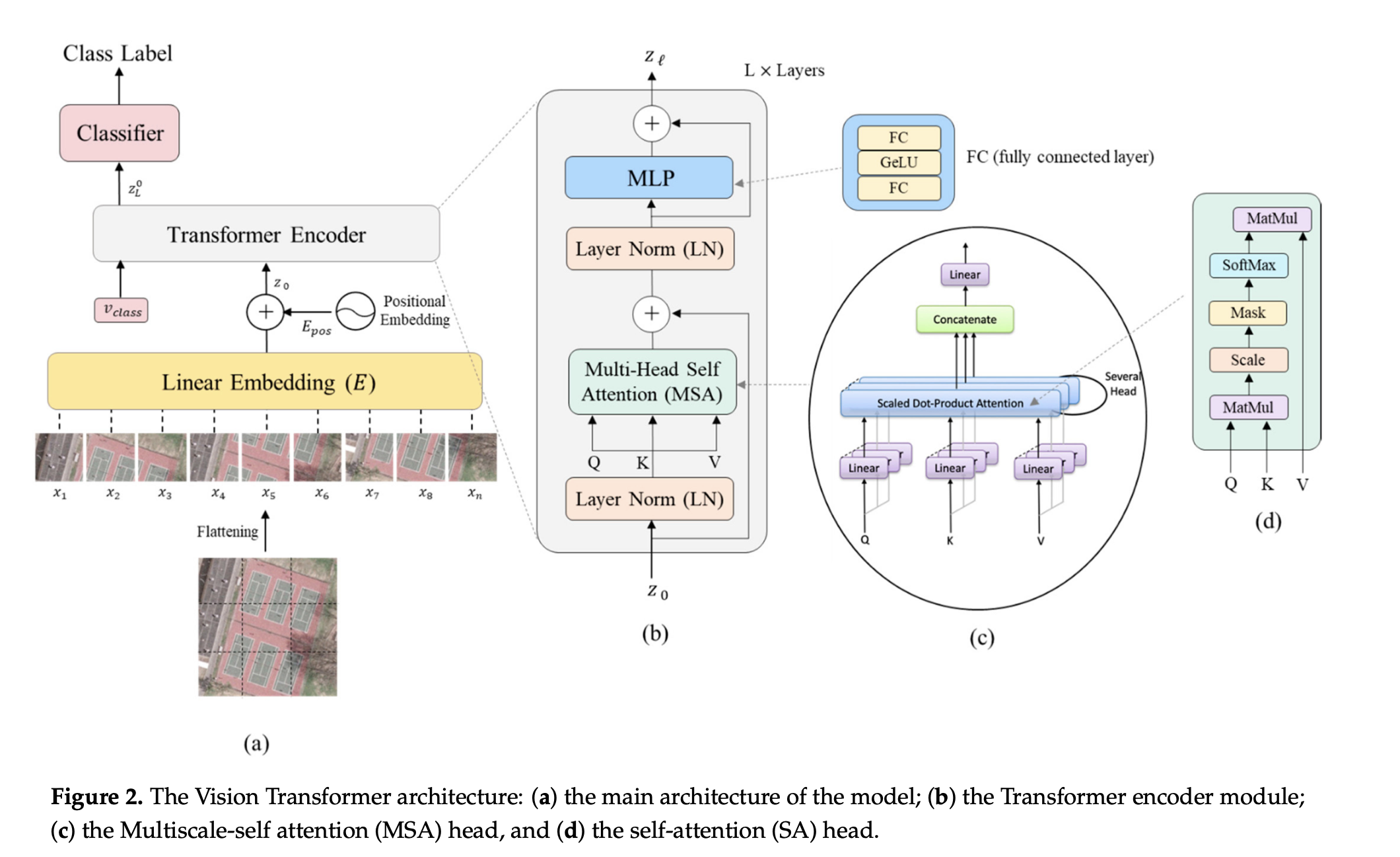
根据图片,我们可以看到输入图像(a)被“切割”成等大小的子图像。 每个这样的子图像都通过一个Linear Embedding。经过Linear Embedding之后,每个子图像只是一个一维向量。
然后向这些向量(标记)添加Positional Embedding。Positional Embedding允许网络知道每个子图像最初在图像中的位置。没有这些信息,网络将无法知道每个这样的图像将被放置在哪里,从而导致可能的错误预测。
然后,这些标记连同一个特殊的分类标记一起传递给Transformer Encoder,每个Encoder由:层归一化(LN),后接多头自注意力(MSA)和残差连接。然后是第二个LN,一个多层感知器(MLP),再次是残差连接。最后,使用分类MLP块对最终分类进行处理,仅在特殊的分类标记上进行,该标记在此过程结束时具有关于图片的全局信息。
让我们分6个主要步骤构建ViT。
步骤1:分割和线性映射
Transformer Encoder是针对序列数据开发的,例如英语句子。然而,图像并不是序列。我们将图像分解成多个子图像来实现序列话,并将每个子图像映射到一个向量。
我们通过简单地reshape我们的输入来实现这一点,输入的大小为(N,C,H,W)(在我们的示例中为(N,1,28,28),MNIST数据集里面,图像的大小就是28x28),调整为大小(N,#Patches,Patch维度)。
在这个例子中,我们将每个(1,28,28)分解成7x7个patch(因此,每个patch大小为4x4)。也就是说,我们将从单个图像中获得7x7=49个子图像,如下图所示。
因此,我们将输入(N,1,28,28)重塑为: (N,P²,HWC/P²)=(N,7x7,4x4)=(N,49,16)
虽然每个patch是大小为1x4x4的图片,但我们将其展平为一个16维向量。此外,在这种情况下,我们只有一个颜色通道。如果我们有多个颜色通道,这些通道也会被展平到向量中。
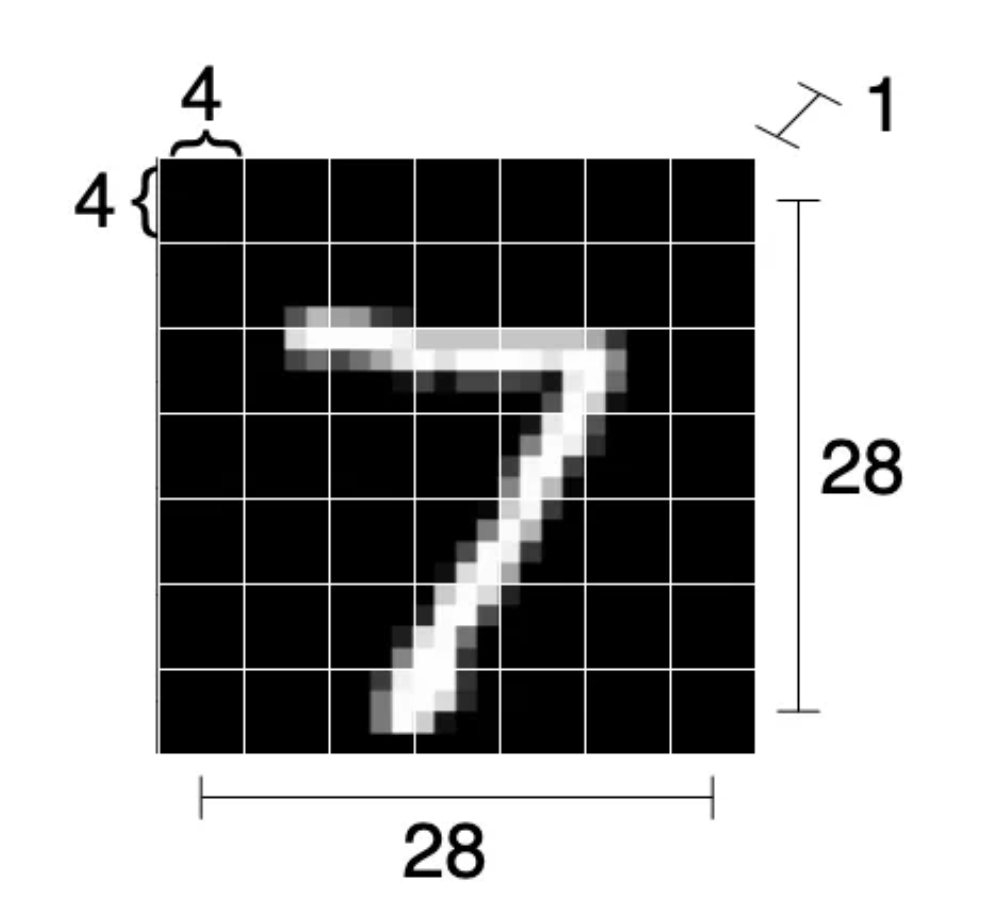
我们修改了MyViT类,仅实现分割功能。我们创建了一个从头开始执行该操作的方法。这是一种效率不高的写法,但代码对于学习核心概念来说直观易懂。
def patchify(images, n_patches):
n, c, h, w = images.shape
assert h == w, "Patchify method is implemented for square images only"
patches = torch.zeros(n, n_patches ** 2, h * w * c // n_patches ** 2)
patch_size = h // n_patches
for idx, image in enumerate(images):
for i in range(n_patches):
for j in range(n_patches):
patch = image[:, i * patch_size: (i + 1) * patch_size, j * patch_size: (j + 1) * patch_size]
patches[idx, i * n_patches + j] = patch.flatten()
return patches
class MyViT(nn.Module):
def __init__(self, chw=(1, 28, 28), n_patches=7):
# Super constructor
super(MyViT, self).__init__()
# Attributes
self.chw = chw # (C, H, W)
self.n_patches = n_patches
assert chw[1] % n_patches == 0, "Input shape not entirely divisible by number of patches"
assert chw[2] % n_patches == 0, "Input shape not entirely divisible by number of patches"
def forward(self, images):
patches = patchify(images, self.n_patches)
return patches
类的构造函数现在让类知道我们输入图像的大小(通道数、高度和宽度)。在我们的实现中,n_patches 变量表示我们在宽度和高度单一方向上的块的数量,实际上要切分的块的数量是n_patches^2个块(在我们的例子中是7,因为我们将图像分割成7x7的块)。
我们可以用一个简单的主程序来测试我们类的功能性:
if __name__ == '__main__':
# Current model
model = MyViT(
chw=(1, 28, 28),
n_patches=7
)
x = torch.randn(7, 1, 28, 28) # Dummy images
print(model(x).shape) # torch.Size([7, 49, 16])
现在我们已经得到了展平的块,我们可以通过线性映射将它们一一映射。虽然每个块是一个4x4=16维的向量,但线性映射可以映射到任何任意的向量大小。因此,我们在类构造函数中添加了一个参数,称为 hidden_d,代表“隐藏维度”。
在这个例子中,我们将使用一个隐藏维度为8,但原则上这里可以放置任何数字。因此,我们将每个16维的块映射到一个8维的块。
我们只需创建一个 nn.Linear 层,并在前向函数中调用它。
class MyViT(nn.Module):
def __init__(self, chw=(1, 28, 28), n_patches=7):
# Super constructor
super(MyViT, self).__init__()
# Attributes
self.chw = chw # (C, H, W)
self.n_patches = n_patches
assert chw[1] % n_patches == 0, "Input shape not entirely divisible by number of patches"
assert chw[2] % n_patches == 0, "Input shape not entirely divisible by number of patches"
self.patch_size = (chw[1] / n_patches, chw[2] / n_patches)
# 1) Linear mapper
self.input_d = int(chw[0] * self.patch_size[0] * self.patch_size[1])
self.linear_mapper = nn.Linear(self.input_d, self.hidden_d)
def forward(self, images):
patches = patchify(images, self.n_patches)
tokens = self.linear_mapper(patches)
return tokens
注意,我们通过一个(16, 8)的线性映射层处理一个(N, 49, 16)的张量。线性操作仅在最后一个维度上发生。
步骤二:添加分类标记
如果你仔细观察架构图,我们会发现还有一个“v_class”标记传递给Transformer Encoder。 这是一个我们添加到模型中的特殊标记,它的作用是捕获关于其他标记的信息。当所有其他标记的信息都汇聚在这里时,我们将能够仅使用这个特殊标记来对图像进行分类。v_class初始值是模型的一个参数,参与网络的学习过程。
这是Transformer的一个很强的特性,如果我们想做另一个下游任务,我们只需要为另一个下游任务添加另一个特殊标记(例如,将数字分类为高于5或低于5)和一个以这个新标记为输入的分类器。
我们现在可以向我们的模型添加一个参数,并将我们的(N, 49, 8)标记张量转换为(N, 50, 8)张量(我们在每个序列中添加了特殊标记)。
class MyViT(nn.Module):
def __init__(self, chw=(1, 28, 28), n_patches=7):
# Super constructor
super(MyViT, self).__init__()
# Attributes
self.chw = chw # (C, H, W)
self.n_patches = n_patches
assert chw[1] % n_patches == 0, "Input shape not entirely divisible by number of patches"
assert chw[2] % n_patches == 0, "Input shape not entirely divisible by number of patches"
self.patch_size = (chw[1] / n_patches, chw[2] / n_patches)
# 1) Linear mapper
self.input_d = int(chw[0] * self.patch_size[0] * self.patch_size[1])
self.linear_mapper = nn.Linear(self.input_d, self.hidden_d)
# 2) Learnable classifiation token
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
def forward(self, images):
patches = patchify(images, self.n_patches)
tokens = self.linear_mapper(patches)
# Adding classification token to the tokens
tokens = torch.stack([torch.vstack((self.class_token, tokens[i])) for i in range(len(tokens))])
return tokens
分类标记被放在每个序列的第一个标记位置。当我们稍后检索分类标记以输入到最终的多层感知机(MLP)时,这一点将非常重要。
步骤三:位置编码
正如预期的那样,位置编码允许模型理解每个块在原始图像中的位置。虽然理论上可以学习这样的位置嵌入,但Vaswani等人之前的工作Attention Is All You Need表明,我们可以直接添加正弦和余弦波。
具体来说,位置编码在前几个维度添加高频值,在后几个维度添加低频值。
在每个序列中,对于标记i,我们将其第j个坐标添加以下值:
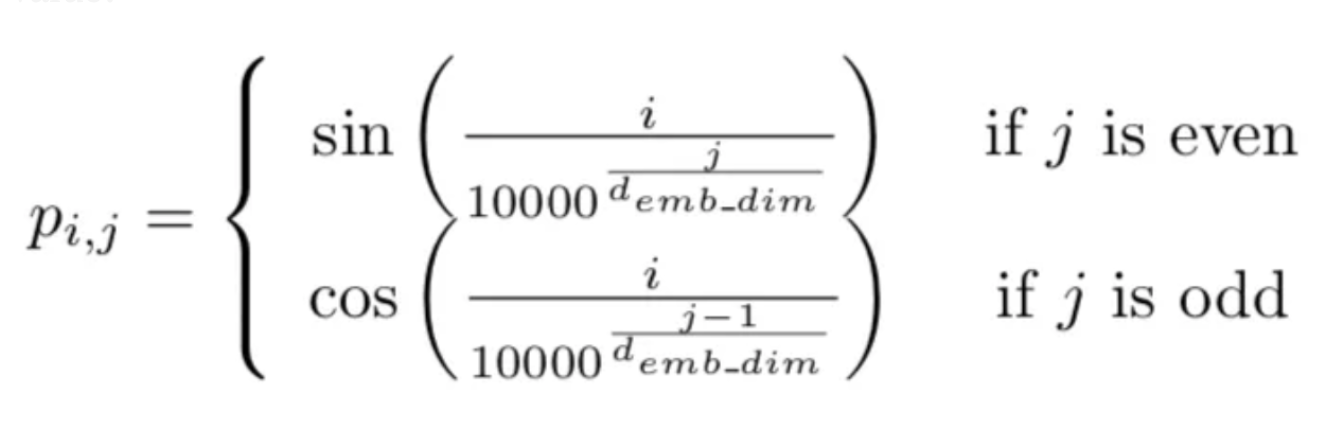
这种位置嵌入是序列中元素数量和每个元素的维度的函数。因此,它总是一个二维张量。
下面的函数是其一个简单的实现。它根据标记的数量和每个标记的维度,输出一个矩阵,其中每个坐标(i,j)是要添加到第i个标记在第j个维度上要添加到token i上的值。
def get_positional_embeddings(sequence_length, d):
result = torch.ones(sequence_length, d)
for i in range(sequence_length):
for j in range(d):
result[i][j] = np.sin(i / (10000 ** (j / d))) if j % 2 == 0 else np.cos(i / (10000 ** ((j - 1) / d)))
return result
if __name__ == "__main__":
import matplotlib.pyplot as plt
plt.imshow(get_positional_embeddings(100, 300), cmap="hot", interpolation="nearest")
plt.show()
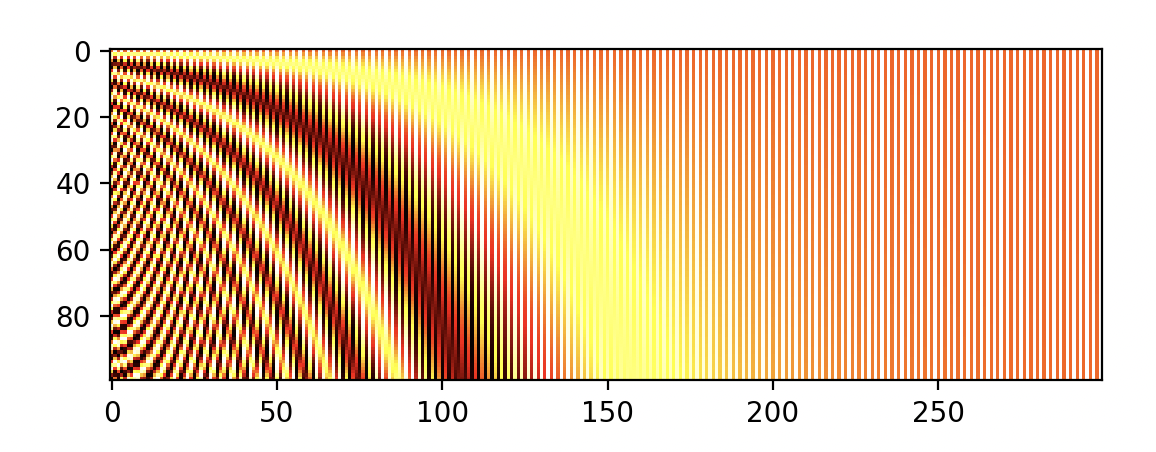
从我们绘制的热图中,我们可以看到所有的“水平线”都是不同的,因此样本可以被区分开来。
我们现在可以在线性映射和添加类别标记之后,将这种位置编码添加到我们的模型中。
class MyViT(nn.Module):
def __init__(self, chw=(1, 28, 28), n_patches=7):
# Super constructor
super(MyViT, self).__init__()
# Attributes
self.chw = chw # (C, H, W)
self.n_patches = n_patches
assert chw[1] % n_patches == 0, "Input shape not entirely divisible by number of patches"
assert chw[2] % n_patches == 0, "Input shape not entirely divisible by number of patches"
self.patch_size = (chw[1] / n_patches, chw[2] / n_patches)
# 1) Linear mapper
self.input_d = int(chw[0] * self.patch_size[0] * self.patch_size[1])
self.linear_mapper = nn.Linear(self.input_d, self.hidden_d)
# 2) Learnable classifiation token
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
# 3) Positional embedding
self.pos_embed = nn.Parameter(torch.tensor(get_positional_embeddings(self.n_patches ** 2 + 1, self.hidden_d)))
self.pos_embed.requires_grad = False
def forward(self, images):
patches = patchify(images, self.n_patches)
tokens = self.linear_mapper(patches)
# Adding classification token to the tokens
tokens = torch.stack([torch.vstack((self.class_token, tokens[i])) for i in range(len(tokens))])
# Adding positional embedding
pos_embed = self.pos_embed.repeat(n, 1, 1)
out = tokens + pos_embed
return out
我们将位置嵌入定义为模型的一个参数(我们通过设置其 requires_grad 为 False 不更新它)。注意,在前向方法中,由于标记的大小为 (N, 50, 8),我们必须将 (50, 8) 的位置编码矩阵重复 N 次。
步骤四:encoder block(part 1/2)
这是最核心的一部分。encoder block以当前张量[N, S, D]作为输入,并输出相同维度的张量。 encoder block的第一部分对我们的标记应用层归一化,然后是多头自注意力机制,最后加上一个残差连接。
多头自注意力(Multi-head Self Attention)是Transformer架构中的关键组成部分,它允许模型在处理一个图像时,每个块(patch)根据与其他块的相似性度量来更新自己。具体来说,每个块(在我们的示例中是一个8维向量)通过线性映射被转换为三个不同的向量:q(query),k(key)和v(value)。
然后,对于单个块,我们会计算它的q向量与所有k向量的点积,除以这些向量维度的平方根(在这里是sqrt(8)),通过softmax函数进行归一化,最后将每个结果与不同的k向量相关的v向量相乘并求和。通过这种方式,每个块根据其与其他块的相似性(在转换为q,k和v之后的相似性)采取一个新的值。然而,整个过程在H个头上执行H次,H是头的数量。
一旦所有结果都得到,它们就会被拼接在一起。最后,结果通过一个线性层传递。直观上,注意力背后的思想是它允许对输入之间的关系进行建模。
由于进行了大量的计算,创建一个新的MSA(Multi-head Self Attention)类。这样,我们可以将多头自注意力的实现封装在一个类中,以便于管理和维护代码。这个类将包含必要的属性和方法来执行上述的多头自注意力计算,包括线性映射、缩放点积注意力的计算、softmax归一化以及最终的输出拼接和线性变换。
class MyMSA(nn.Module):
def __init__(self, d, n_heads=2):
super(MyMSA, self).__init__()
self.d = d
self.n_heads = n_heads
assert d % n_heads == 0, f"Can't divide dimension {d} into {n_heads} heads"
d_head = int(d / n_heads)
self.q_mappings = nn.ModuleList([nn.Linear(d_head, d_head) for _ in range(self.n_heads)])
self.k_mappings = nn.ModuleList([nn.Linear(d_head, d_head) for _ in range(self.n_heads)])
self.v_mappings = nn.ModuleList([nn.Linear(d_head, d_head) for _ in range(self.n_heads)])
self.d_head = d_head
self.softmax = nn.Softmax(dim=-1)
def forward(self, sequences):
# Sequences has shape (N, seq_length, token_dim)
# We go into shape (N, seq_length, n_heads, token_dim / n_heads)
# And come back to (N, seq_length, item_dim) (through concatenation)
result = []
for sequence in sequences:
seq_result = []
for head in range(self.n_heads):
q_mapping = self.q_mappings[head]
k_mapping = self.k_mappings[head]
v_mapping = self.v_mappings[head]
seq = sequence[:, head * self.d_head: (head + 1) * self.d_head]
q, k, v = q_mapping(seq), k_mapping(seq), v_mapping(seq)
attention = self.softmax(q @ k.T / (self.d_head ** 0.5))
seq_result.append(attention @ v)
result.append(torch.hstack(seq_result))
return torch.cat([torch.unsqueeze(r, dim=0) for r in result])
对于每个头,我们创建了不同的Q(查询)、K(键)和V(值)映射函数(在我们的例子中是4x4大小的方阵)。 由于我们的输入将是大小为(N, 50, 8)的序列,并且我们只使用2个头,我们将在某个时候得到一个(N, 50, 2, 4)的张量,对它使用一个nn.Linear(4, 4)模块,然后在拼接后返回到一个(N, 50, 8)的张量。
我们后面添加一个残差连接,将我们的原始(N, 50, 8)张量与LN(层归一化)和MSA(多头自注意力)后得到的(N, 50, 8)张量相加。
我们创建一个ViTBlock的类。
class MyViTBlock(nn.Module):
def __init__(self, hidden_d, n_heads, mlp_ratio=4):
super(MyViTBlock, self).__init__()
self.hidden_d = hidden_d
self.n_heads = n_heads
self.norm1 = nn.LayerNorm(hidden_d)
self.mhsa = MyMSA(hidden_d, n_heads)
def forward(self, x):
out = x + self.mhsa(self.norm1(x))
return out
有了这个自注意力机制,类别标记(每个N序列的第一个标记)现在拥有了关于所有其他标记的信息。
步骤五:encoder block(part 2/2)
对于Transformer编码器来说,剩下的只是在我们已有的内容和通过另一个LN(层归一化)以及一个MLP(多层感知机)处理当前张量后得到的内容之间建立一个简单的残差连接。MLP由两层组成,其中隐藏层通常比输入层大四倍。
class MyViTBlock(nn.Module):
def __init__(self, hidden_d, n_heads, mlp_ratio=4):
super(MyViTBlock, self).__init__()
self.hidden_d = hidden_d
self.n_heads = n_heads
self.norm1 = nn.LayerNorm(hidden_d)
self.mhsa = MyMSA(hidden_d, n_heads)
self.norm2 = nn.LayerNorm(hidden_d)
self.mlp = nn.Sequential(
nn.Linear(hidden_d, mlp_ratio * hidden_d),
nn.GELU(),
nn.Linear(mlp_ratio * hidden_d, hidden_d)
)
def forward(self, x):
out = x + self.mhsa(self.norm1(x))
out = out + self.mlp(self.norm2(out))
return out
现在ViTBlock已经准备好了,我们只需要将其插入到更大的ViT(视觉Transformer)模型中,该模型负责在Transformer块之前进行分块处理,并在之后进行分类。
我们可以拥有任意数量的Transformer块。在这个例子中,为了保持简单,我只使用了2个。我们还添加了一个参数来确定每个编码器块将使用多少个头。
class MyViT(nn.Module):
def __init__(self, chw, n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10):
# Super constructor
super(MyViT, self).__init__()
# Attributes
self.chw = chw # ( C , H , W )
self.n_patches = n_patches
self.n_blocks = n_blocks
self.n_heads = n_heads
self.hidden_d = hidden_d
# Input and patches sizes
assert chw[1] % n_patches == 0, "Input shape not entirely divisible by number of patches"
assert chw[2] % n_patches == 0, "Input shape not entirely divisible by number of patches"
self.patch_size = (chw[1] / n_patches, chw[2] / n_patches)
# 1) Linear mapper
self.input_d = int(chw[0] * self.patch_size[0] * self.patch_size[1])
self.linear_mapper = nn.Linear(self.input_d, self.hidden_d)
# 2) Learnable classification token
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
# 3) Positional embedding
self.register_buffer('positional_embeddings', get_positional_embeddings(n_patches ** 2 + 1, hidden_d), persistent=False)
# 4) Transformer encoder blocks
self.blocks = nn.ModuleList([MyViTBlock(hidden_d, n_heads) for _ in range(n_blocks)])
def forward(self, images):
# Dividing images into patches
n, c, h, w = images.shape
patches = patchify(images, self.n_patches).to(self.positional_embeddings.device)
# Running linear layer tokenization
# Map the vector corresponding to each patch to the hidden size dimension
tokens = self.linear_mapper(patches)
# Adding classification token to the tokens
tokens = torch.cat((self.class_token.expand(n, 1, -1), tokens), dim=1)
# Adding positional embedding
out = tokens + self.positional_embeddings.repeat(n, 1, 1)
# Transformer Blocks
for block in self.blocks:
out = block(out)
return out
如果我们通过我们的模型运行一个随机的(7, 1, 28, 28)张量,我们会得到一个(7, 50, 8)张量。
步骤六:分类多层感知机(MLP)
最后,我们可以从我们的N个序列中提取出分类标记(第一个标记),并使用每个标记来获得N个分类。
由于我们决定每个标记是一个8维向量,并且我们有10个可能的数字,我们可以将分类MLP实现为一个简单的8x10矩阵,并通过SoftMax函数进行激活。
class MyViT(nn.Module):
def __init__(self, chw, n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10):
# Super constructor
super(MyViT, self).__init__()
# Attributes
self.chw = chw # ( C , H , W )
self.n_patches = n_patches
self.n_blocks = n_blocks
self.n_heads = n_heads
self.hidden_d = hidden_d
# Input and patches sizes
assert chw[1] % n_patches == 0, "Input shape not entirely divisible by number of patches"
assert chw[2] % n_patches == 0, "Input shape not entirely divisible by number of patches"
self.patch_size = (chw[1] / n_patches, chw[2] / n_patches)
# 1) Linear mapper
self.input_d = int(chw[0] * self.patch_size[0] * self.patch_size[1])
self.linear_mapper = nn.Linear(self.input_d, self.hidden_d)
# 2) Learnable classification token
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
# 3) Positional embedding
self.register_buffer('positional_embeddings', get_positional_embeddings(n_patches ** 2 + 1, hidden_d), persistent=False)
# 4) Transformer encoder blocks
self.blocks = nn.ModuleList([MyViTBlock(hidden_d, n_heads) for _ in range(n_blocks)])
# 5) Classification MLPk
self.mlp = nn.Sequential(
nn.Linear(self.hidden_d, out_d),
nn.Softmax(dim=-1)
)
def forward(self, images):
# Dividing images into patches
n, c, h, w = images.shape
patches = patchify(images, self.n_patches).to(self.positional_embeddings.device)
# Running linear layer tokenization
# Map the vector corresponding to each patch to the hidden size dimension
tokens = self.linear_mapper(patches)
# Adding classification token to the tokens
tokens = torch.cat((self.class_token.expand(n, 1, -1), tokens), dim=1)
# Adding positional embedding
out = tokens + self.positional_embeddings.repeat(n, 1, 1)
# Transformer Blocks
for block in self.blocks:
out = block(out)
# Getting the classification token only
out = out[:, 0]
return self.mlp(out) # Map to output dimension, output category distribution
我们的模型的输出现在是一个(N, 10)的张量。
结果
我们在main函数中,修改我们的model定义为
model = MyViT((1, 28, 28), n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10).to(device)
完整的代码为:
import numpy as np
import torch
import torch.nn as nn
from torch.nn import CrossEntropyLoss
from torch.optim import Adam
from torch.utils.data import DataLoader
from torchvision.datasets.mnist import MNIST
from torchvision.transforms import ToTensor
from tqdm import tqdm, trange
np.random.seed(0)
torch.manual_seed(0)
def patchify(images, n_patches):
n, c, h, w = images.shape
assert h == w, "Patchify method is implemented for square images only"
patches = torch.zeros(n, n_patches**2, h * w * c // n_patches**2)
patch_size = h // n_patches
for idx, image in enumerate(images):
for i in range(n_patches):
for j in range(n_patches):
patch = image[
:,
i * patch_size : (i + 1) * patch_size,
j * patch_size : (j + 1) * patch_size,
]
patches[idx, i * n_patches + j] = patch.flatten()
return patches
class MyMSA(nn.Module):
def __init__(self, d, n_heads=2):
super(MyMSA, self).__init__()
self.d = d
self.n_heads = n_heads
assert d % n_heads == 0, f"Can't divide dimension {d} into {n_heads} heads"
d_head = int(d / n_heads)
self.q_mappings = nn.ModuleList(
[nn.Linear(d_head, d_head) for _ in range(self.n_heads)]
)
self.k_mappings = nn.ModuleList(
[nn.Linear(d_head, d_head) for _ in range(self.n_heads)]
)
self.v_mappings = nn.ModuleList(
[nn.Linear(d_head, d_head) for _ in range(self.n_heads)]
)
self.d_head = d_head
self.softmax = nn.Softmax(dim=-1)
def forward(self, sequences):
# Sequences has shape (N, seq_length, token_dim)
# We go into shape (N, seq_length, n_heads, token_dim / n_heads)
# And come back to (N, seq_length, item_dim) (through concatenation)
result = []
for sequence in sequences:
seq_result = []
for head in range(self.n_heads):
q_mapping = self.q_mappings[head]
k_mapping = self.k_mappings[head]
v_mapping = self.v_mappings[head]
seq = sequence[:, head * self.d_head : (head + 1) * self.d_head]
q, k, v = q_mapping(seq), k_mapping(seq), v_mapping(seq)
attention = self.softmax(q @ k.T / (self.d_head**0.5))
seq_result.append(attention @ v)
result.append(torch.hstack(seq_result))
return torch.cat([torch.unsqueeze(r, dim=0) for r in result])
class MyViTBlock(nn.Module):
def __init__(self, hidden_d, n_heads, mlp_ratio=4):
super(MyViTBlock, self).__init__()
self.hidden_d = hidden_d
self.n_heads = n_heads
self.norm1 = nn.LayerNorm(hidden_d)
self.mhsa = MyMSA(hidden_d, n_heads)
self.norm2 = nn.LayerNorm(hidden_d)
self.mlp = nn.Sequential(
nn.Linear(hidden_d, mlp_ratio * hidden_d),
nn.GELU(),
nn.Linear(mlp_ratio * hidden_d, hidden_d),
)
def forward(self, x):
out = x + self.mhsa(self.norm1(x))
out = out + self.mlp(self.norm2(out))
return out
class MyViT(nn.Module):
def __init__(self, chw, n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10):
# Super constructor
super(MyViT, self).__init__()
# Attributes
self.chw = chw # ( C , H , W )
self.n_patches = n_patches
self.n_blocks = n_blocks
self.n_heads = n_heads
self.hidden_d = hidden_d
# Input and patches sizes
assert (
chw[1] % n_patches == 0
), "Input shape not entirely divisible by number of patches"
assert (
chw[2] % n_patches == 0
), "Input shape not entirely divisible by number of patches"
self.patch_size = (chw[1] / n_patches, chw[2] / n_patches)
# 1) Linear mapper
self.input_d = int(chw[0] * self.patch_size[0] * self.patch_size[1])
self.linear_mapper = nn.Linear(self.input_d, self.hidden_d)
# 2) Learnable classification token
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
# 3) Positional embedding
self.register_buffer(
"positional_embeddings",
get_positional_embeddings(n_patches**2 + 1, hidden_d),
persistent=False,
)
# 4) Transformer encoder blocks
self.blocks = nn.ModuleList(
[MyViTBlock(hidden_d, n_heads) for _ in range(n_blocks)]
)
# 5) Classification MLPk
self.mlp = nn.Sequential(nn.Linear(self.hidden_d, out_d), nn.Softmax(dim=-1))
def forward(self, images):
# Dividing images into patches
n, c, h, w = images.shape
patches = patchify(images, self.n_patches).to(self.positional_embeddings.device)
# Running linear layer tokenization
# Map the vector corresponding to each patch to the hidden size dimension
tokens = self.linear_mapper(patches)
# Adding classification token to the tokens
tokens = torch.cat((self.class_token.expand(n, 1, -1), tokens), dim=1)
# Adding positional embedding
out = tokens + self.positional_embeddings.repeat(n, 1, 1)
# Transformer Blocks
for block in self.blocks:
out = block(out)
# Getting the classification token only
out = out[:, 0]
return self.mlp(out) # Map to output dimension, output category distribution
def get_positional_embeddings(sequence_length, d):
result = torch.ones(sequence_length, d)
for i in range(sequence_length):
for j in range(d):
result[i][j] = (
np.sin(i / (10000 ** (j / d)))
if j % 2 == 0
else np.cos(i / (10000 ** ((j - 1) / d)))
)
return result
def main():
# Loading data
transform = ToTensor()
train_set = MNIST(
root="./../datasets", train=True, download=True, transform=transform
)
test_set = MNIST(
root="./../datasets", train=False, download=True, transform=transform
)
train_loader = DataLoader(train_set, shuffle=True, batch_size=128)
test_loader = DataLoader(test_set, shuffle=False, batch_size=128)
# Defining model and training options
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(
"Using device: ",
device,
f"({torch.cuda.get_device_name(device)})" if torch.cuda.is_available() else "",
)
model = MyViT(
(1, 28, 28), n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10
).to(device)
N_EPOCHS = 5
LR = 0.005
# Training loop
optimizer = Adam(model.parameters(), lr=LR)
criterion = CrossEntropyLoss()
for epoch in trange(N_EPOCHS, desc="Training"):
train_loss = 0.0
for batch in tqdm(
train_loader, desc=f"Epoch {epoch + 1} in training", leave=False
):
x, y = batch
x, y = x.to(device), y.to(device)
y_hat = model(x)
loss = criterion(y_hat, y)
train_loss += loss.detach().cpu().item() / len(train_loader)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}/{N_EPOCHS} loss: {train_loss:.2f}")
# Test loop
with torch.no_grad():
correct, total = 0, 0
test_loss = 0.0
for batch in tqdm(test_loader, desc="Testing"):
x, y = batch
x, y = x.to(device), y.to(device)
y_hat = model(x)
loss = criterion(y_hat, y)
test_loss += loss.detach().cpu().item() / len(test_loader)
correct += torch.sum(torch.argmax(y_hat, dim=1) == y).detach().cpu().item()
total += len(x)
print(f"Test loss: {test_loss:.2f}")
print(f"Test accuracy: {correct / total * 100:.2f}%")
if __name__ == "__main__":
main()
Using device: cpu
Training: 0%| | 0/5 [00:00<?, ?it/sEpoch 1/5 loss: 2.11
Training: 20%|█████████████▌ | 1/5 [00:37<02:31, 37.76s/itEpoch 2/5 loss: 1.84
Training: 40%|███████████████████████████▏ | 2/5 [01:16<01:54, 38.13s/itEpoch 3/5 loss: 1.76
Training: 60%|████████████████████████████████████████▊ | 3/5 [01:54<01:16, 38.11s/itEpoch 4/5 loss: 1.72
Training: 80%|██████████████████████████████████████████████████████▍ | 4/5 [02:32<00:38, 38.11s/itEpoch 5/5 loss: 1.71
Training: 100%|████████████████████████████████████████████████████████████████████| 5/5 [03:11<00:00, 38.27s/it]
Testing: 100%|███████████████████████████████████████████████████████████████████| 79/79 [00:03<00:00, 23.90it/s]
Test loss: 1.69
Test accuracy: 77.38%
经过5个epoch的训练,我们的accuracy就到了77%。