超分论文ESPCN代码实现和效果对比
Published:
在前面一篇中,我们介绍了ESPCN论文的基本原理。这篇我们来看下具体的代码实现和效果。
代码实现
训练集和验证集是从VOC2012数据集采样得来的。训练集有16700个样本,验证集有425个样本。下载训练集和验证集链接:links,验证码:5tzp。
新建一个文件夹ESPCN,ESPCN文件夹下创建data文件夹,然后将下载的文件放在data文件夹下,完整的路径为 ESPCN/data/VOC2012。
然后执行下面的文件。
python data_utils.py
其中,可选参数–upscale_factor,默认是3。
data_util.py
import argparse
import os
from os import listdir
from os.path import join
from PIL import Image
from torch.utils.data.dataset import Dataset
from torchvision.transforms import Compose, CenterCrop, Resize
from tqdm import tqdm
import matplotlib.pyplot as plt
def is_image_file(filename):
return any(filename.endswith(extension) for extension in ['.png', '.jpg', '.jpeg', '.JPG', '.JPEG', '.PNG'])
def is_video_file(filename):
return any(filename.endswith(extension) for extension in ['.mp4', '.avi', '.mpg', '.mkv', '.wmv', '.flv'])
def calculate_valid_crop_size(crop_size, upscale_factor):
return crop_size - (crop_size % upscale_factor)
def input_transform(crop_size, upscale_factor):
return Compose([
CenterCrop(crop_size),
Resize(crop_size // upscale_factor, interpolation=Image.BICUBIC)
])
def target_transform(crop_size):
return Compose([
CenterCrop(crop_size)
])
class DatasetFromFolder(Dataset):
def __init__(self, dataset_dir, upscale_factor, input_transform=None, target_transform=None):
super(DatasetFromFolder, self).__init__()
self.image_dir = dataset_dir + '/SRF_' + str(upscale_factor) + '/data'
self.target_dir = dataset_dir + '/SRF_' + str(upscale_factor) + '/target'
self.image_filenames = [join(self.image_dir, x) for x in listdir(self.image_dir) if is_image_file(x)]
self.target_filenames = [join(self.target_dir, x) for x in listdir(self.target_dir) if is_image_file(x)]
self.input_transform = input_transform
self.target_transform = target_transform
def __getitem__(self, index):
img=Image.open(self.image_filenames[index]).convert('YCbCr')
img_target = Image.open(self.target_filenames[index]).convert('YCbCr')
image, _, _ = img.split()
target, _, _ = img_target.split()
if self.input_transform:
image = self.input_transform(image)
if self.target_transform:
target = self.target_transform(target)
return image, target
def __len__(self):
return len(self.image_filenames)
def generate_dataset(data_type, upscale_factor):
images_name = [x for x in listdir('data/VOC2012/' + data_type) if is_image_file(x)]
crop_size = calculate_valid_crop_size(256, upscale_factor)
lr_transform = input_transform(crop_size, upscale_factor)
hr_transform = target_transform(crop_size)
root = 'data/' + data_type
if not os.path.exists(root):
os.makedirs(root)
path = root + '/SRF_' + str(upscale_factor)
if not os.path.exists(path):
os.makedirs(path)
image_path = path + '/data'
if not os.path.exists(image_path):
os.makedirs(image_path)
target_path = path + '/target'
if not os.path.exists(target_path):
os.makedirs(target_path)
for image_name in tqdm(images_name, desc='generate ' + data_type + ' dataset with upscale factor = '
+ str(upscale_factor) + ' from VOC2012'):
image = Image.open('data/VOC2012/' + data_type + '/' + image_name)
target = image.copy()
image = lr_transform(image)
target = hr_transform(target)
image.save(image_path + '/' + image_name)
target.save(target_path + '/' + image_name)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Generate Super Resolution Dataset')
parser.add_argument('--upscale_factor', default=3, type=int, help='super resolution upscale factor')
opt = parser.parse_args()
UPSCALE_FACTOR = opt.upscale_factor
generate_dataset(data_type='train', upscale_factor=UPSCALE_FACTOR)
generate_dataset(data_type='val', upscale_factor=UPSCALE_FACTOR)
这样就生成了训练超分网络使用的低分辨率和高分辨率图像对。基本原理就是直接使用插值的方法,从原图得到低分辨率的图像。
然后我们定义网络模型。
model.py
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self, upscale_factor):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))
self.conv2 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))
self.conv3 = nn.Conv2d(32, 1 * (upscale_factor ** 2), (3, 3), (1, 1), (1, 1))
self.pixel_shuffle = nn.PixelShuffle(upscale_factor)
def forward(self, x):
x = F.tanh(self.conv1(x))
x = F.tanh(self.conv2(x))
x = F.sigmoid(self.pixel_shuffle(self.conv3(x)))
return x
if __name__ == "__main__":
model = Net(upscale_factor=3)
print(model)
根据论文的介绍,网络模型的实现相对简单。
我们在评估模型效果时,用到了PSNR作为指标,我们这里实现一下PSNR的计算过程。
psnrmeter.py
from math import log10
import torch
from torchnet.meter import meter
class PSNRMeter(meter.Meter):
def __init__(self):
super(PSNRMeter, self).__init__()
self.reset()
def reset(self):
self.n = 0
self.sesum = 0.0
def add(self, output, target):
if not torch.is_tensor(output) and not torch.is_tensor(target):
output = torch.from_numpy(output)
target = torch.from_numpy(target)
output = output.cpu()
target = target.cpu()
self.n += output.numel()
self.sesum += torch.sum((output - target) ** 2)
def value(self):
mse = self.sesum / max(1, self.n)
psnr = 10 * log10(1 / mse)
return psnr
这里要先安装torchnet。
最后,编写训练代码。
train.py
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import MultiStepLR
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torchvision.transforms as transforms
from tqdm import tqdm
import platform
from data_utils import DatasetFromFolder
from model import Net
from psnrmeter import PSNRMeter
if platform.system() == 'Darwin':
# MacOS系统,使用MPS后端
if torch.backends.mps.is_available():
device = torch.device('mps')
else:
device = torch.device('cpu')
else:
# Linux或Windows系统,使用CUDA后端
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
def train_epoch(model, loader, optimizer, criterion, device):
model.train()
total_loss = 0
for data, target in tqdm(loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(loader)
def validate_epoch(model, loader, criterion, device, psnr_meter):
model.eval()
total_loss = 0
with torch.no_grad():
for data, target in tqdm(loader):
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
total_loss += loss.item()
psnr_meter.add(output, target)
return total_loss / len(loader), psnr_meter.value()
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Train Super Resolution')
parser.add_argument('--upscale_factor', default=3, type=int, help='super resolution upscale factor')
parser.add_argument('--num_epochs', default=100, type=int, help='super resolution epochs number')
opt = parser.parse_args()
UPSCALE_FACTOR = opt.upscale_factor
NUM_EPOCHS = opt.num_epochs
train_set = DatasetFromFolder('data/train', upscale_factor=UPSCALE_FACTOR, input_transform=transforms.ToTensor(),
target_transform=transforms.ToTensor())
val_set = DatasetFromFolder('data/val', upscale_factor=UPSCALE_FACTOR, input_transform=transforms.ToTensor(),
target_transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_set, num_workers=4, batch_size=64, shuffle=True)
val_loader = DataLoader(dataset=val_set, num_workers=4, batch_size=64, shuffle=False)
model = Net(upscale_factor=UPSCALE_FACTOR).to(device)
criterion = nn.MSELoss().to(device)
psnr_meter = PSNRMeter()
optimizer = optim.Adam(model.parameters(), lr=1e-2)
scheduler = MultiStepLR(optimizer, milestones=[30, 80], gamma=0.1)
writer = SummaryWriter('runs/super_resolution')
for epoch in range(NUM_EPOCHS):
train_loss = train_epoch(model, train_loader, optimizer, criterion, device)
val_loss, val_psnr = validate_epoch(model, val_loader, criterion, device, psnr_meter)
scheduler.step()
print(f'[Epoch {epoch+1}/{NUM_EPOCHS}] Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}, Val PSNR: {val_psnr:.2f} db')
# # 记录到TensorBoard
writer.add_scalar('Train Loss', train_loss, epoch)
writer.add_scalar('Val Loss', val_loss, epoch)
writer.add_scalar('Val PSNR', val_psnr, epoch)
# 保存模型
torch.save(model.state_dict(), f'epochs/epoch_{UPSCALE_FACTOR}_{epoch}.pt')
writer.close()
训练完成后,我们看一下tensorboard的结果。
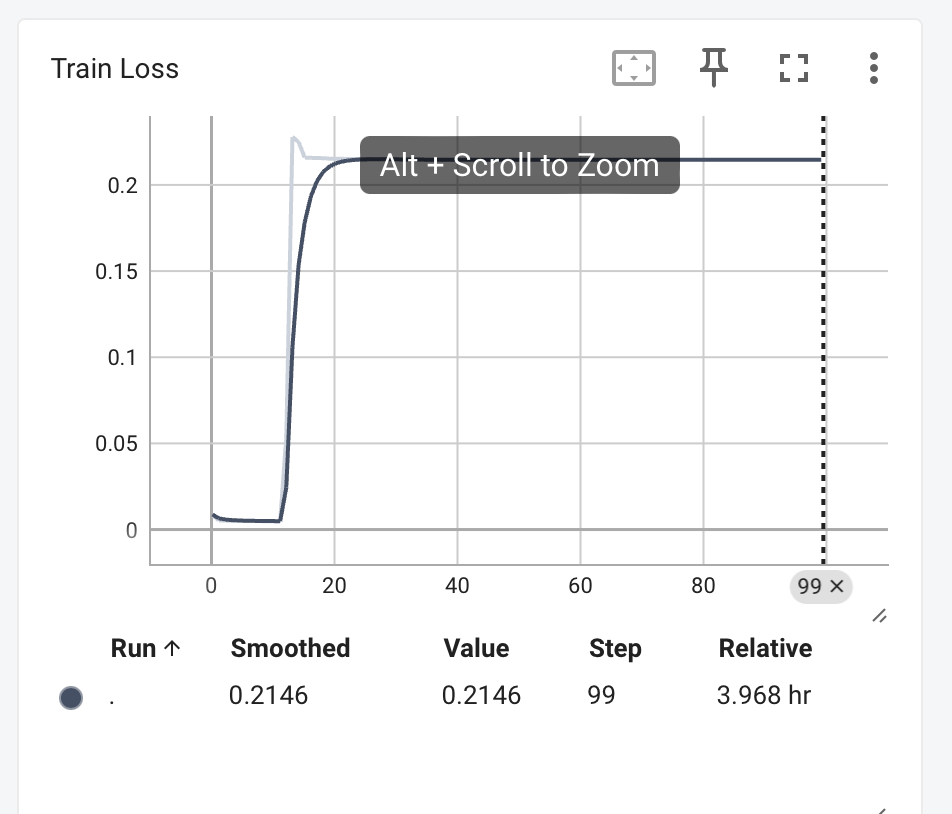
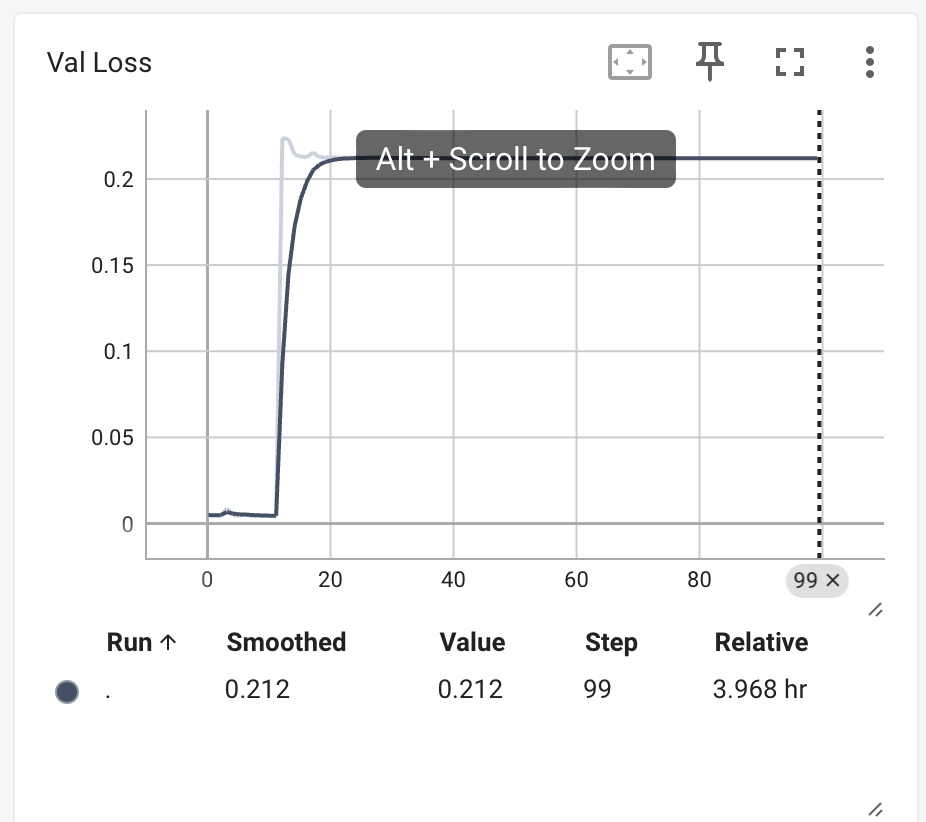
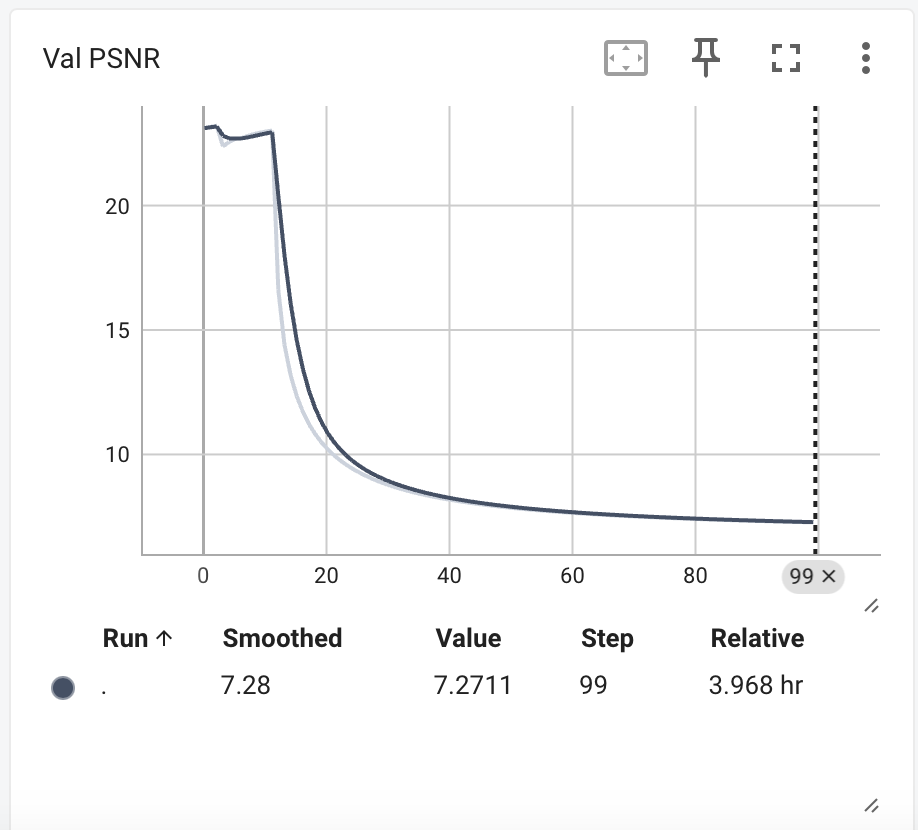
可以看到train val loss都先降后增,psnr先增高了一下然后降低。训练过程存在过拟合。
峰值信噪比(Peak Signal-to-Noise Ratio,简称PSNR)是图像和视频压缩领域中常用的一个客观图像质量评价指标。它通过比较原始图像和退化(例如压缩、噪声干扰等)后的图像来评估图像质量。PSNR是基于均方误差(Mean Squared Error,简称MSE)来定义的,计算公式为: 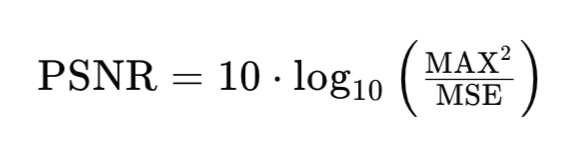
其中,MAX是图像像素点可能的最大数值,对于8位图像,MAX通常是255。MSE是原始图像与退化图像之间的均方误差,计算公式为:
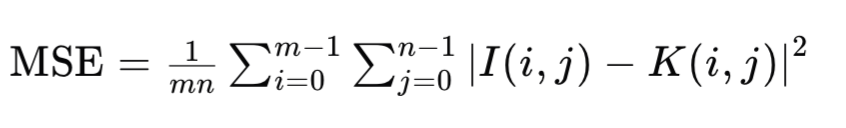
这里,I和K分别代表原始图像和退化图像,m和n分别为图像的行数和列数。
PSNR的值越高,表示图像质量越好,失真越小。在实际应用中,PSNR通常用于图像压缩、去噪、超分辨率等图像处理任务的性能评估。它提供了一个量化的方法来比较不同算法的效果。然而,PSNR主要基于像素级误差,可能无法完全反映人眼对图像质量的感知。在某些情况下,即使PSNR值很高,人眼也可能察觉到图像的失真。因此,研究人员和工程师经常结合其他指标,如结构相似性指数(SSIM),来提供更全面的图像质量评估。
在实际应用中,PSNR也存在局限性,如对噪声敏感、不适用于所有图像类型、计算复杂等。为了克服这些局限性,研究人员提出了多种替代方法,如结构相似性指标(SSIM)、峰值信噪比(PSNR)的对数变换、多尺度结构相似性指标(MSSIM)、感知图像质量指标(PIQM)和全参考图像质量评估(FR-IQA)等。
在图像压缩中,PSNR可以用来评估压缩算法的效果,压缩后的图像与原始图像之间的PSNR值可以量化压缩过程中质量的损失。在图像增强中,PSNR可以辅助评估增强后图像的质量,尽管它可能不完全符合人眼对图像质量的感知。在深度学习模型评估中,PSNR常作为损失函数的一部分或性能评估指标,尤其是在训练生成对抗网络(GANs)进行图像生成时。
总的来说,PSNR是一个简单且广泛使用的图像质量评价指标,但它主要基于数学计算,可能无法完全符合人眼的视觉感知。因此,在某些应用中,可能需要结合其他指标来更全面地评估图像质量。
所以,我们上面的训练过程并不是较优的结果。还可以有多种手段来优化,比如加入SSIM loss等。以及优化学习的参数等。
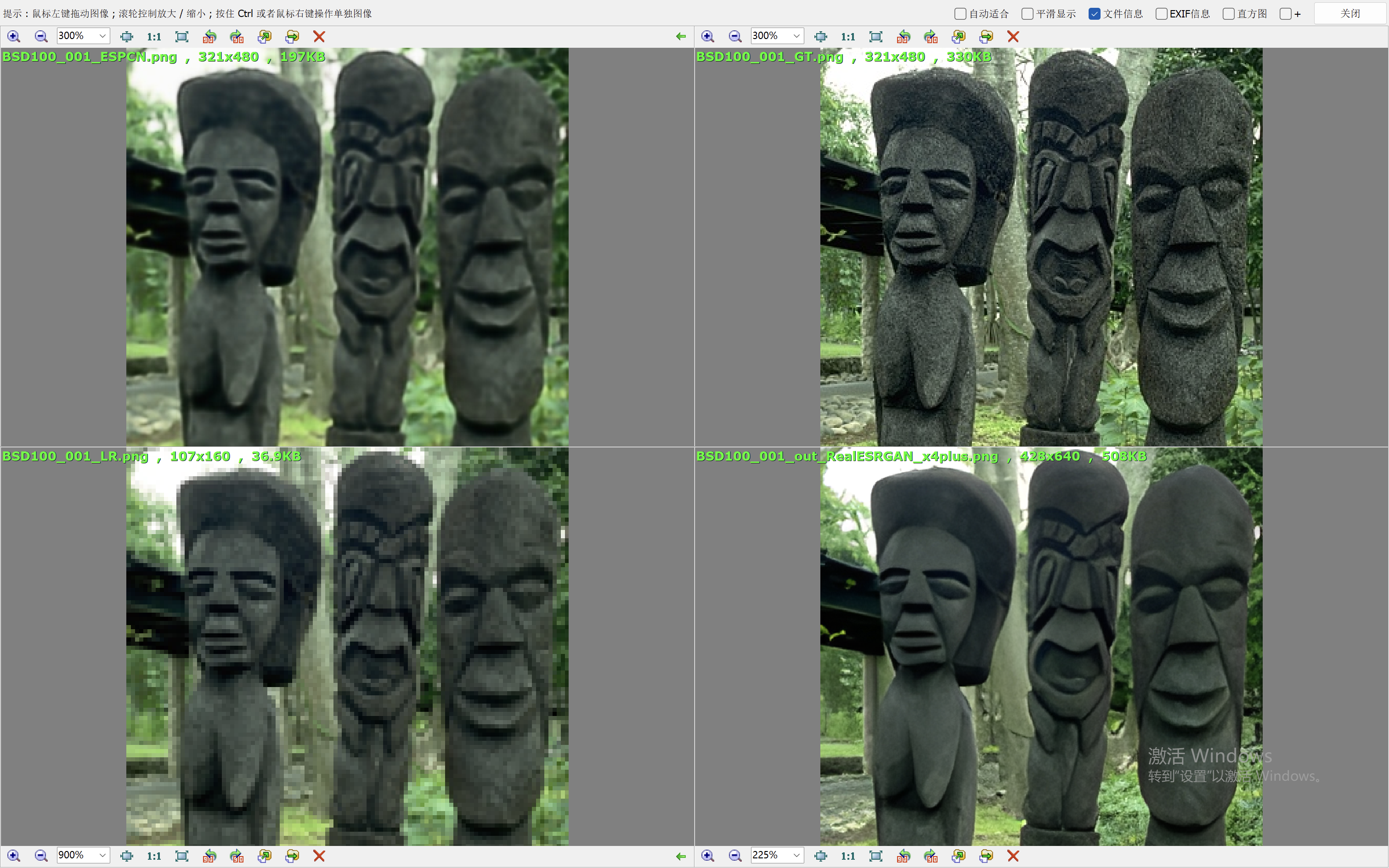
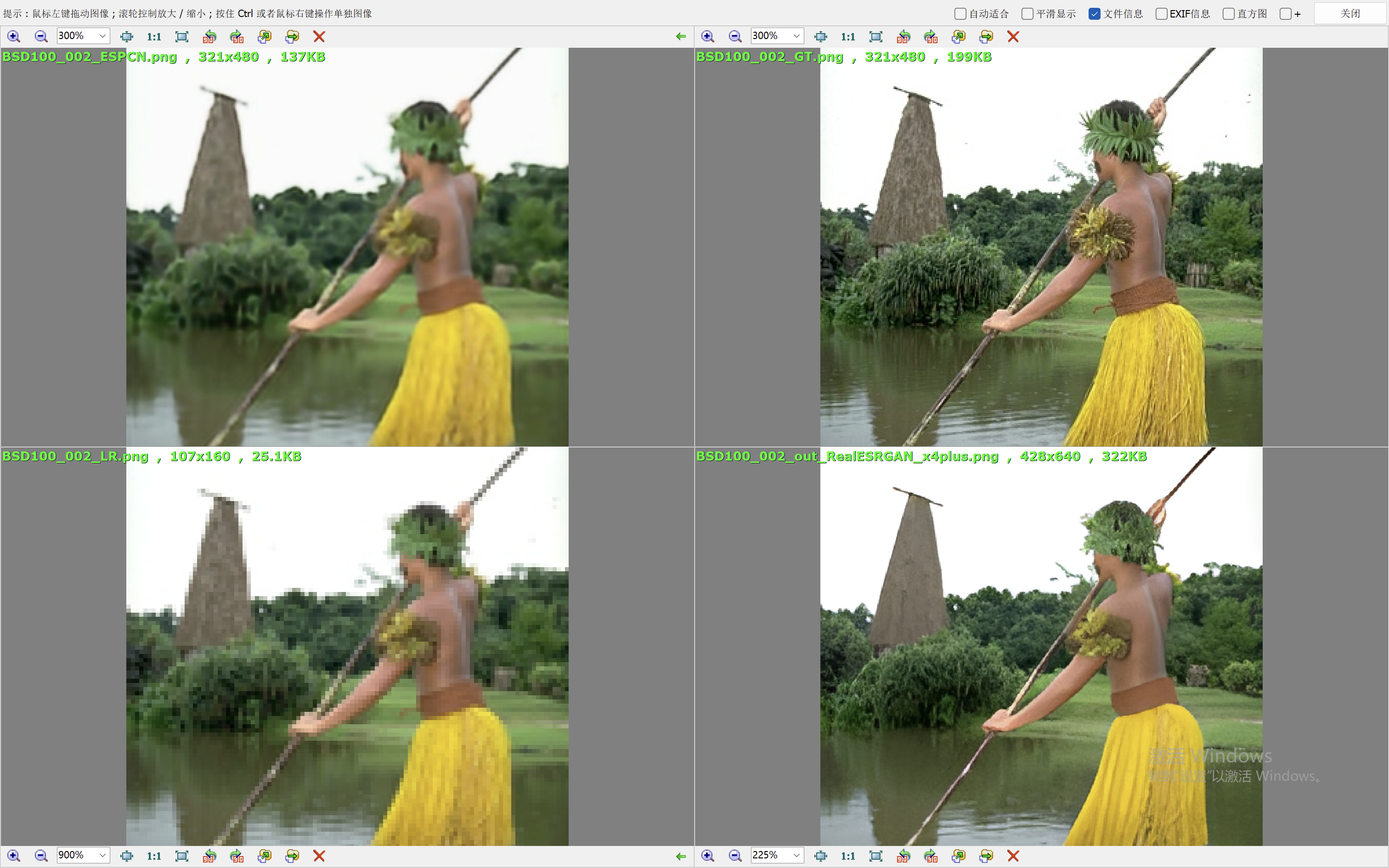
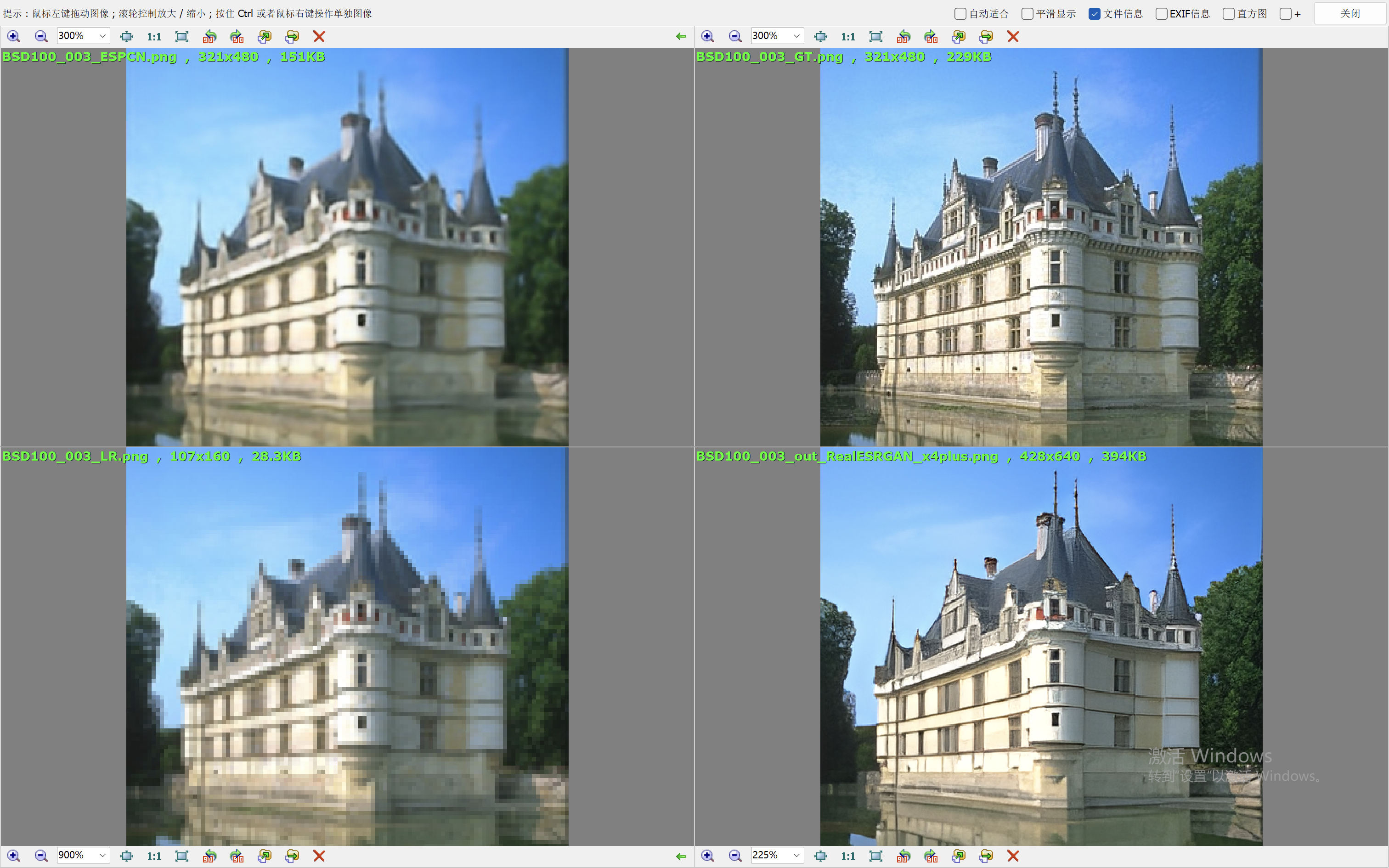
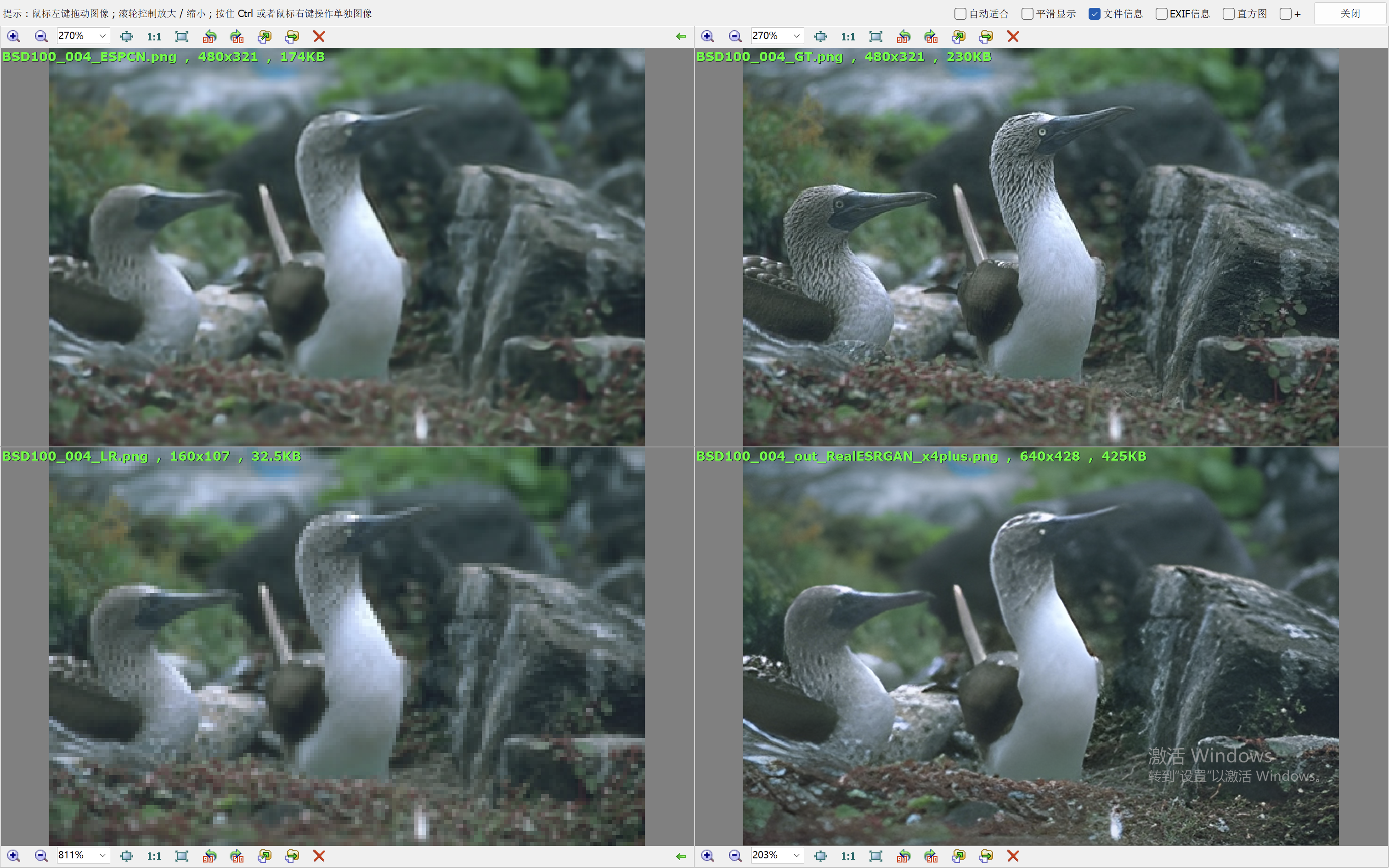
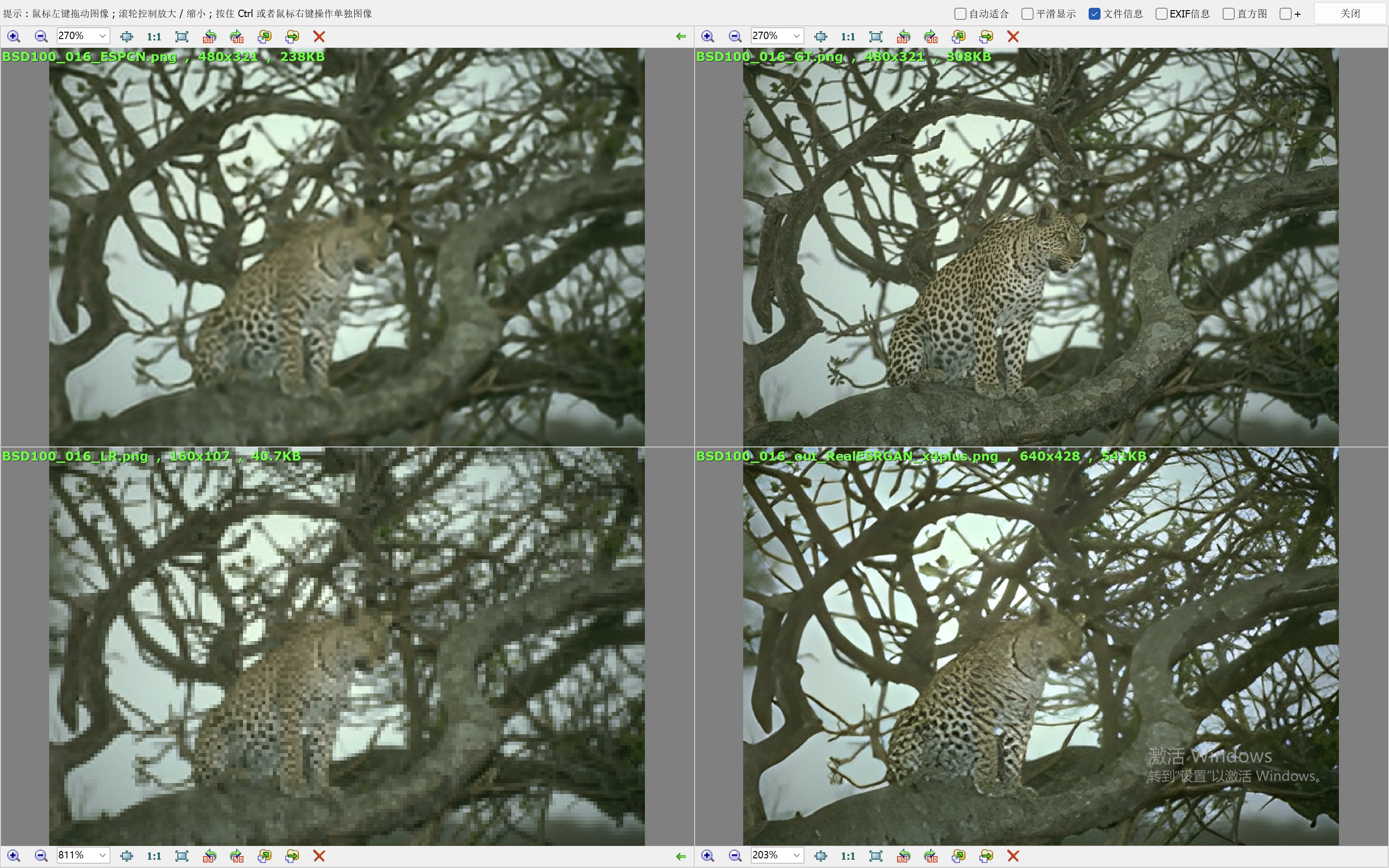
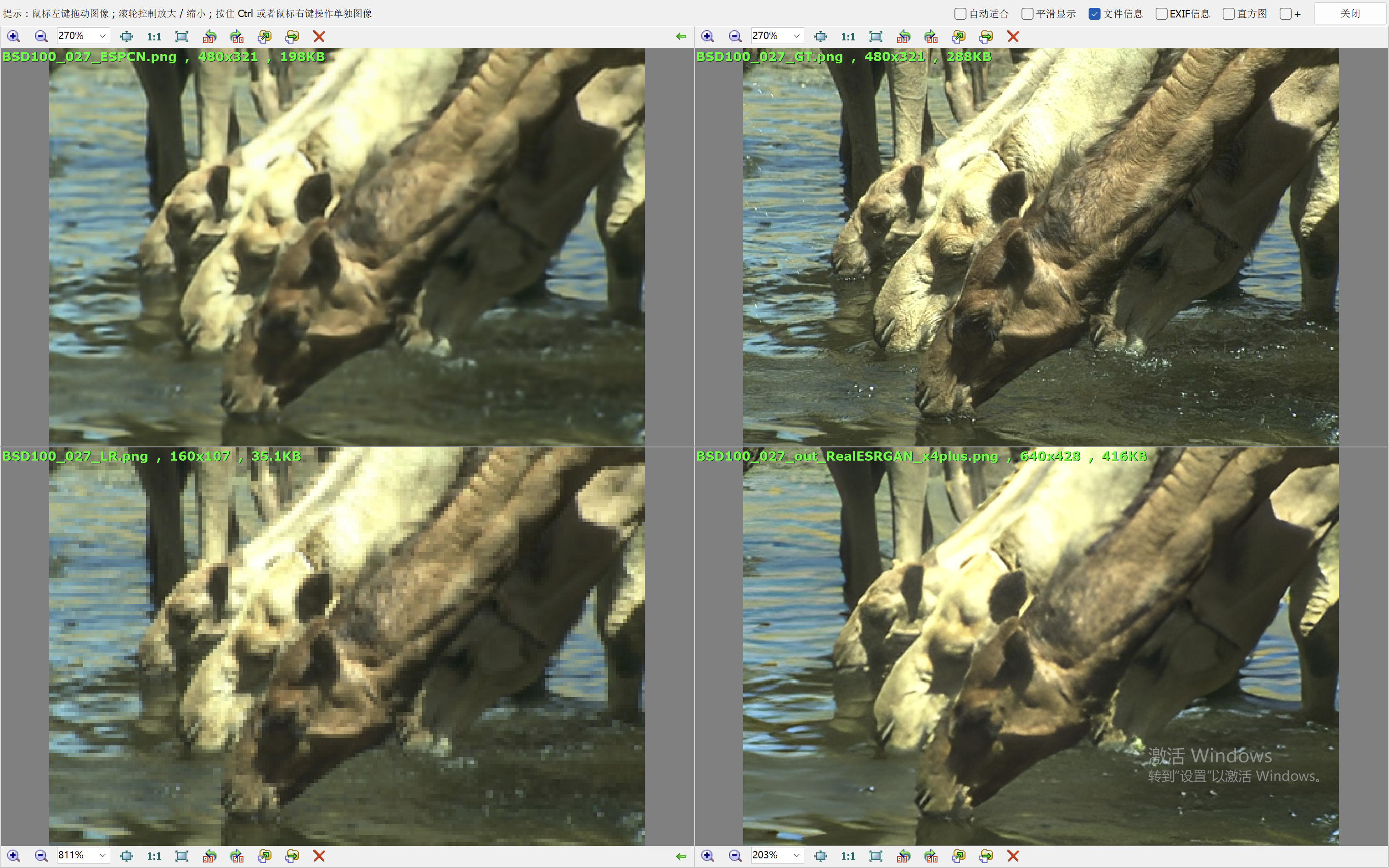
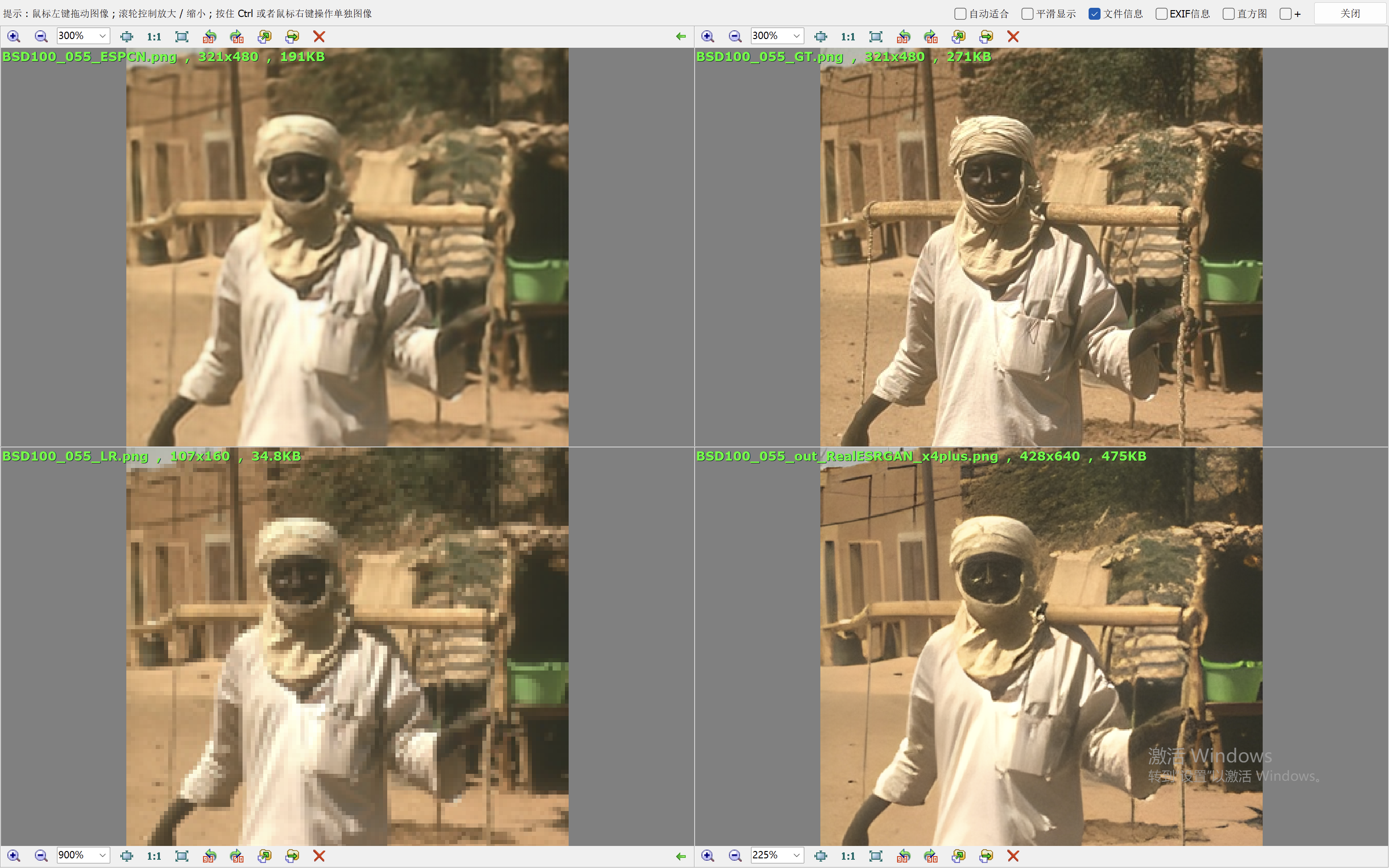
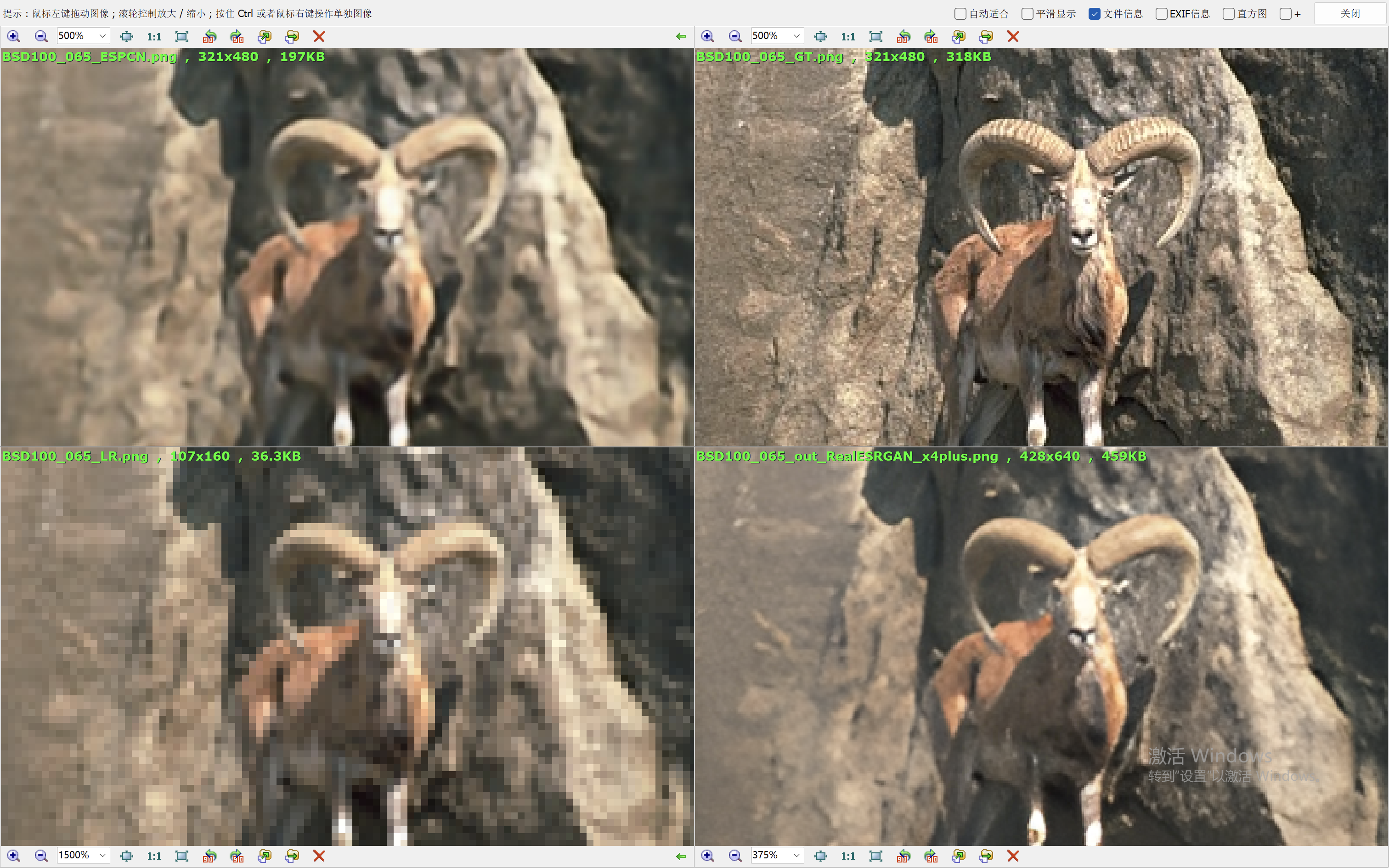
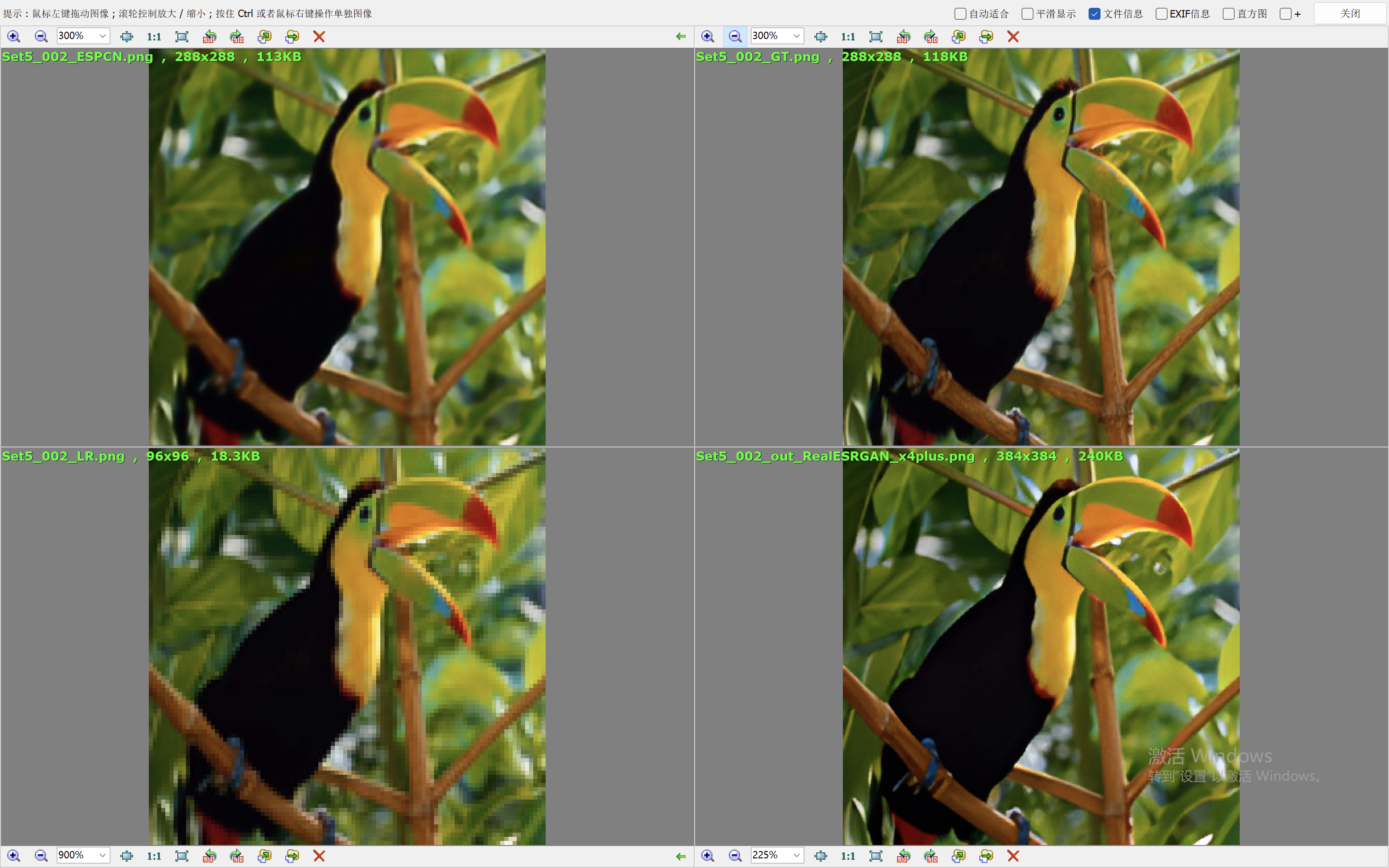
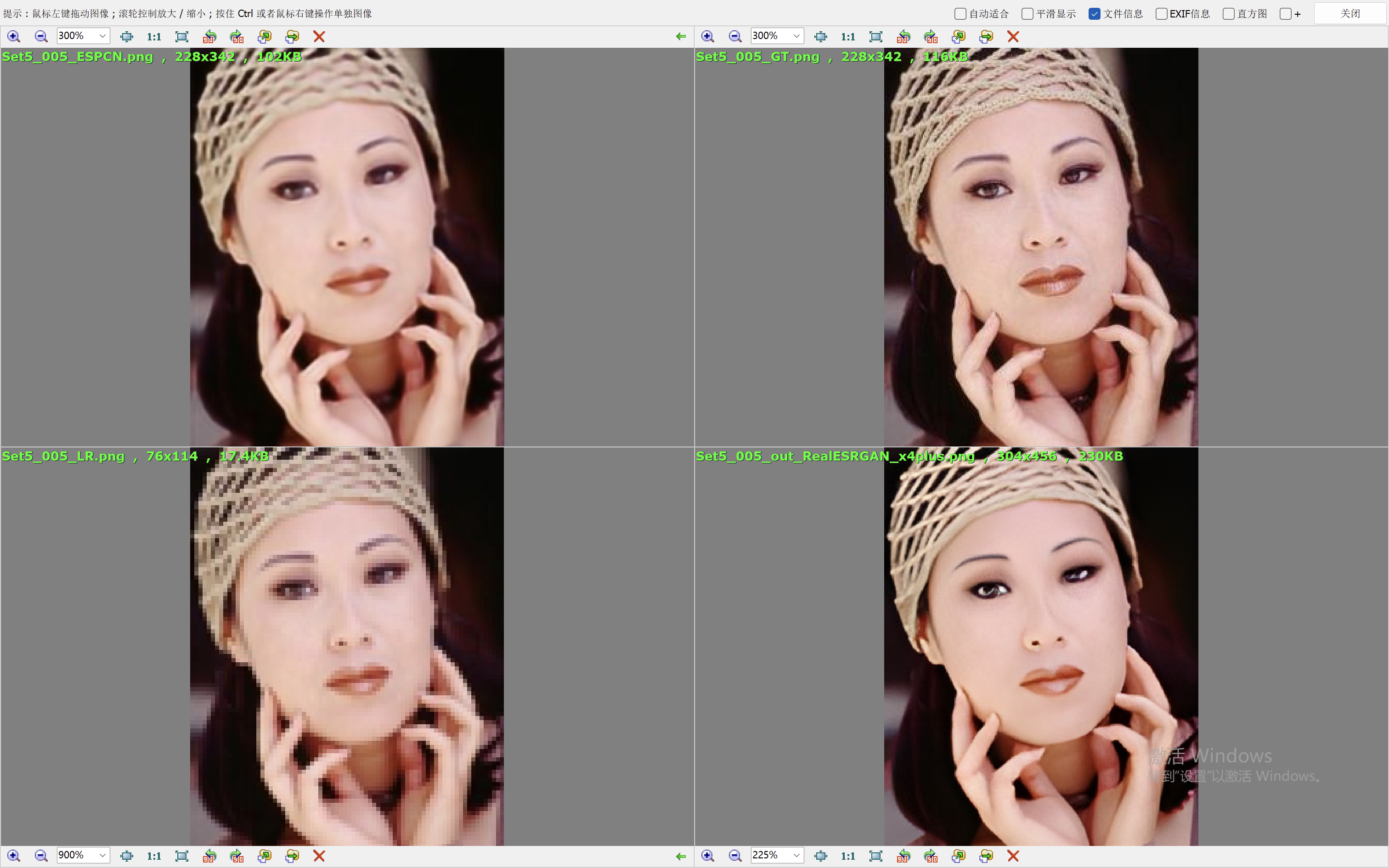
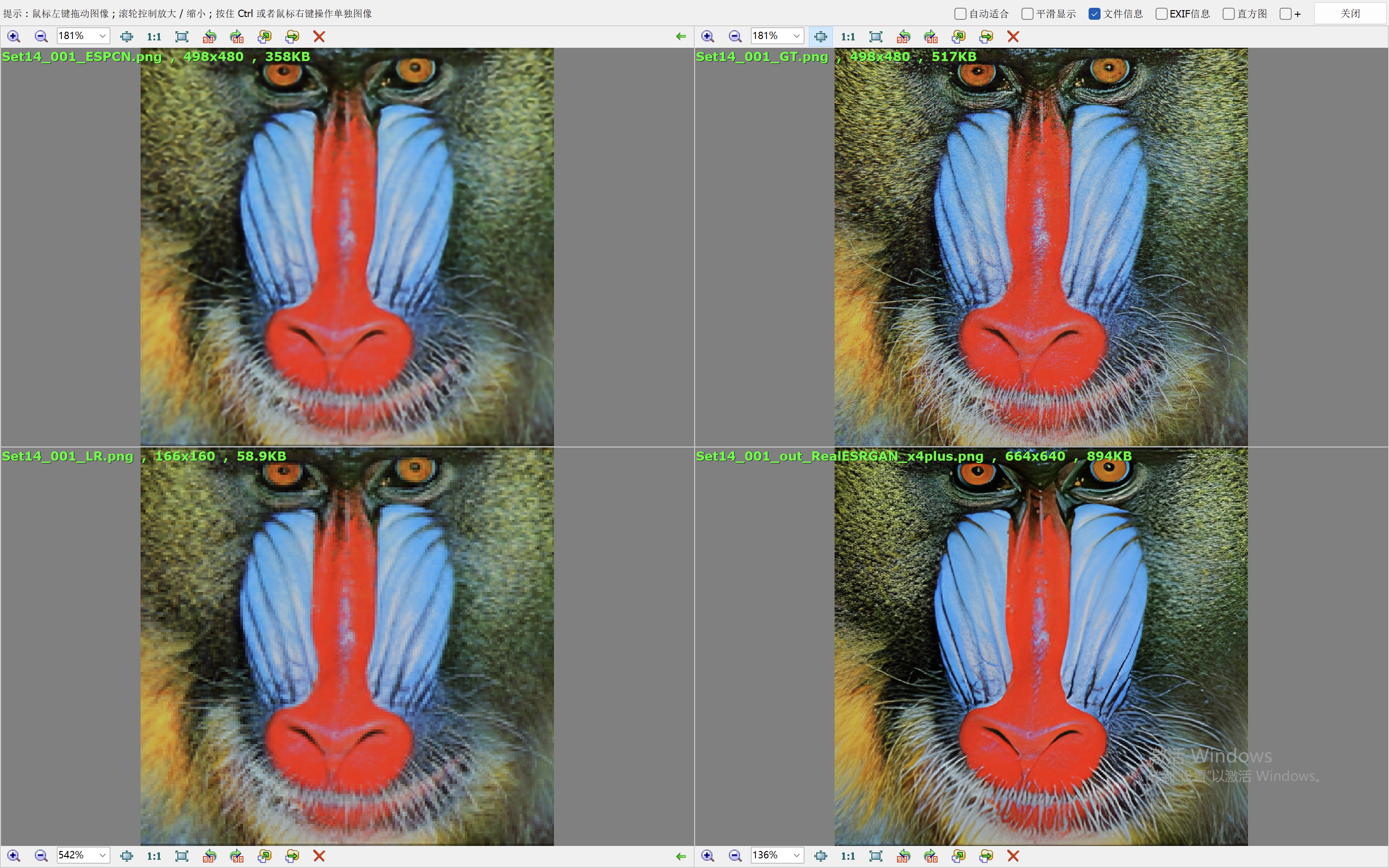
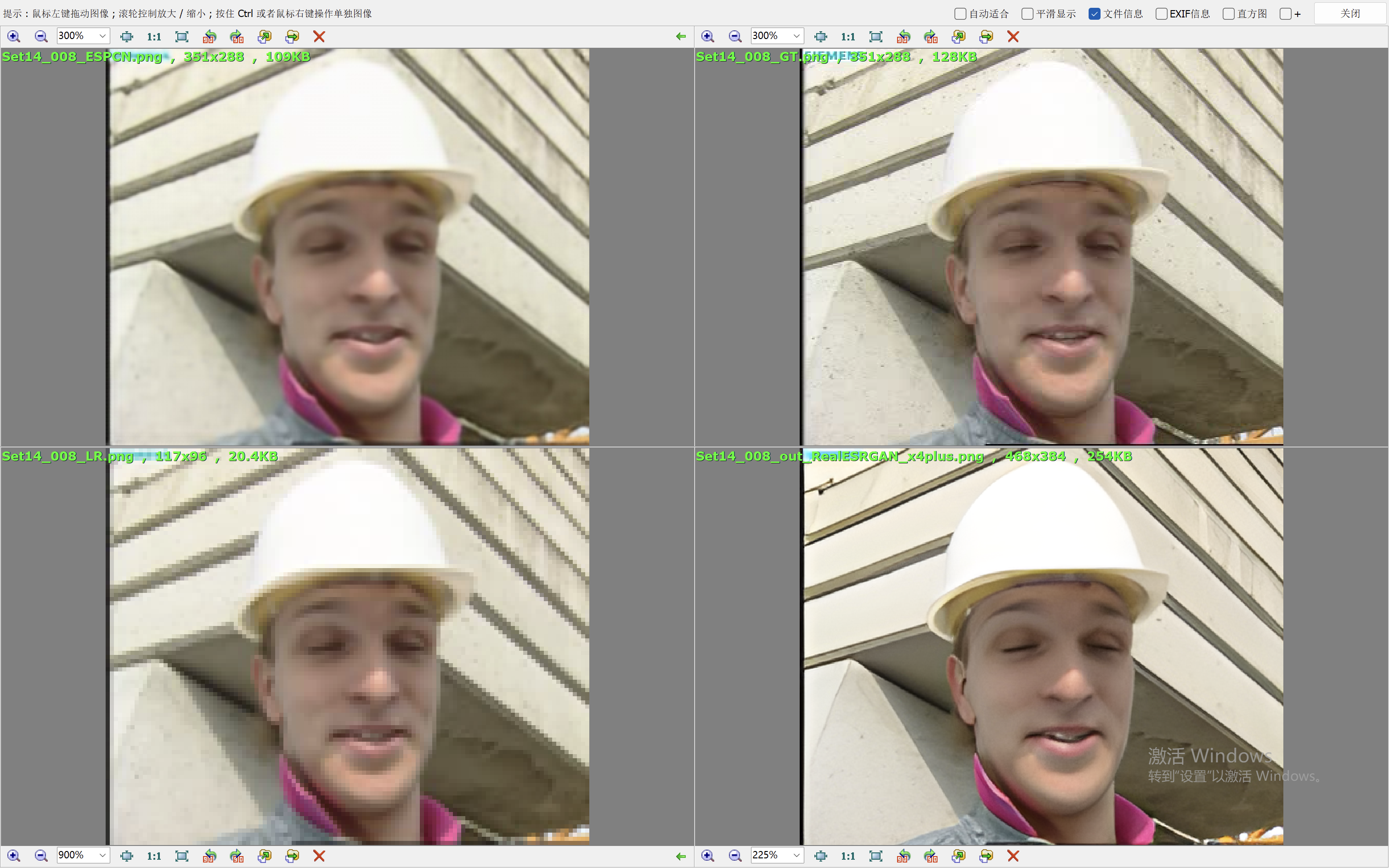
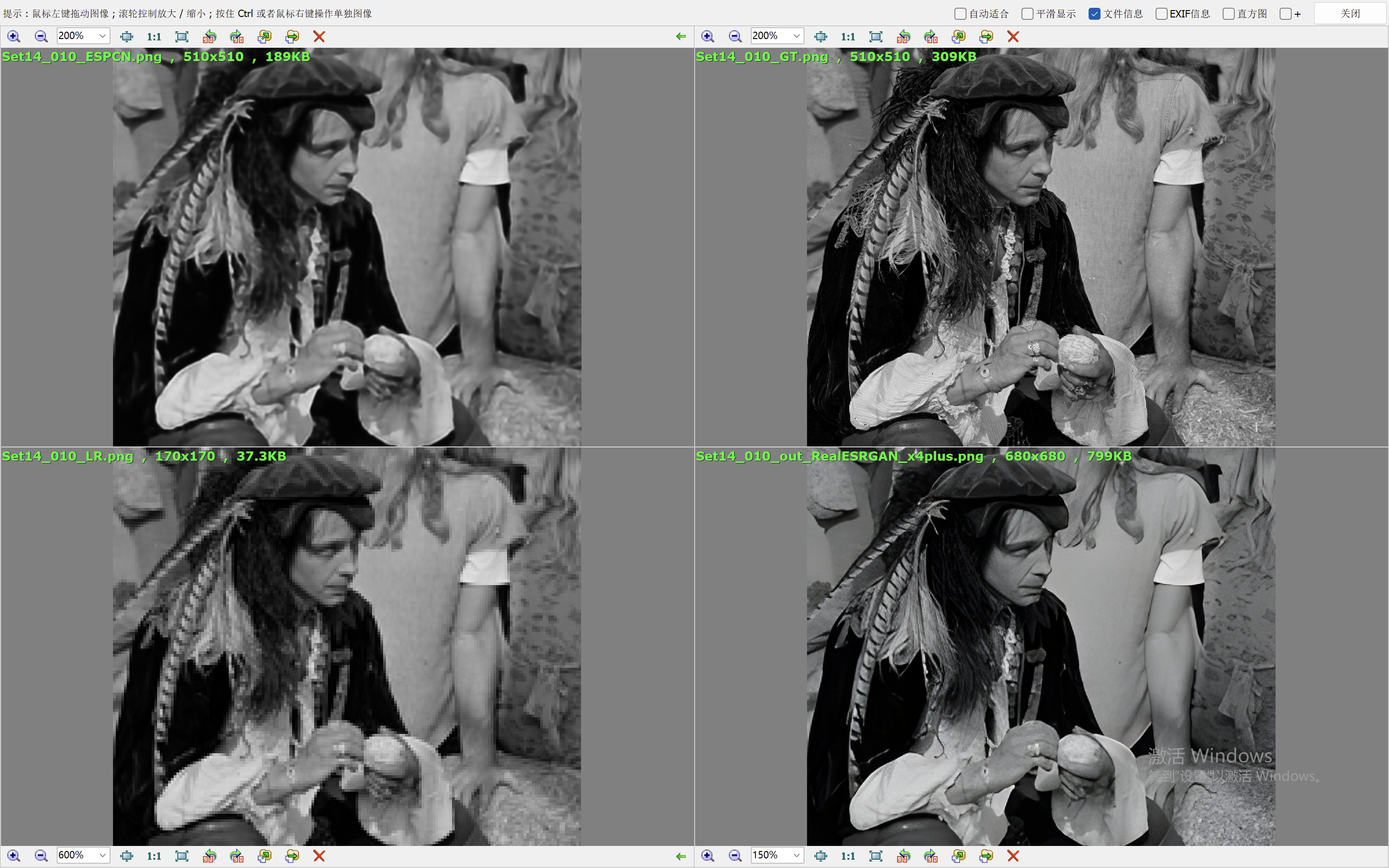
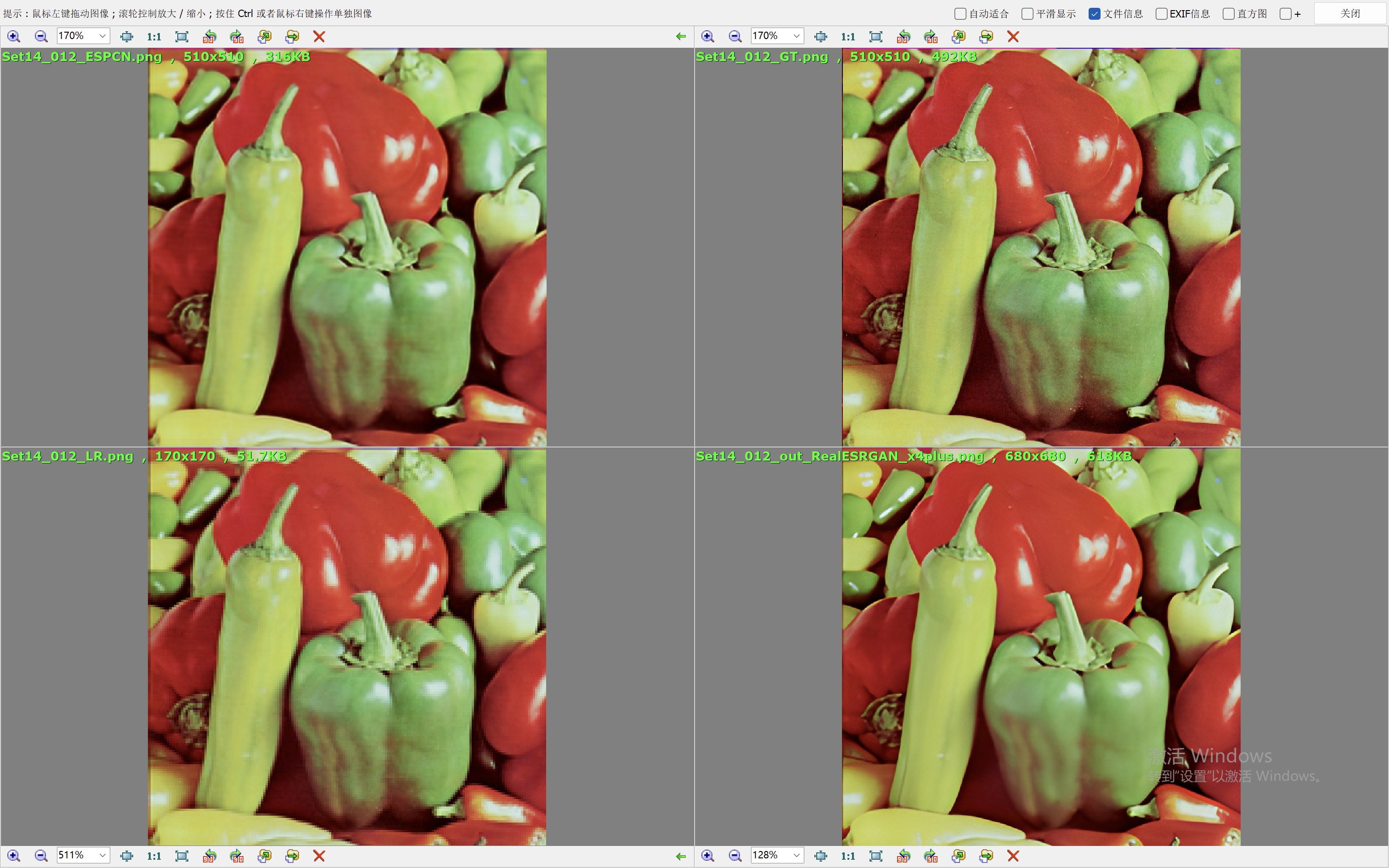
我们这里就简单的取val loss最低的一个模型来验证效果。我们和Real-ESRGAN(我们在前面的blog中也说明了它的原理和效果表现)来比较效果。
下面的效果对比图中,左上为ESPCN算法的出图,右上为Ground Truth,左下为低分辨率的图像,右下为RealESRGAN算法的出图。
从效果图中,可以看到ESPCN的整体效果要比RealESRGAN差一些,RealESRGAN虽然在大多数场景会丢失很多细节,倾向于把图像抹平,但是RealESRGAN在建筑的恢复上做的很好。ESPCN在大多数场景都要模糊一些。