超分论文解读Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
Published:
本篇blog除了对论文内容进行了详实的翻译,同时对论文中的相关技术细节展开了说明和讨论,部分技术通过示例代码进行了说明。
本篇论文中除了涉及了很多超分的内容外,其中数据退化等内容,更是low-level视觉任务中可以通用的知识,比如图像去噪、HDR等。本篇论文涵盖了很多基础视觉任务中通用的内容。
论文地址:Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
论文开头放出了Real-ESRGAN的效果图

从效果图上可以看到real-esrgan的效果要远远超过其他的方法。
摘要
虽然在盲超分辨率中已经进行了许多尝试,以恢复具有未知和复杂退化的低分辨率图像,但它们仍然远远不能解决现实世界中一般的退化图像。在这项工作中,我们将强大的ESRGAN扩展到实际的恢复应用(即Real-ESRGAN),该应用使用纯合成数据进行训练。具体来说,引入了一个高阶退化建模过程来更好地模拟复杂的真实世界的退化。我们还考虑了合成过程中常见的振铃和超调伪影。此外,我们还采用了一种带有频谱归一化的U-Net鉴别器,以提高鉴别器的性能并稳定训练动态。广泛的比较表明,它的视觉性能优于以前的作品在各种实际数据集。我们还提供了有效的实现来实时合成训练对。
这里解释一下盲超分辨率和振铃伪影、超调伪影:
Blind super-resolution(盲超分辨率)是一种图像处理技术,旨在从低分辨率(LR)图像中恢复出高分辨率(HR)图像,且在此过程中,图像降质(degradation)的过程是未知的。这与已知降质核(或过程)的非盲超分辨率(non-blind super-resolution)相反。盲超分辨率对于真实世界场景非常有吸引力,因为它依赖于低分辨率图像,而不假设任何关于图像如何降质的具体信息 。
Ringing artifacts(振铃伪影)和overshoot artifacts(超调伪影)是在图像处理和合成过程中常见的两种问题。Ringing artifacts 通常出现在图像中边缘过渡的地方,视觉上看起来像边缘附近的多重细平行线,给人一种“幽灵”或“带状”的感觉。这种伪影可能是由信号的带限特性以及在图像重建过程中使用傅立叶变换造成的,特别是在高对比度的界面处,傅立叶级数的截断会导致显著的振铃现象,表现为变化的下冲和过冲振荡 。
Overshoot artifacts 则通常与ringing artifacts一起出现,表现为边缘过渡处的突增,这可能是由于锐化算法或JPEG压缩等引起的 。
两者一般是同时出现,在图像的表现上一般如下图所示:

为了在训练过程中模拟这些常见的artifacts,Real-ESRGAN采用了sinc滤波器来合成ringing和overshoot artifacts。sinc滤波器是一种理想化的滤波器,通过截断高频部分来模拟这些现象,特别是在过度锐化效果下 。这些artifacts的合成对于训练模型以处理和恢复真实世界图像是非常重要的,因为真实世界的图像往往包含了复杂和未知的降质过程,例如相机模糊、传感器噪声、锐化伪影和JPEG压缩等 。通过在合成过程中考虑这些因素,Real-ESRGAN能够更好地模拟真实世界的图像降质,并训练出更为实用和有效的超分辨率模型 。
1. 介绍
单幅图像超分辨率(SR)是一个活跃的研究课题,旨在从低分辨率(LR)图像中重建高分辨率(HR)图像。自SRCNN的开创性工作以来,深度卷积神经网络(CNN)方法带来了SR领域的蓬勃发展。然而,大多数方法假设一个理想的双三次下采样核,这与实际的退化不同。这种退化不匹配使得这些方法在实际场景中不实用。
而盲目超分辨率则旨在恢复遭受未知和复杂退化的低分辨率图像。现有的方法可以根据潜在的退化过程大致分为显式建模和隐式建模。经典退化模型由模糊、降采样、噪声和JPEG压缩组成,在显式建模方法中被广泛采用。然而,现实世界的退化通常太复杂,无法用多个退化的简单组合来建模。因此,这些方法在真实世界的样本中很容易失败。隐式建模方法利用生成式对抗网络(GAN)的数据分布学习来获得退化模型。然而,它们仅限于训练数据集内的退化,不能很好地推广到分布外的图像。
在这项工作中,作者的目标是扩展强大的ESRGAN,通过合成具有更实用的退化过程的训练对来恢复一般现实世界的LR图像。真正的复杂退化通常是不同退化过程的复杂组合,如相机成像系统、图像编辑、网络传输等。例如,当我们用手机拍照时,照片可能会有一些退化,比如相机模糊、传感器噪声、锐化伪影和JPEG压缩。然后我们进行一些编辑并上传到社交媒体应用程序,这引入了进一步的压缩和不可预测的噪音。当图片在互联网上被多次分享时,上述过程变得更加复杂。
作者将经典的“一阶”退化模型扩展到现实世界退化的“高阶”退化模型,即将退化建模为几个重复的退化过程,每个过程都是经典的退化模型。根据经验,作者采用二阶退化过程,以在简单性和有效性之间取得良好的平衡。最近的一项研究也提出了一种随机洗牌策略来综合更实际的退化。然而,它仍然涉及固定数量的降解过程,并且是否所有的洗牌降解都是有用的还不清楚。相反,高阶退化建模更灵活,并试图模仿真实的退化生成过程。我们进一步在合成过程中加入正弦滤波器来模拟常见的振铃和过冲(超调)伪影。
由于退化空间比ESRGAN大得多(real-esrgan的工作是基于esrgan而来),训练也变得具有挑战性。具体而言,1)鉴别器需要更强大的能力来区分复杂训练输出的真实感,而鉴别器的梯度反馈需要更准确以增强局部细节。因此,我们将ESRGAN中的vgg式鉴别器改进为U-Net设计。U-Net结构和复杂的退化也增加了训练的不稳定性。因此,我们采用谱归一化(SN)正则化来稳定训练动态。配备了专用的改进,我们能够轻松地训练Real-ESRGAN,并实现局部细节增强和伪迹抑制的良好平衡。
总结这项工作的贡献,1)作者提出了一个高阶退化过程来模拟实际的退化,并利用sinc滤波器来模拟常见的振铃和超调伪影。2)使用了一些必要的修改(例如,带谱归一化的U-Net鉴别器)来提高鉴别器的能力并稳定训练动态。3)使用纯合成数据训练的Real-ESRGAN能够还原大多数真实世界的图像,并且比以前的作品具有更好的视觉表现,使其在真实世界的应用中更具实用性。
自SRCNN以来,图像超分辨率领域得到了各种发展。为了获得视觉上令人愉悦的结果,生成对抗网络通常被用作损失监督,以使解更接近自然流形。大多数方法假设一个双三次下采样核,通常在实际情况下失败。最近的研究还将强化学习或GAN纳入图像恢复之前。
2. 相关工作
自SRCNN以来,图像超分辨率领域得到了各种发展。为了获得视觉上令人愉悦的结果,生成对抗网络通常被用作损失监督,以使解更接近自然流形。大多数方法假设一个双三次下采样核,通常在实际情况下效果并不好。最近的研究还将强化学习或GAN纳入图像恢复之前。
这里解释一下自然流形。在图像超分辨率领域,”natural manifold”通常指的是数据在高维空间中所固有的低维结构。这种结构可以被认为是数据点所构成的一个连续的几何表面,它在高维空间中以一种复杂的方式被扭曲和折叠。当我们处理图像数据时,尽管像素值可能存在于一个非常高维的空间中,但实际的图像内容和视觉信息可能只占据这个高维空间中的一个低维子集,这个子集就是一个自然流形。 在深度学习和图像处理中,了解和利用这种自然流形是非常重要的。例如,使用生成对抗网络(GAN)进行图像超分辨率处理时,GAN的目标是生成视觉上令人愉悦的高质量图像,这通常涉及到将生成的图像推向自然流形,以确保它们看起来尽可能自然和真实 。 此外,流形学习在机器学习领域中也扮演着重要角色,它致力于发现数据中的潜在结构和特征。通过对高维数据进行降维和提取关键信息,流形学习帮助我们理解复杂数据集的新视角 。在图像处理、文本表示以及大数据分析等领域,流形学习的应用已经取得了显著成果 。 总的来说,”natural manifold”在图像超分辨率和其他机器学习任务中,是一个关键概念,它涉及到数据在高维空间中的内在低维结构,对于生成自然和真实的图像至关重要。
在盲超分辨率方面已经有了一些很好的探索。其中的方法可以进行分类,其中一类涉及明确的退化表示,通常由退化预测和条件恢复两部分组成。以上两个组成部分可以单独执行,也可以联合(迭代)执行。这些方法依赖于预定义的降质表示(例如,降质类型和水平),并且通常考虑简单的合成降质。此外,不准确的退化估计将不可避免地导致一些不自然或非真实的细节(artifacts)。
另一个类别是尽可能地获取或生成与真实数据相近的训练对,然后训练一个统一的网络来处理盲超分辨率问题。这些训练对通常包括:1) 使用特定相机拍摄后进行繁琐对齐的数据;2) 或者直接从未配对数据中通过循环一致性损失(cycle consistency loss)学习得到的数据;3) 或者使用估计的模糊核和提取的噪声块合成的数据。然而,1) 捕获的数据仅受限于与特定相机相关的降质,因此不能很好地泛化到其他真实图像;2) 从未配对数据中学习细粒度的降质是具有挑战性的,结果通常不尽人意。
循环一致性损失(cycle consistency loss)是CycleGAN中一个重要的概念,它用于确保在图像转换过程中,原始图像经过两次转换(即前向转换和后向转换)后能够尽可能地回到其初始状态。这种损失函数的设计基于循环一致性原则,即如果一个输入图像经过两次变换回到原域,最终应获得与原始输入相似或相同的图像。 具体来说,循环一致性损失包含两部分:前向循环一致性(forward cycle consistency)和后向循环一致性(backward cycle consistency)。前向循环一致性指的是,对于一个从域X转换到域Y的图像x,经过生成器G转换到Y后,再通过生成器F转换回X,希望得到的结果是与原始图像x近似相同的,即 ( F(G(x)) \approx x )。同理,后向循环一致性指的是,对于一个从域Y转换到域X的图像y,经过生成器F转换到X后,再通过生成器G转换回Y,希望得到的结果是与原始图像y近似相同的,即 ( G(F(y)) \approx y ) 。循环一致性损失通常使用L1损失来计算,即原始图像与经过两次转换后的图像之间的差异。这个损失函数的目的是使生成的图像在视觉上保持一致性,避免不自然的伪影或图像退化 。在CycleGAN的总损失函数中,循环一致性损失与对抗损失一起,共同指导生成器学习如何进行图像的转换,同时确保转换过程的一致性和准确性 。 此外,循环一致性损失在CycleGAN中的应用不仅限于风格迁移,还包括物体变形、季节转换、照片增强等多种任务,证明了其作为一种通用解决方案的潜力 。通过这种方式,CycleGAN能够在没有成对训练数据的情况下,实现高质量的图像到图像的转换 。
Degradation models:在盲超分辨率(Blind Super-Resolution, BSR)的研究中,”Degradation models” 指的是用来描述高分辨率(High-Resolution, HR)图像是如何通过某种过程退化成低分辨率(Low-Resolution, LR)图像的模型。这些模型在盲超分辨率方法中非常重要,因为它们帮助恢复图像的细节和质量。经典的退化模型被广泛应用于盲超分辨率方法。然而,现实世界的退化过程通常非常复杂,很难被显式地建模。因此,隐式建模尝试在网络内部学习一个退化生成过程。在这项工作中,作者提出了一个灵活的高阶退化模型,用于合成更实际的退化效果。
高阶退化模型的目的是捕捉从HR到LR图像转换过程中的复杂性,包括模糊、下采样、噪声等因素。在实际应用中,退化过程可能受到多种因素的影响,包括相机的光学特性、图像采集条件、以及后期处理等。因此,一个灵活且高阶的退化模型能够帮助更准确地模拟这一过程,并在超分辨率算法中实现更好的图像恢复效果 。
3.方法
3.1 经典退化模型
盲超分辨率(Blind Super-Resolution, BSR)的目标是在不知道复杂降质情况下,从低分辨率图像恢复出高分辨率图像。采用经典降质的模型通常使用合成低分辨率输入的方法。通常,首先将真实图像y与模糊核k进行卷积。然后,执行缩放因子为r的下采样操作。通过添加噪声n获得低分辨率图像x。最后,还采用了JPEG压缩,因为它在现实世界图像中被广泛使用。整个过程可以用下面的公式进行描述。
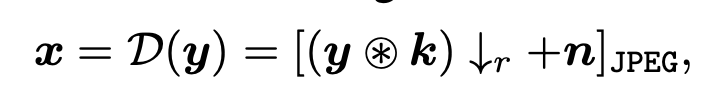
其中,D表示退化过程。
下面,我们对其中的过程进行拆解。
blur(模糊) :我们通常将模糊降质模拟为与线性模糊滤波器(核)的卷积。各向同性和各向异性高斯滤波器是常见的选择。对于具有2t + 1大小的高斯模糊核k,其(i, j) ∈ [-t, t]的元素是从高斯分布中抽取的,公式如下:
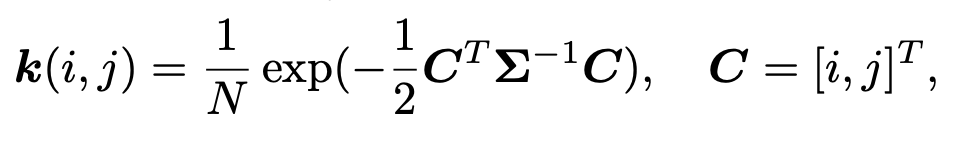
其中Σ是协方差矩阵;C是空间坐标;N是归一化常数。
讨论:尽管高斯模糊核被广泛用于模拟模糊降质,但它们可能无法很好地近似真实的相机模糊。为了包括更多样化的核形状,我们进一步采用了广义高斯模糊核和高原形状分布。它们的概率密度函数(pdf)分别是
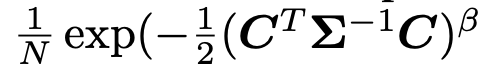
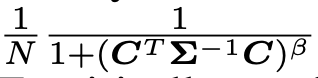
通过实验,我们发现包含这些模糊核可以为几个真实样本产生更锐利的输出。
噪声:我们考虑两种常用的噪声类型—— 1)加性高斯噪声和 2)泊松噪声。加性高斯噪声的概率密度函数等同于高斯分布的概率密度函数。噪声强度由高斯分布的标准差(即σ值)控制。当RGB图像的每个通道有独立采样的噪声时,合成的噪声就是彩色噪声。我们还通过在所有三个通道中使用相同的采样噪声来合成灰度噪声。
泊松噪声遵循泊松分布。它通常用于近似模拟由统计光量子涨落引起的传感器噪声,即在给定曝光水平下感知到的光子数量的变化。泊松噪声的强度与图像强度成正比,不同像素的噪声是相互独立的。
彩色噪声和灰度噪声是图像处理中两种不同类型的噪声,它们模拟了图像采集过程中可能遇到的随机误差:
彩色噪声 (Color Noise): 彩色噪声是指在图像的每个颜色通道(如RGB彩色空间中的红、绿、蓝通道)中独立添加的噪声。这种噪声通常具有高斯分布的特性,其标准差(σ值)决定了噪声的强度。由于每个通道独立采样,彩色噪声可以包含各种颜色的随机变化,这可能导致图像中出现不自然的颜色偏差。在数字图像中,彩色噪声可能由于传感器的随机热噪声、电子读出噪声或模拟信号转换过程中的不完善而产生。
灰度噪声 (Grayscale Noise): 灰度噪声是指在图像的所有颜色通道中添加相同模式的噪声。与彩色噪声不同,灰度噪声不会导致颜色偏差,而是在图像的每个像素上增加或减少相同的灰度值。这种噪声通常也是高斯分布的,但它保持了图像原有的颜色比例,只是整体上增加了随机变化。灰度噪声可能来源于图像传感器的固定模式噪声或在图像处理的某个阶段引入的随机误差。
在实际应用中,彩色噪声和灰度噪声都可能影响图像质量,降低图像的信噪比,从而对图像的视觉效果和后续处理(如图像分析、模式识别等)造成干扰。因此,噪声抑制和降噪是图像处理中的重要任务。
加性高斯噪声(Additive Gaussian Noise)和高斯噪声(Gaussian Noise)在很多情况下是可以互换使用的术语,因为它们都描述了一种具有特定统计特性的噪声,这种噪声的概率密度函数符合高斯分布(也称为正态分布)。不过,这两个术语在使用上有时会有细微的区别:
高斯噪声 (Gaussian Noise): 高斯噪声是指其幅度分布符合高斯分布的噪声。在图像处理或信号处理中,如果一个随机过程的输出信号的噪声成分具有高斯分布的特性,那么这个信号就被认为是受到了高斯噪声的影响。高斯噪声通常由多个独立随机过程的叠加而产生,根据中心极限定理,许多小的、独立的随机扰动之和趋向于高斯分布。
加性高斯噪声 (Additive Gaussian Noise): 加性高斯噪声特指在信号或图像中直接添加的高斯分布噪声。“加性”(Additive)一词强调了噪声是直接加到原始信号上的,意味着噪声的引入是外生的,与信号本身的值无关。在数学表达上,如果有信号 ( x ) 受到加性高斯噪声 ( n ) 的影响,则接收到的信号 ( y ) 可以表示为 ( y = x + n ),其中 ( n ) 是符合高斯分布的随机变量。
在实际应用中,这两个术语经常可以互换使用,因为大多数情况下讨论的噪声都是外生的,并且符合高斯分布。然而,如果需要强调噪声是直接加到信号上的特性,那么“加性”这个词就显得更为准确。
Resize(下采样):下采样是合成超分辨率中低分辨率图像的基本操作。更一般地,我们考虑下采样和上采样,即尺寸调整操作。有几种尺寸调整算法 - 最近邻插值、区域尺寸调整、双线性插值和双三次插值。不同的尺寸调整操作带来不同的效果 - 有些产生模糊的结果,而有些可能输出带有过冲伪影的过度锐化图像。
为了包含更多样化和复杂的尺寸调整效果,我们考虑从上述选择中随机进行尺寸调整操作。由于最近邻插值引入了不对齐问题,我们排除了它,只考虑区域、双线性和双三次操作。
补充:
最近邻插值(Nearest-Neighbor Interpolation)是一种简单的图像尺寸调整算法,它通过直接取原始图像中最接近目标像素位置的像素值来生成新的像素值。这种方法在上采样(放大图像)时通常不会产生不对齐问题,但在下采样(缩小图像)时可能会出现以下问题:
非一致的采样间隔:最近邻插值在下采样过程中,由于选择了最接近的像素,可能会导致采样间隔不一致。这意味着在不同的方向上,像素被采样的频率可能不同,从而导致图像内容在某些方向上出现错位。
几何失真:当使用最近邻插值对图像进行尺寸调整时,由于不进行任何加权平均,图像的几何特征可能会在缩放过程中发生扭曲或失真,尤其是在不同分辨率之间存在不成比例的缩放比例时。
图像内容错位:在图像尺寸调整过程中,由于最近邻插值没有考虑像素之间的空间关系,可能会导致图像中的特征(如边缘或纹理)在缩放后发生错位,从而产生不对齐的现象。
抗锯齿处理不足:与其他插值方法(如双线性或双三次插值)相比,最近邻插值没有进行任何形式的抗锯齿处理,这可能导致在图像的边缘或某些高频区域出现锯齿状的不连续性,进一步加剧了不对齐的问题。
因此,在需要精确对齐的图像处理任务中,通常会避免使用最近邻插值进行下采样,以防止上述问题的发生。相反,会选择其他能够提供更平滑过渡和更好边缘保持的插值方法。
补充:
下面是提到的几种插值算法的原理:
- 最近邻插值 (Nearest-Neighbor Interpolation):
- 原理:在目标图像的每个像素位置,找到原始图像中最接近的一个像素点,并直接使用该点的值。
- 特点:计算简单,速度快,但可能会产生锯齿状的边缘和块状效应,尤其在下采样时可能会引起图像内容的错位。
- 区域插值 (Area Interpolation) 或 最近邻域插值 (Bilinear Interpolation):
- 原理:对目标像素周围的一个局部区域内的像素进行加权平均,以计算目标像素的值。权重通常与像素距离目标位置的远近成反比。
- 特点:相比最近邻插值,区域插值能够提供更平滑的结果,但仍然可能在边缘附近出现模糊。
- 双线性插值 (Bilinear Interpolation):
- 原理:使用目标像素位置周围的四个最近像素,通过双线性函数(通常是线性的线性函数)进行加权平均来确定目标像素的值。
- 特点:双线性插值在上下采样时都能提供相对平滑的结果,减少了模糊和锯齿效应,但可能会稍微降低图像的锐度。
- 双三次插值 (Bicubic Interpolation):
- 原理:使用目标像素位置周围的16个像素(4x4的区域),通过一个双三次多项式函数来计算目标像素的值。双三次插值在每个方向上都是三次多项式,提供了更平滑的过渡。
- 特点:双三次插值能够生成非常平滑的图像,尤其在上采样时效果较好,但在下采样时可能会引入过冲(overshoot)现象,即在某些区域出现比原始图像亮度更高或更低的像素值。
每种插值算法都有其适用场景和优缺点。最近邻插值因其简单性在速度要求极高时使用;区域插值和双线性插值提供了较好的折中方案,平衡了计算量和图像质量;双三次插值则在需要高质量图像时使用,尽管计算量较大。在实际应用中,选择哪种插值方法取决于对速度和图像质量的具体要求。
我们用下面的python代码来具体看一下每个插值算法的具体表现:
import matplotlib.pyplot as plt
from PIL import Image
# 读取图片
original_image = Image.open('./LR/2024080900110800-CC47F0DEC75C1FD3B1F95FA9F9D57667.jpg')
# 使用matplotlib显示原始图片
plt.imshow(original_image)
plt.title('Original Image')
plt.show()
# 定义下采样函数
def downsample(image, scale, resample_filter):
width, height = image.size
new_size = (width // scale, height // scale) # 使用整除来确保尺寸是整数
return image.resize(new_size, resample=resample_filter)
# 缩放比例
scale_factor = 4
# 使用不同的插值方法进行下采样
resample_filters = {
'Nearest-Neighbor': Image.NEAREST,
'Bilinear': Image.BILINEAR,
'Bicubic': Image.BICUBIC
}
# 创建图像和子图
fig, axs = plt.subplots(2, 2) # 2行2列的子图布局
titles = ['Original Image'] + list(resample_filters.keys())
# 显示原始图像
axs[0, 0].imshow(original_image)
axs[0, 0].set_title(titles[0])
axs[0, 0].axis('off') # 关闭坐标轴
# 遍历所有插值方法并显示结果
for i, (name, filter_method) in enumerate(resample_filters.items(), start=1):
downsampled_image = downsample(original_image.convert('RGB'), scale_factor, filter_method)
axs[i//2, i%2].imshow(downsampled_image)
axs[i//2, i%2].set_title(titles[i])
axs[i//2, i%2].axis('off') # 关闭坐标轴
# 调整子图间距
plt.subplots_adjust(wspace=0.1, hspace=0.1)
# 显示图像
plt.show()
fig.savefig('output_figure.png', bbox_inches='tight', pad_inches=0,dpi=300)
输出结果:

从结果上可以看出,最近邻方法确实有明显锯齿状的边缘,但是双三次插值没有发现明显的超调伪影。
JPEG压缩:是一种常用的数字图像有损压缩技术。它首先将图像转换到YCbCr颜色空间,并对色度通道进行下采样。然后将图像分割成8×8的块,每个块通过二维离散余弦变换(DCT)进行变换,接着对DCT系数进行量化。JPEG压缩通常会引入块状伪影。
压缩图像的质量由质量因子q决定,q的取值范围是[0,100],其中较小的q表示更高的压缩比和更差的质量。在这篇paper中使用了PyTorch实现的DiffJPEG。
3.2 高阶退化模型
当采用上述经典降质模型来合成训练对时,训练出的模型确实能够处理一些真实样本。然而,它仍然无法解决现实世界中的一些复杂降质,尤其是未知的噪声和复杂的伪影,如下图所示。

这是因为合成的低分辨率图像与现实降质图像之间仍存在较大差距。因此,本篇paper作者将经典降质模型扩展为高阶降质过程,以模拟更实际的降质情况。
经典降质模型只包括固定数量的基本降质操作,可以被视为一阶建模。然而,现实生活中的降质过程相当多样化,通常包括一系列程序,包括相机的成像系统、图像编辑、互联网传输等。例如,当我们想要恢复从互联网下载的一张质量较差的图片时,其背后的降质涉及不同降质过程的复杂组合。具体来说,原始图像可能是多年前用智能手机拍摄的,这不可避免地包含了诸如相机模糊、传感器噪声、低分辨率和JPEG压缩等降质。然后,图像经过锐化和尺寸调整操作进行编辑,引入了过冲和模糊伪影。之后,它被上传到一些社交媒体应用,这又引入了进一步的压缩和不可预测的噪声。由于数字传输也会带来伪影,当图像在互联网上传播多次时,这个过程变得更加复杂。
如此复杂的退化过程无法通过传统的一阶模型来准确模拟。因此,我们提出了一个高阶退化模型。一个n阶模型涉及n次重复的退化过程,每个退化过程都采用了经典退化模型,过程相同但超参数不同。这里所说的“高阶”与数学函数中的高阶不同,它主要指的是相同操作的实施次数。随机洗牌策略也可能包括重复的退化过程(例如,双重模糊或JPEG压缩)。但我们强调高阶退化过程是关键,意味着不是所有洗牌后的退化都是必需的。为了保持图像分辨率在一个合理的范围内,下采样操作被随机尺寸调整操作所取代。从经验上讲,我们采用了二阶退化过程,因为它能在保持简洁的同时解决大多数实际情况。下图展示了我们纯合成数据生成流程的概述。
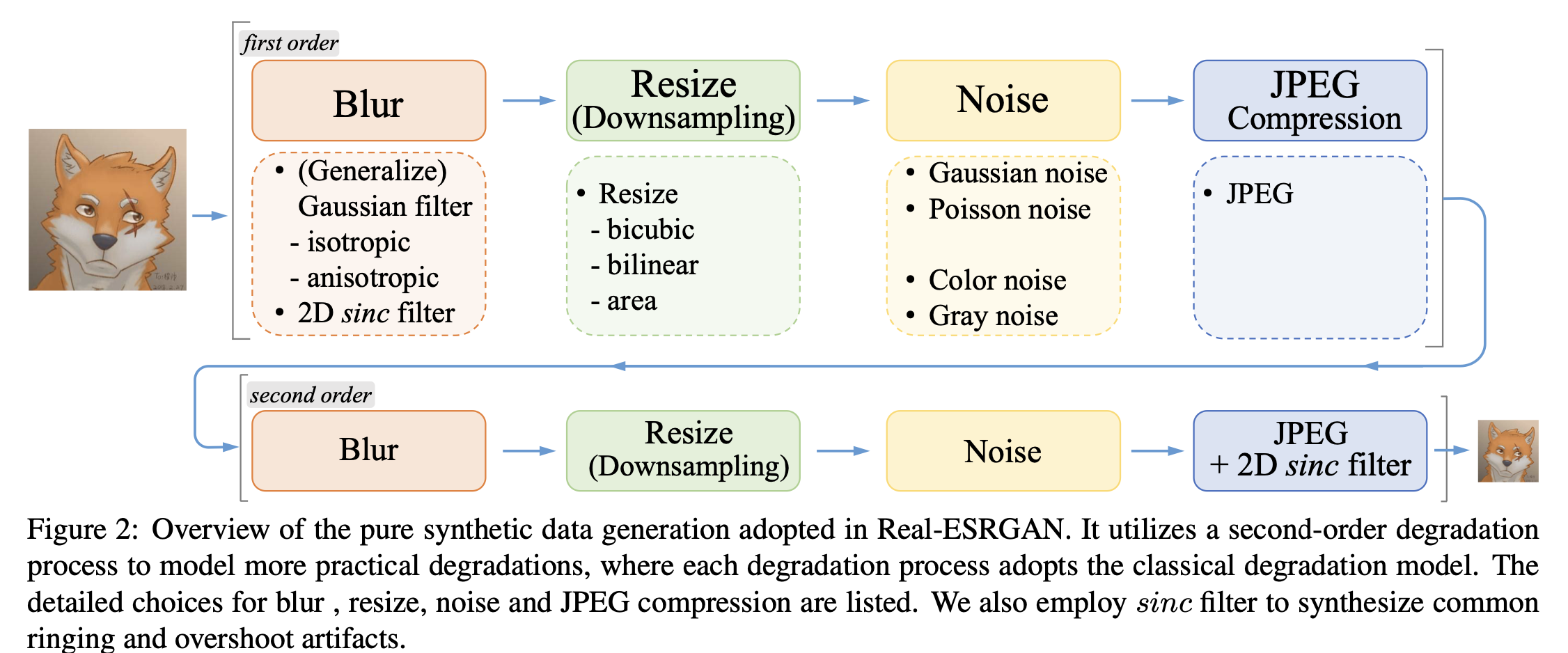
整个过程可以用下面公式来表示:
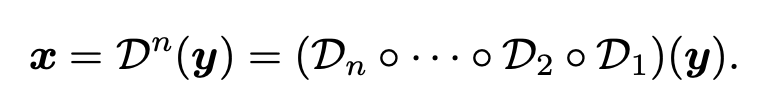
sinc滤波器是一种理想化的低通滤波器,用于在图像处理中切断高频信息,以模拟振铃和过冲伪影。振铃伪影通常出现在图像中锐化过渡附近,视觉上看起来像是边缘附近的条纹或鬼影;而过冲伪影则表现为边缘过渡处增加的跳跃,这两种伪影通常由图像锐化算法或JPEG压缩产生,因为它们没有对信号的高频部分进行适当限制。
sinc滤波器的核可以表示为:
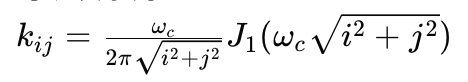
其中,(i,j)是核坐标,Wc是截断频率,J1是一阶贝塞尔函数。
值得注意的是,改进的高阶降质过程并不完美,并不能涵盖现实世界中的整个降质空间。相反,它只是通过修改数据合成过程,扩展了以往盲超分辨率方法可解决的降质边界。下图是几个典型的限制情况,real-esrgan的退化模型并不能覆盖这些数据分布,导致real-esrgan的生成效果比较差。

其中, 1) 一些恢复后的图像(特别是建筑和室内场景)由于混叠问题出现了扭曲的线条。2) GAN训练在某些样本上引入了伪影。3) 它无法去除现实世界中分布外的复杂退化情况。更糟糕的是,Real-ESRGAN可能会放大这些伪影。这些缺点对Real-ESRGAN的实际应用影响很大。
3.3 振铃和过冲伪影(Ringing and overshoot artifacts)
振铃伪影通常出现在图像中锐利过渡的附近,视觉上看起来像边缘附近的条纹或“鬼影”。过冲伪影通常与振铃伪影结合在一起,表现为边缘过渡处的跳变增强。这些伪影的主要原因是信号是带限的,不含高频成分。这些伪影非常常见,通常由锐化算法、JPEG压缩等产生。下图展示了一些真实样本,它们遭受了振铃和过冲伪影的影响。

作者采用了sinc滤波器,这是一种理想化的滤波器,用于切断高频,以合成训练对中的振铃和过冲伪影。sinc滤波器的核可以表示为:
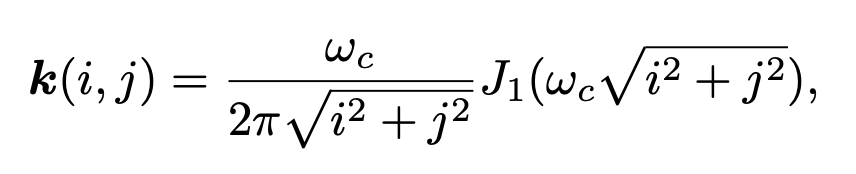
其中,(i,j)是核的坐标,ωc 是截断频率;而 J1 是一阶贝塞尔函数。下图展示了具有不同截断频率的sinc滤波器及其相应的过滤图像。观察到,它能够很好地合成振铃和过冲伪影(尤其是由过度锐化效果引入的)。这些伪影在视觉上与上图中前两个真实样本中的那些相似。
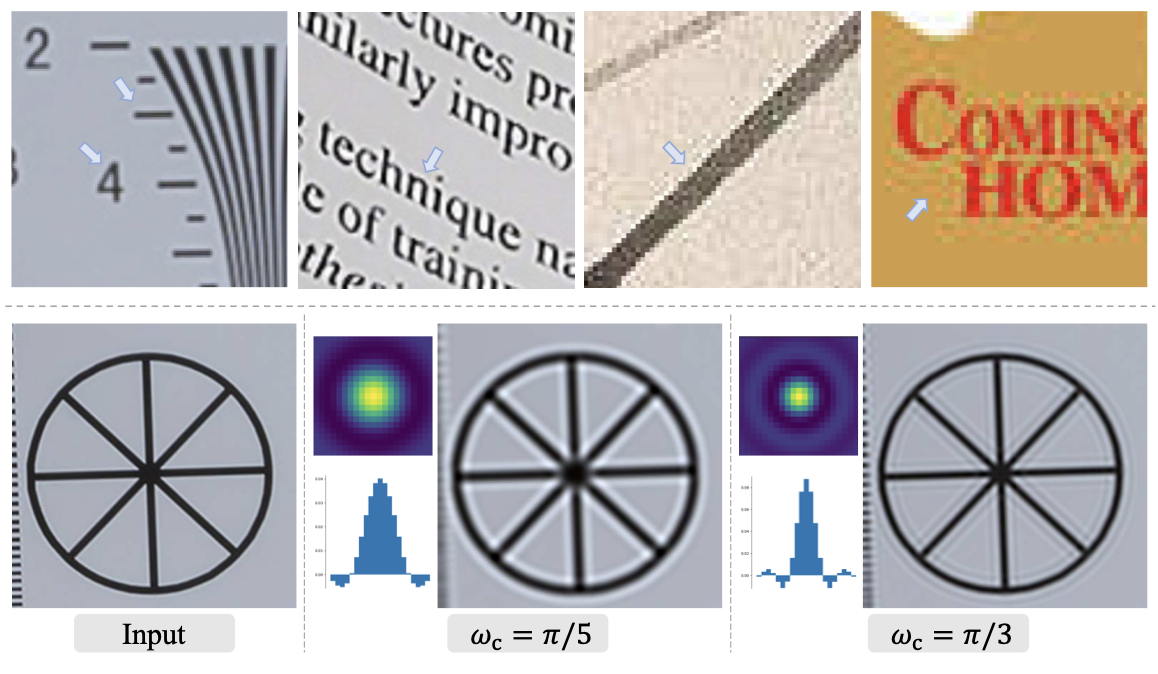
作者在两个地方采用了sinc滤波器:模糊过程和合成的最后步骤。最后一个sinc滤波器的顺序和JPEG压缩的顺序是随机交换的,以覆盖更大的退化空间,因为一些图像可能首先被过度锐化(带有过冲伪影),然后进行JPEG压缩;而一些图像可能首先进行JPEG压缩,然后进行锐化操作。
3.4 网络结构和训练过程
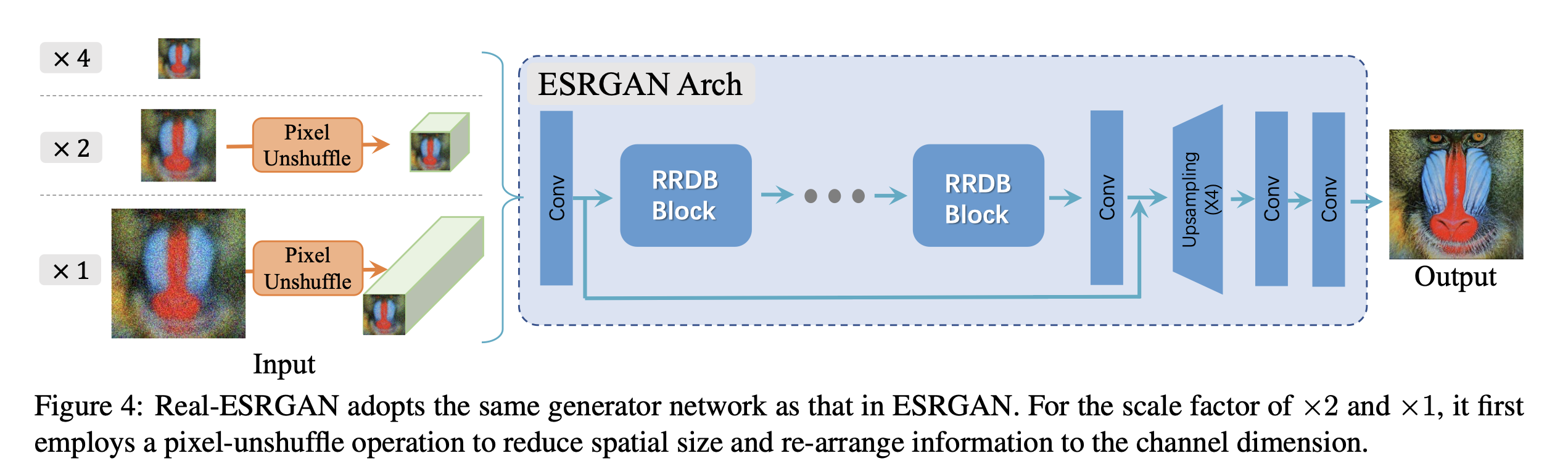
生成器:采用了与ESRGAN相同的生成器(SR网络),即一个包含多个残差密集块(residual-in-residual dense blocks,RRDB)的深层网络,如下图所示。作者还扩展了原始的×4 ESRGAN架构,以执行放大因子为×2和×1的超分辨率。由于ESRGAN是一个大型网络,首先使用pixel unshuffle将输入主ESRGAN架构之前减小空间尺寸并扩大通道尺寸。因此,大部分计算是在较小的分辨率空间中进行的,这可以减少GPU内存和计算资源的消耗。
补充:
我们重点解释下pixel unshufle和pixel shuffle。
Pixel Shuffle和Pixel Unshuffle是两种在深度学习中用于图像处理的操作,它们主要用于图像的上采样和下采样过程。
Pixel Shuffle是一种上采样操作,它通过重新排列输入张量的通道维度来增加图像的空间分辨率。具体来说,给定一个形状为(N,Crr,H,W) 的输入张量,Pixel Shuffle操作将其重新排列为(N, C, Hr, Wr) 的输出张量,其中r是上采样的倍率。这种操作对于实现高效的子像素卷积非常有用。
Pixel Unshuffle则是Pixel Shuffle的逆操作,用于降低图像的空间分辨率。给定一个形状为(N, C, Hr, Wr) 的输入张量,Pixel Unshuffle将其重新排列为(N,Crr,H,W)的输出张量。这个操作有助于在将输入送入主网络架构之前减小空间尺寸并扩大通道尺寸,例如在ESRGAN中使用,以提高超分辨率模型的性能。
Pixel Shuffle和Pixel Unshuffle是两种在PyTorch中用于图像处理的层,它们通常用于图像的上采样和下采样任务。下面我将使用Python和PyTorch详细解释这两个操作。
在PyTorch中,nn.PixelShuffle层是这样定义的:
import torch
import torch.nn as nn
# 定义上采样倍数
upscale_factor = 2
# 创建PixelShuffle层
ps = nn.PixelShuffle(upscale_factor)
# 假设有一个输入张量,其形状为(batch_size, channels, height, width)
# 例如:(1, 4, 2, 2),表示batch_size为1,channels为4,height和width都是2
input = torch.randn(1, 4, 2, 2)
# 应用PixelShuffle层
output = ps(input)
print("PixelShuffle output shape:", output.shape) # 输出形状应该是(1, 1, 4, 4)
在PyTorch中,nn.PixelUnshuffle层是这样定义的:
# 定义下采样倍数
downscale_factor = 2
# 创建PixelUnshuffle层
pus = nn.PixelUnshuffle(downscale_factor)
# 假设有一个输入张量,其形状为(batch_size, channels, height, width)
# 例如:(1, 1, 4, 4),表示batch_size为1,channels为1,height和width都是4
input = torch.randn(1, 1, 4, 4)
# 应用PixelUnshuffle层
output = pus(input)
print("PixelUnshuffle output shape:", output.shape) # 输出形状应该是(1, 4, 2, 2)
这两种操作在图像处理和深度学习中非常有用,特别是在需要高效上采样或下采样时。例如,在超分辨率任务中,Pixel Shuffle可以用来增加图像分辨率,而Pixel Unshuffle可以用来在处理前减少图像的空间尺寸。
鉴别器:使用带有谱归一化(Spectral Normalization,简称SN)的U-Net作为鉴别器,主要是为了提高鉴别器的鉴别能力,并稳定训练过程。由于Real-ESRGAN的目标是处理比ESRGAN更大的退化空间,原始的ESRGAN鉴别器设计不再适用。Real-ESRGAN需要鉴别器不仅能区分全局风格,还要能产生对局部纹理的准确梯度反馈。因此,研究者们将ESRGAN中的VGG风格鉴别器改进为具有跳跃连接的U-Net设计,U-Net能够输出每个像素的真实度值,并为生成器提供详细的逐像素反馈。
鉴别器结构如下图所示。

补充:
谱归一化是一种正则化技术,用于保证GAN中的判别器满足Lipschitz连续性,即限制函数变化的最大梯度。在判别器的每一层卷积参数矩阵上应用谱归一化,可以使其满足1-Lipschitz连续性,从而确保整个神经网络的Lipschitz连续性。具体来说,谱归一化通过以下两个步骤实现:
- 利用幂迭代法近似计算W的最大奇异值。
- 在每次更新W之后,将其除以最大奇异值,实现归一化 。
此外,谱归一化还能帮助减轻GAN训练中引入的过度锐化和烦人的伪影,进一步提升了Real-ESRGAN的性能。通过这些调整,Real-ESRGAN能够更容易地训练,并在局部细节增强和伪影抑制之间实现了良好的平衡 。
值得注意的是,在使用谱归一化的判别器后,就不能再使用BatchNorm或其他形式的归一化了,因为这些操作会破坏判别器的Lipschitz连续性 。谱归一化是控制梯度的一种方法,与梯度惩罚(Gradient Penalty)和权重裁剪(Weight Clipping)等其他控制权重或梯度的方法相比,它是一种模型层面的、非采样的、硬性的约束 。
训练过程:Real-ESRGAN的训练过程分为两个阶段。首先,研究者们训练了一个以峰值信噪比(PSNR)为目标的模型,并使用L1损失函数来优化,这个模型被命名为Real-ESRNet。随后,利用这个训练好的PSNR导向的模型作为生成器的初始化,并结合L1损失、感知损失(Perceptual Loss)以及生成对抗网络(GAN)损失来训练Real-ESRGAN模型。
感知损失是一种常用于图像风格迁移等任务的损失函数,它通过比较模型预测结果与真实图像在感知空间中的差异来评估模型性能。与传统的均方误差损失函数(MSE)相比,感知损失更注重图像的感知质量,更符合人眼对图像质量的感受。感知损失的计算方式通常是将输入图像和目标图像分别通过预训练的神经网络,比如VGG-19网络,得到它们在网络中的特征表示,然后将这些特征表示作为损失函数的输入,计算它们之间的欧氏距离或曼哈顿距离。感知损失的目标是最小化输入图像和目标图像在特征空间的距离 。
在Real-ESRGAN的训练中,感知损失有助于提升生成图像的质量和细节,通过使用预训练的VGG19网络的特征图来计算损失,从而使得生成的图像在视觉上更加接近高分辨率的真实图像。此外,Real-ESRGAN的训练还包括了GAN损失,这是通过训练一个判别器网络来实现的,判别器的任务是区分生成的图像与真实的高分辨率图像,从而进一步推动生成器网络产生更加逼真的图像。
我们使用pytorch实现两种损失。
感知损失(Perceptual Loss)的实现
import torch
import torch.nn as nn
import torchvision.models as models
class PerceptualLoss(nn.Module):
def __init__(self, model='vgg19', layers=['0', '3', '8', '27', '34']):
super(PerceptualLoss, self).__init__()
self.mse = nn.MSELoss()
if model == 'vgg19':
self.vgg = models.vgg19(pretrained=True).features
self.vgg.eval()
for param in self.vgg.parameters():
param.requires_grad = False
else:
raise NotImplementedError()
# Select layers to compute loss on
self.layers = {layer: self.vgg[layer] for layer in layers}
def forward(self, input, target):
# Calculate features for both input and target
input_features = {name: layer(input)
for name, layer in self.layers.items()}
target_features = {name: layer(target) for name, layer in self.layers.items()}
# Calculate loss for each layer and sum it up
loss = 0
for name in input_features.keys():
loss += self.mse(input_features[name], target_features[name])
return loss
# 使用示例
# 假设 input 和 target 是PyTorch变量,已经预处理成VGG网络需要的格式
# criterion = PerceptualLoss()
# loss = criterion(input, target)
GAN损失(GAN Loss)的实现
import torch
import torch.nn as nn
class GANLoss(nn.Module):
def __init__(self, use_lsgan=True):
super(GANLoss, self).__init__()
if use_lsgan:
self.loss = nn.MSELoss()
else:
self.loss = nn.BCELoss()
def forward(self, fake_pred, real_pred, is_real, is_disc):
# Calculate GAN loss for the discriminator
if is_disc:
real_loss = self.loss(real_pred, torch.ones_like(real_pred))
fake_loss = self.loss(fake_pred, torch.zeros_like(fake_pred))
return real_loss + fake_loss
# Calculate GAN loss for the generator
else:
fake_loss = self.loss(fake_pred, torch.ones_like(fake_pred))
return fake_loss
# 使用示例
# 假设 fake_pred 和 real_pred 是判别器对假图像和真图像的预测
# is_real 表示 real_pred 是否为真实图像的标签(True 或 False)
# is_disc 表示是否在训练判别器(True)或生成器(False)
# criterion = GANLoss(use_lsgan=False) # 如果使用 Least Squares GAN,则设置 use_lsgan=True
# if is_disc:
# loss = criterion(fake_pred, real_pred, is_real, is_disc)
# else:
# loss = criterion(fake_pred, None, is_real, is_disc)
4.实验
4.1 数据集和实现
训练细节:与ESRGAN类似,采用了DIV2K、Flickr2K和OutdoorSceneTraining数据集进行训练。训练的高分辨率(HR)图像块大小(patch size)设定为256。作者使用四块NVIDIA V100 GPU进行模型训练,总batch size大小为48。采用Adam优化器进行优化。Real-ESRNet是从ESRGAN微调而来的,以加快收敛速度。训练Real-ESRNet进行1000K次迭代,学习率为2×10^-4,而训练Real-ESRGAN进行400K次迭代,学习率为1×10^-4。为了更稳定的训练和更好的性能,采用了指数移动平均(EMA)方法。Real-ESRGAN的训练结合了L1损失、感知损失和GAN损失,权重分别为{1, 1, 0.1}。作者的实现基于BasicSR。
DIV2K、Flickr2K 和 OutdoorSceneTraining 是在训练 Real-ESRGAN 时使用的三个主要数据集。
- DIV2K 数据集 :
- DIV2K 是一个高分辨率图像数据集,它包含了大量的自然场景图像,这些图像具有高清晰度和复杂的纹理细节。
- 该数据集通常被用于训练和测试图像超分辨率(Super-Resolution, SR)算法,因为它提供了高分辨率的图像对,非常适合用来生成低分辨率的训练样本。
- Flickr2K 数据集 :
- Flickr2K 是从 Flickr 网站收集的2K分辨率的图像数据集,它包含了多种类别的图像,例如人物、动物和风景等。
- 该数据集的特点是图像具有多样化的内容和现实世界的场景,这对于训练模型以处理各种类型的图像非常有帮助。
- OutdoorSceneTraining 数据集 :
- OutdoorSceneTraining 数据集包含了户外场景的高分辨率图像,这些图像通常具有丰富的纹理和复杂的场景结构。
- 该数据集专门用于训练超分辨率模型,以提高模型对户外场景图像的处理能力。
退化细节:作者采用二阶退化模型,实现了简洁性和有效性的良好平衡。除非另有说明,否则两个退化过程的设置相同。我们采用高斯核、广义高斯核和高原形状核,使用概率分别为{0.7, 0.15, 0.15}。模糊核大小从{7, 9…21}中随机选择。模糊标准差σ从[0.2, 3]中采样(对于第二个退化过程为[0.2, 1.5])。形状参数β分别从[0.5,4]和[1,2]中采样,用于广义高斯核和高原形状核。我们还使用sinc核,使用概率为0.1。我们以0.2的概率跳过第二个模糊退化。
采用高斯噪声和泊松噪声,使用概率分别为{0.5, 0.5}。噪声的标准差范围设置为[1, 30],泊松噪声的比例尺设置为[0.0.5, 3](第二次退化过程中分别为[1, 25]和[0.05, 2.5])。灰色噪声的概率设置为0.4。JPEG压缩质量因子设置为[30, 95]。最终以0.8的概率应用sinc滤波器。
高原形状核(plateau-shaped kernels)与高斯模糊核在图像处理中都用于实现模糊效果,但它们在形状和数学特性上存在一些关键区别:
- 概率密度函数(PDF):
- 高斯模糊核: 其PDF是高斯函数(正态分布),形式为 ( \exp(-\frac{1}{2}(C^T\Sigma^{-1}C)) ),其中 ( C ) 是空间坐标,( \Sigma ) 是协方差矩阵,控制着模糊的宽度。
- 高原形状核: 其PDF通常具有不同的形式,可能不遵循正态分布。在Real-ESRGAN中,高原形状核的PDF是 ( \frac{1}{N(1 + (CT\Sigma^{-1}C)^\beta)} ),其中 ( \beta ) 是形状参数,控制着模糊核的高原形状特性。
- 形状特性:
- 高斯模糊核: 提供一种平滑的、无界的模糊效果,随着距离中心点的增加,其值呈指数级衰减。
- 高原形状核: 可能在中心区域有较高的值,然后缓慢衰减到一个相对平坦的高原区域,之后再逐渐下降到零。这种核的形状更加多样,可以模拟不同于高斯分布的模糊特性。
- 应用目的:
- 高斯模糊核: 常用于模拟相机拍摄时的自然模糊效果,广泛应用于图像处理中的模糊操作。
- 高原形状核: 用于提供更多样化的模糊效果,可以更好地模拟现实世界中复杂的模糊情况,如由于运动或其他因素造成的非高斯模糊。
- 参数控制:
- 高斯模糊核: 主要通过协方差矩阵 ( \Sigma ) 中的参数(如标准差)来控制模糊的强度和方向。
- 高原形状核: 除了协方差矩阵外,还通过形状参数 ( \beta ) 来控制模糊核的高原形状特性,提供更多的调节灵活性。
在Real-ESRGAN中,使用高原形状核是为了增加模型对不同模糊类型的适应能力,从而提高超分辨率重建的质量,尤其是在处理真实世界图像时。通过结合高斯模糊核和高原形状核,模型能够学习到更广泛的模糊特征,进而在恢复高分辨率图像时更好地保留细节和纹理。
训练对:为了提高训练效率,所有的退化过程都在PyTorch中用CUDA加速实现,这样我们就能够在运行时动态合成训练对。然而,批量处理限制了批量中合成退化的多样性。例如,一个批量中的样本不能具有不同的调整大小比例因子。因此,我们采用一个训练对池来增加批量中的退化多样性。在每次迭代中,训练样本都是从训练对池中随机选取以形成训练批次。在我们的实现中,我们将池的大小设置为180。
在训练过程中对真实图像进行锐化处理:作者进一步展示了一种训练技巧,以在不引入可见伪影的情况下从视觉上改善锐度。典型的图像锐化方法是使用后处理算法,如非锐化mask(USM)。然而,这种算法倾向于引入过冲伪影。我们通过经验发现,在训练过程中对真实图像进行锐化处理能够实现锐度和过冲伪影抑制之间的更好平衡。我们把使用锐化后的真实图像训练的模型称为Real-ESRGAN+。
补充: 这段话没太明白,在训练中对图像做锐化为什么就会减轻过冲伪影?
4.2 与之前的工作进行比较
作者将Real-ESRGAN与几种最先进的方法进行了比较,包括ESRGAN、DAN、CDC、RealSR和BSRGAN。在几个包含真实世界图像的多样化测试数据集上进行了测试,包括RealSR、DRealSR、OST300、DPED、ADE20K验证集和来自互联网的图片。由于现有的感知质量指标不能很好地反映在细粒度尺度上的实际人类感知偏好,作者展示了几个代表性的视觉样本,如下图。





从上图可以观察到,Real-ESRGAN在去除伪影和恢复纹理细节方面都优于以前的方法。Real-ESRGAN+(使用锐化的真实图像训练)可以进一步提高视觉锐度。具体来说,第一个样本包含过冲伪影(字母周围的白色边缘)。直接上采样不可避免地会放大这些伪影(例如,DAN和BSRGAN)。Real-ESRGAN考虑到这种常见的伪影,并使用sinc滤波器进行模拟,从而有效去除振铃和过冲伪影。第二个样本包含未知和复杂的退化。大多数算法无法有效消除它们,而经过二阶退化过程训练的Real-ESRGAN却能做到。Real-ESRGAN还能够为真实世界样本恢复更真实的纹理(例如,砖块、山脉和树木的纹理),而其他方法要么未能去除退化,要么添加了不自然的纹理(例如,RealSR和BSRGAN)。
4.3 消融实验
二阶退化模型:是Real-ESRNet中的一个关键概念,它用于更好地模拟真实世界图像的复杂退化过程。与传统的一阶退化模型相比,二阶模型通过重复应用退化过程(例如模糊、下采样、噪声添加等)来增加退化的复杂性。在Real-ESRNet的实验中,使用二阶退化模型代替经典的一阶退化模型进行训练,可以更有效地去除图像中的噪声和模糊,如下图中墙上的噪声或麦田中的模糊。

sinc滤波器:在Real-ESRNet中也起着重要作用,如果训练过程中不使用sinc滤波器,恢复的结果可能会放大输入图像中存在的振铃和过冲伪影,尤其是在文本和线条周围。使用sinc滤波器训练的模型能够有效地去除这些伪影,如下图所示。

具有谱归一化(Spectral Normalization, SN)的U-Net鉴别器:在Real-ESRGAN中,使用了一种带有谱归一化(Spectral Normalization, SN)的U-Net鉴别器来增强模型的性能和稳定性。 最初,ESRGAN使用的是VGG风格的鉴别器及其损失权重。然而,这种设置在面对复杂训练输出时,无法有效恢复细节纹理,如砖块和灌木,甚至可能在灌木枝上引入不自然的伪影,如下图。

为了改善局部细节并提供每个像素的真实度值,研究者将鉴别器改进为U-Net设计,它包含跳跃连接,能够输出每个像素的真实度,为生成器提供详细的逐像素反馈。 U-Net结构和复杂的退化过程增加了训练不稳定性。为了稳定训练动态,采用了谱归一化正则化。此外,观察到谱归一化还有助于减轻GAN训练引入的过度锐化和烦人的伪影 。 通过使用U-Net鉴别器和SN正则化,Real-ESRGAN能够在训练过程中实现更稳定的动态,并改善恢复的纹理质量,同时抑制不自然的结构和纹理 。
问题:从上图看,Unet和SN一起用,对于树枝的纹理,没有单独的Unet好啊?
更复杂的模糊核:作者在模糊合成中移除了广义高斯核和高原形状核。如下图所示,在某些真实样本上,该模型无法像Real-ESRGAN那样去除模糊并恢复清晰的边缘。尽管如此,在大多数样本上,它们的差异是微小的,这表明广泛使用的高斯核与高阶退化过程已经可以覆盖大部分真实模糊空间。由于我们仍然可以观察到稍微更好的效果,在Real-ESRGAN中采用了这些更复杂的模糊核。

4.4 Real-ESRGAN的局限性
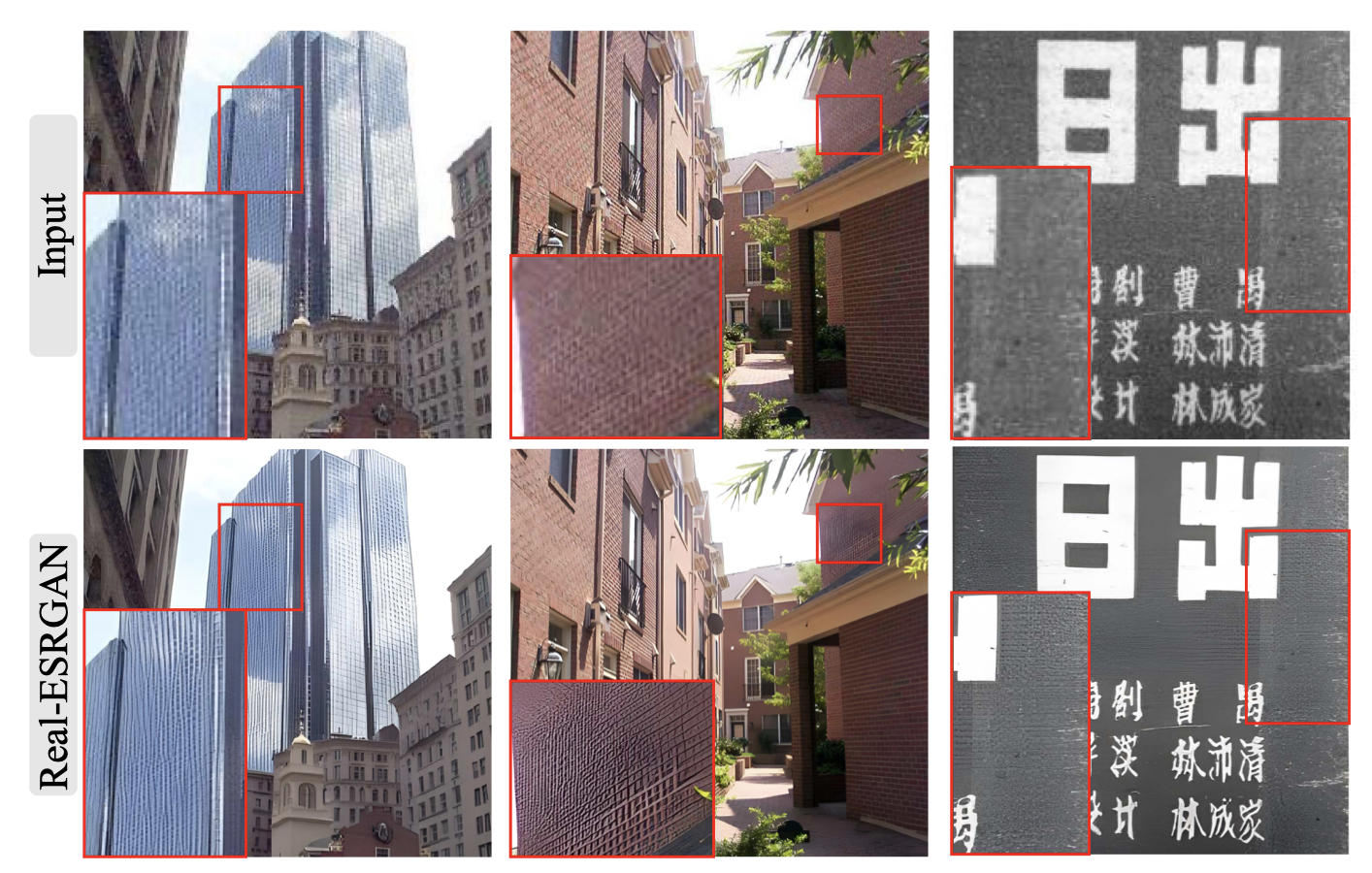
尽管Real-ESRGAN能够恢复大部分真实世界图像,但它仍然有一些局限性。如下图所示,1)一些恢复的图像(特别是建筑和室内场景)由于混叠问题而出现扭曲的线条。2) GAN训练在一些样本上引入了不愉快的伪影。3)它无法去除真实世界中的分布外复杂退化。更糟糕的是,它可能会放大这些伪影。这些缺点对Real-ESRGAN的实际应用有很大影响。
5.总结
在这篇论文中,作者训练了实用的Real-ESRGAN用于真实世界盲超分辨率,使用的是纯合成训练对。为了合成更实用的退化数据,作者提出了一个高阶退化过程,并使用sinc滤波器来模拟常见的振铃和过冲伪影。作者还利用具有频谱归一化正则化的U-Net鉴别器来增强鉴别器的能力并稳定训练动态。用合成数据训练的Real-ESRGAN能够在去除大多数真实世界图像中烦人的伪影的同时增强细节。
6 附录
经典退化模型的细节
6.1 Blur(模糊)
各向同性和各向异性高斯滤波器是模糊核的常见选择。下图展示了几种高斯核及其对应的模糊图像。

对于一个kernel size是2t+1的高斯模糊核k,它的值是从高斯分布中采样得到的。公式为:
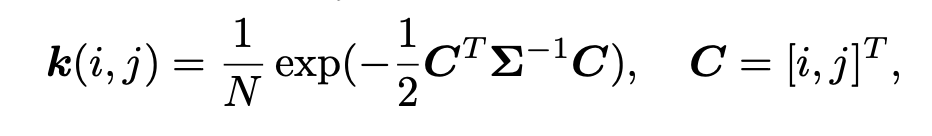
在图像处理中,高斯模糊核是通过与图像进行卷积来模拟模糊效果的。上面的公式是高斯核在多变量情况下的数学表达,特别是在二维空间中(例如,x 和 y 方向上),用于创建各向同性和各向异性的高斯模糊核。
给定的公式:

其中N是归一化常数,确保模糊核的总和为1。N的表达式为: 
协方差矩阵可以表示为: 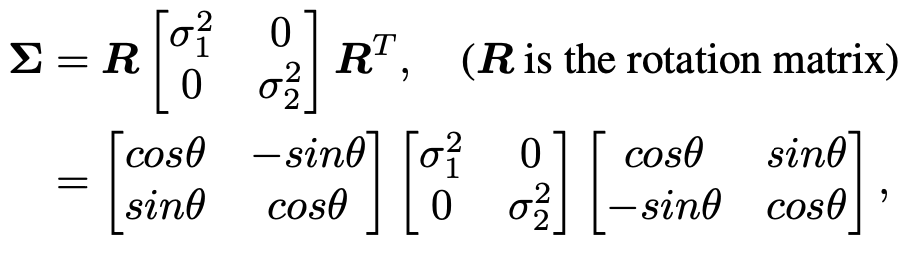
角度theta表示协方差矩阵在二维空间中的旋转角度,σ1和σ2分别是沿着主轴的两个不同的标准差值,它们定义了高斯核在两个正交方向上的扩展程度。在实际应用中,如果σ1和σ2相等,高斯核是各向同性的,即在所有方向上具有相同的模糊程度。如果σ1和σ2不相等,核是各向异性的,意味着在一个方向上的模糊程度不同于另一个方向。通过引入角度θ我们可以控制模糊沿着特定方向的延伸,这可以用来模拟例如光线透过物体时产生的模糊效果。
在实际应用中,计算协方差矩阵的特征值和特征向量可以确定核的方向性和各向异性。然后,可以使用这个公式来生成具有所需属性的高斯模糊核。
各向同性(Isotropic)和各向异性(Anisotropic)高斯滤波器主要区别在于它们在空间上的应用方式和对图像特征的保留能力:
- 各向同性高斯滤波器:
- 这种滤波器在所有方向上都具有相同的权重,即它对图像的每个像素点应用了一个圆形的高斯函数。
- 高斯核是旋转不变的,这意味着滤波效果在所有方向上都是相同的。
- 它适用于模糊图像中的所有方向,但可能会导致图像中的线条和边缘变得不够清晰,因为滤波器对所有方向的响应都是均匀的。
- 各向异性高斯滤波器:
- 这种滤波器的权重在不同方向上是不同的,通常用于保留图像中的特定方向特征,例如边缘或纹理。
- 各向异性高斯核可以被设计为沿着特定方向(如水平或垂直)具有更窄的分布,从而在保持边缘锐度的同时平滑图像。
- 它通常用于图像的边缘保持降噪、图像锐化、以及在图像处理中强调或抑制特定方向的特征。
在实际应用中,选择哪种类型的高斯滤波器取决于所需的图像处理效果。如果目标是均匀地模糊图像,可能会选择各向同性高斯滤波器。如果需要在模糊图像的同时保留或强调某些方向的特征,则可能选择各向异性高斯滤波器。
OpenCV提供了cv2.GaussianBlur函数,它可以用于实现各向同性高斯模糊。对于各向异性模糊,可以通过调整水平和垂直方向上的内核大小来实现。
import cv2
# 读取图像
image = cv2.imread('path_to_image.jpg')
# 各向同性高斯模糊
isotropic_blur = cv2.GaussianBlur(image, (5, 5), 0)
# 各向异性高斯模糊(例如,更强调水平方向)
anisotropic_blur = cv2.GaussianBlur(image, (5, 1), 0)
# 显示结果
cv2.imshow('Isotropic Blur', isotropic_blur)
cv2.imshow('Anisotropic Blur', anisotropic_blur)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.GaussianBlur 是 OpenCV 库中的一个函数,用于对图像进行高斯模糊处理。高斯模糊是一种图像平滑技术,通过将每个像素点的值替换为邻域内加权平均值来减少图像噪声和细节。
函数的基本语法如下:
cv2.GaussianBlur(src, ksize, sigmaX[, dst[, sigmaY[, borderType]])
参数解释:
src:输入图像,可以是灰度图或彩色图(BGR格式)。ksize:高斯核的大小。它应该是一个奇数尺寸的元组或整数,如(5, 5)或5。如果ksize是奇数,则实际的高斯核将对称扩展。如果ksize是偶数,OpenCV 将自动增加它以获得下一个奇数数值。sigmaX:X方向上的高斯核标准差。如果设置为0,将根据ksize计算sigmaX。dst:输出图像,与输入图像src具有相同的类型和尺寸。如果未指定,函数将创建一个新的图像来存储结果。sigmaY:Y方向上的高斯核标准差。如果设置为0或省略,它将与sigmaX相同。如果需要不同的X和Y方向上的模糊效果(即各向异性模糊),可以设置不同的值。borderType:边界处理方式。常用的边界类型有:cv2.BORDER_CONSTANT:使用常数值填充边界(默认黑色)。cv2.BORDER_REFLECT:反射边界。cv2.BORDER_REFLECT101:反射101边界,与cv2.BORDER_REFLECT类似,但额外的0填充在源图像的两边。cv2.BORDER_REPLICATE:复制最近的边缘像素。cv2.BORDER_WRAP:环绕填充,即如果请求的像素在图像的左侧,它将使用图像的右侧像素。cv2.BORDER_DEFAULT:使用cv2.BORDER_REFLECT101。
为了包含更多样化的核形状,作者进一步采用了广义高斯模糊核和高原形状分布。下图展示了形状参数β如何控制核形状。通过实验,作者发现包含这些模糊核可以为几个真实样本产生更清晰的输出。
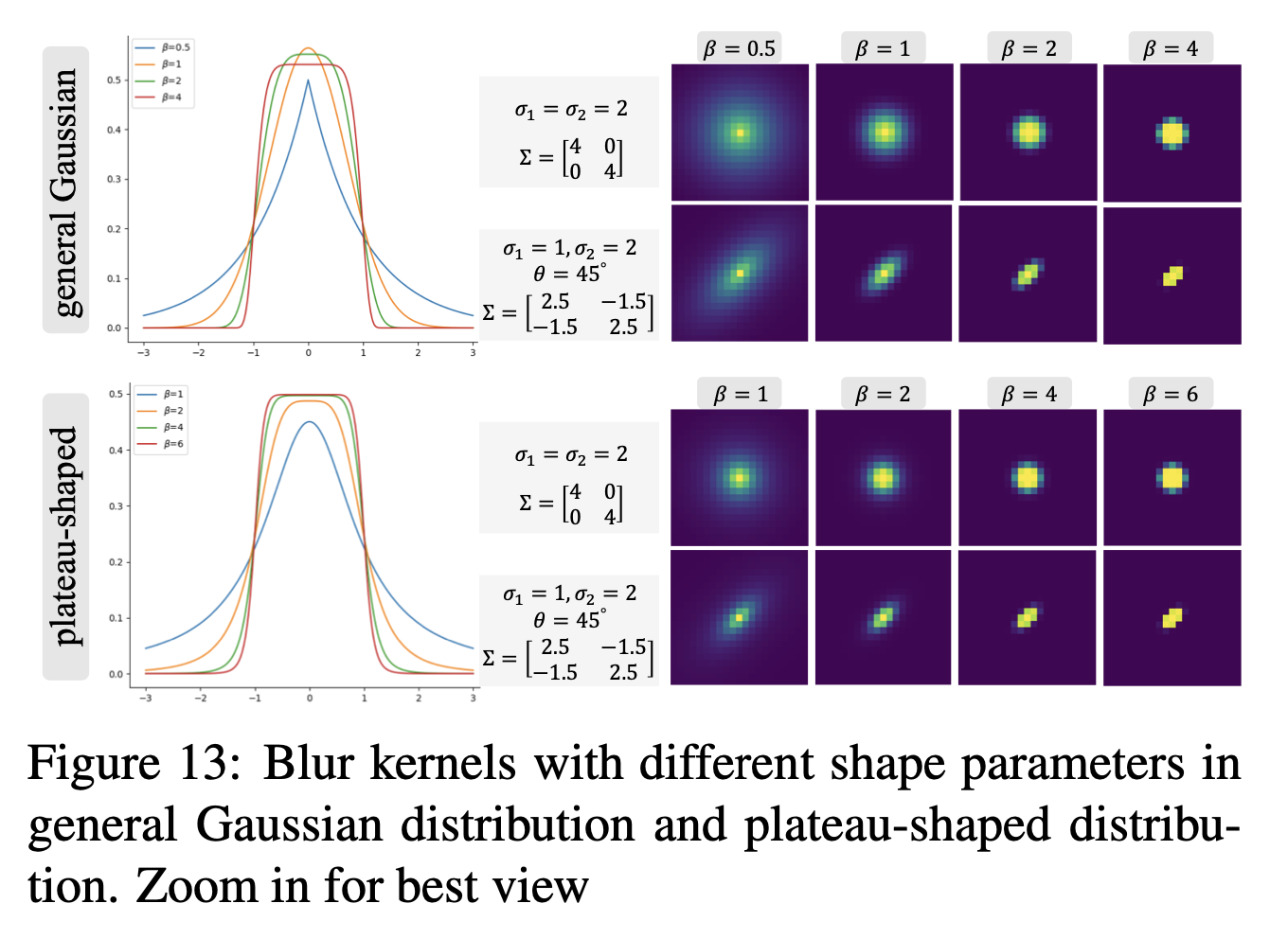
补充:广义高斯模糊(Generalized Gaussian Blur)相比于传统的高斯模糊,引入了一个额外的参数β(beta),这个参数允许调整高斯分布的形状,从而影响模糊核的形状和扩散方式。当β = 1时,广义高斯分布退化为标准高斯分布。 β参数的不同取值可以模拟不同的模糊效果,例如更尖锐或更平坦的边缘,从而提供更灵活的模糊效果控制。
6.2 噪声
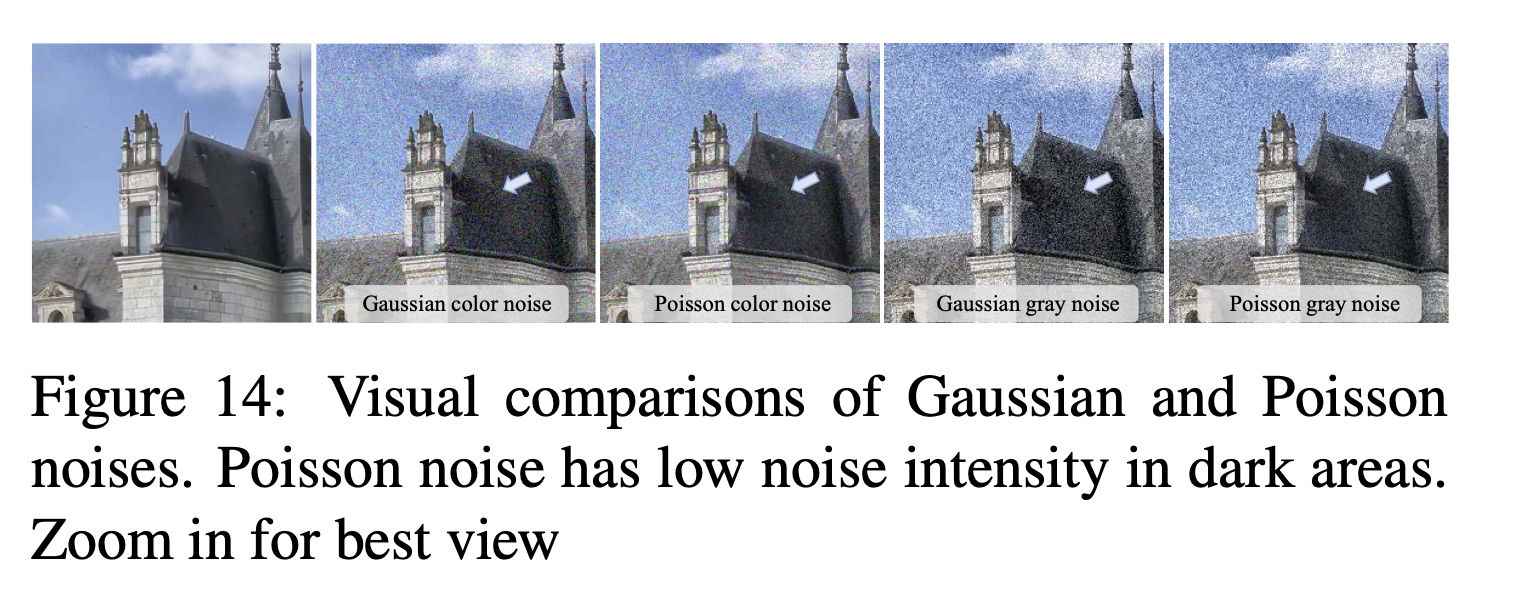
下图展示了高斯噪声和泊松噪声。泊松噪声的强度与图像强度成正比,且不同像素点的噪声是相互独立的。如下图所示,泊松噪声在暗区的噪声强度较低。
6.3 resize
文中描述了几种不同的图像尺寸调整算法,并比较了以下缩放操作:最近邻插值、区域缩放、双线性插值和双三次插值。文中检验了这些缩放操作的不同效果。首先将图像按四倍的比例进行下采样,然后再上采样至原始尺寸。执行了不同的下采样和上采样算法,并将不同组合的结果展示下图中。观察到不同的缩放操作会产生非常不同的效果——有些会产生模糊的结果,而有些可能会输出带有过冲伪影的过度锐化图像。 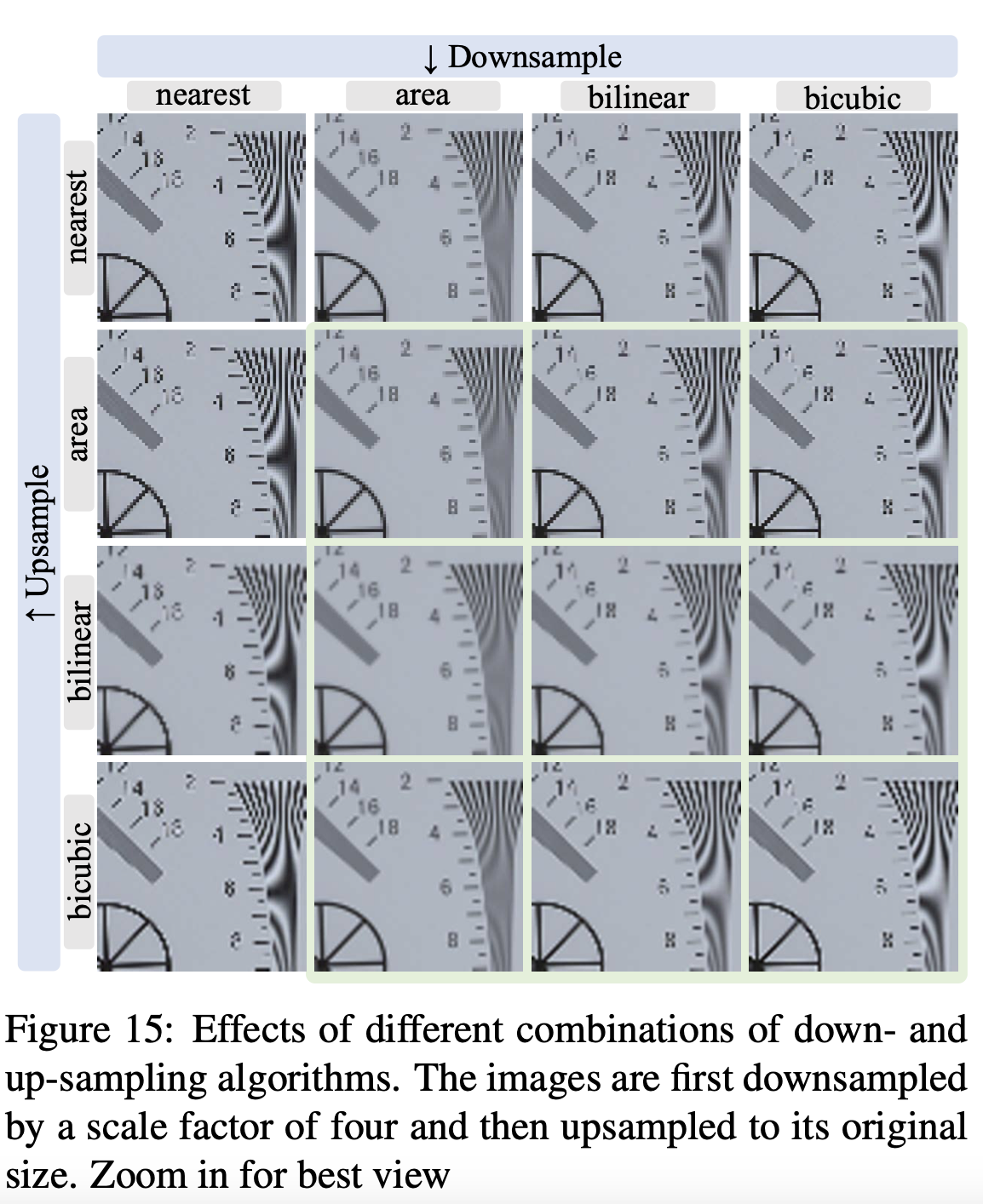
6.4 JPEG压缩
作者使用了PyTorch实现的DiffJPEG。作者观察到,通过DiffJPEG压缩的图像与通过cv2包压缩的图像略有不同。下图展示了典型的JPEG压缩伪影以及使用不同包所造成差异。这样的差异可能会在合成样本和真实样本之间带来额外的间隔。在这项工作中,为了简单起见,只采用了DiffJPEG。

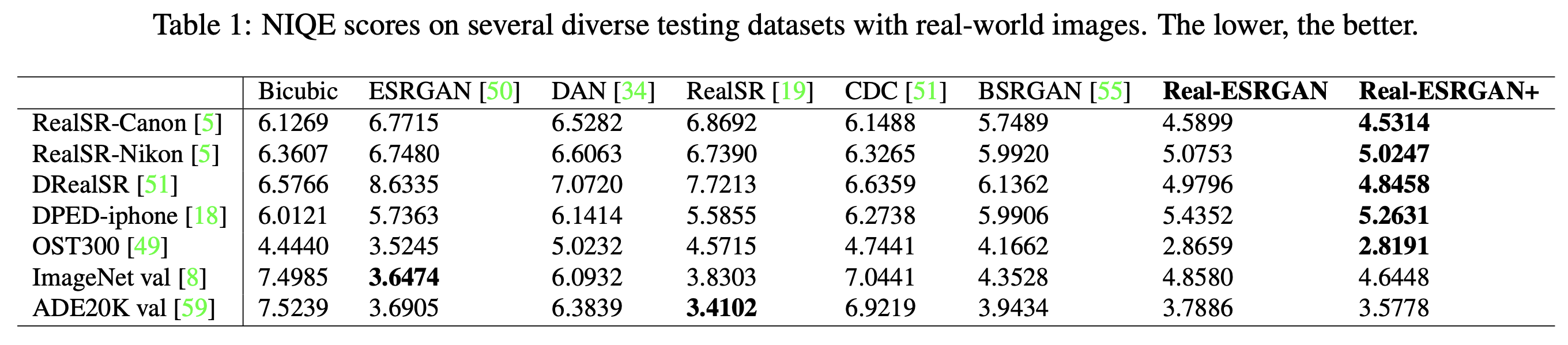
定量的对比
作者提供了非参考图像质量评估——NIQE作为参考。需要注意的是,现有的感知质量指标不能很好地反映在细粒度尺度上实际人类感知偏好。
作者将Real-ESRGAN与几种最先进的方法进行了比较,包括ESRGAN、DAN、CDC、RealSR和BSRGAN。在几个不同的测试数据集上进行了测试,这些数据集包含真实世界图像,包括RealSR、DRealSR、OST300、DPED、ImageNet验证集和ADE20K验证集。结果如下所示。尽管Real-ESRGAN+没有针对NIQE得分进行优化,但在大多数测试数据集上,它仍然产生了较低的NIQE得分。
NIQE(Natural Image Quality Evaluator)是一种无参考图像质量评估指标,它不需要原始高质量图像作为参考,能够直接评估图像的质量。这种指标是基于自然场景统计(Natural Scene Statistics,NSS)构建的,通过学习大量自然图像中提取的特征来评估图像质量 。
NIQE算法的核心包括以下几个步骤:
- 空域NSS特征提取:在图像的空间域中提取特征,如图像的局部均值和标准差。
- 图像块选取:将图像分割成小块,并选择具有一定锐度的图像块进行特征计算。
- 特征化图像块:使用广义高斯分布(Generalized Gaussian Distribution,GGD)对选定的图像块进行建模,提取特征。
- MVG模型:将提取的特征拟合到多元高斯(Multivariate Gaussian,MVG)模型中。
- NIQE指标计算:通过比较测试图像的MVG模型参数与自然图像语料库中提取的MVG模型参数之间的差异来计算NIQE分数。分数越低,表示图像质量越高 。
NIQE算法的优势在于它能够较好地与人类视觉感知保持一致,尤其在图像处理任务如超分辨率、图像去噪等领域,其评价结果通常比传统的指标更符合人的主观感受 。
在实际应用中,NIQE算法可以通过MATLAB实现,其中niqe函数可以直接计算图像的NIQE分数,同时支持使用自定义模型进行评估 。此外,还有开源的NIQE实现,如GitHub上的niqe代码,可供研究和实际应用 。
总的来说,NIQE作为一种无参考图像质量评估方法,因其高效、简便且与人类视觉感知一致的特性,在图像质量评估领域得到了广泛的应用和认可。
更多定性的比较
作者在下图中展示了与以前工作更多的定性比较。Real-ESRGAN在去除伪影和恢复纹理细节方面都优于以前的方法。Real-ESRGAN+(用锐化的GT训练)可以进一步提高视觉锐度。其他方法通常无法去除复杂的伪影(第一个样本)和过冲伪影(第二、三个样本),或者无法为各种场景恢复真实和自然的纹理(第四、五个样本)。




