beam search decoding with CTC
Published:
beam search(束搜索) decoding是一种在语言模型、文本识别等sep2sep的场景中快速、高效的神经网络解码算法。结合前面几个blog,我们重点展开一下beam search在场景文本识别中的作用。
通过前面几个blog的介绍,现在我们已经清楚,常规的场景文本识别算法都是由CNN+RNN+CTC组成的。
经过这三个组合,神经网络的输出是一个包含每个时间步字符概率的矩阵,如下图所示:
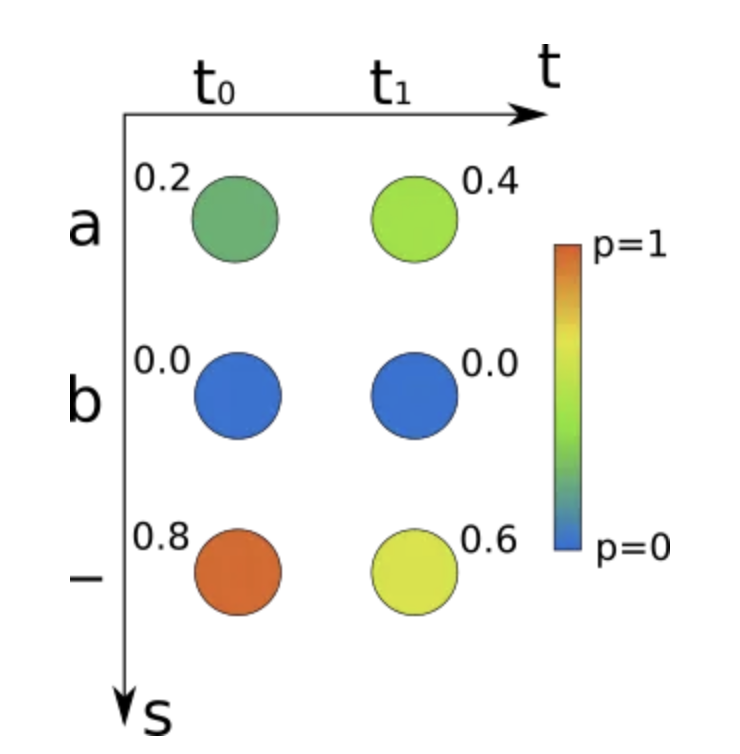
最终识别的文本是通过对这个矩阵的解码得到的。beam search decoding就是一种高效的解码这个矩阵的方法。
CTC允许训练的文本识别系统以(图像,真实文本)的数据对来训练。文本数据是通过神经网络的输出矩阵来描述的,每个时间步包含一个字符,例如上图的’ab’或者’aa’。
解码过程按照一个路径来执行,具体的解码方式是这样的:每一个字符可以被重复多次;任意数量的空白符(用’-‘来表示)可以被插入到字符之间。
下面几个例子展示了一个文本可能的被识别的路径。
“to” -> ‘-t-o—’, ‘ttttttt-ooo-‘, ‘to’, …
“hello” -> ‘h-ellll-ll-ooo’, ‘hel-lo’, …
“a” -> ‘aa’, ‘a-‘, ‘-a’, …
被识别出的文本,在实际的系统中进行处理的时候,实际可能处理的序列有很多种可能。目标是找到最优的路径来得到最终的文本。
为了得到最优的路径,最简单的方法就是贪心算法,每次取概率最大的值。然后把重复的字符和空白符删掉,就是最终识别的文本。
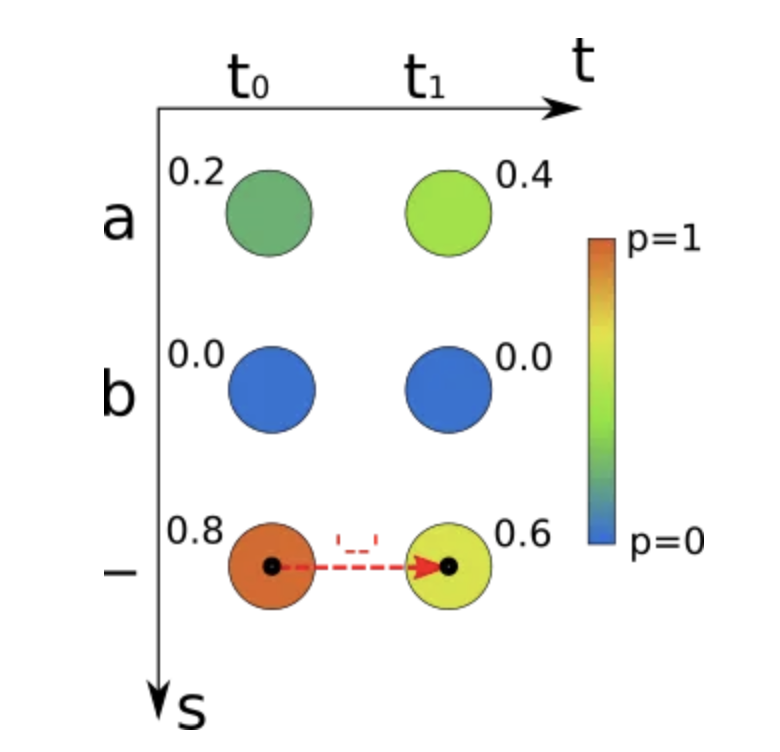
如上图所示,如果使用贪心算法,t0时间步,概率最大的是’-‘,t1时间步是’-‘,所以最终的结果是“”。结果概率是0.8*0.6=0.48。贪心算法的时间复杂度是O(TC),这里T是T个时间步,C是字符的数量。
但是贪心算法在一些场景下是会得出错误的结果,不是最优的路径。
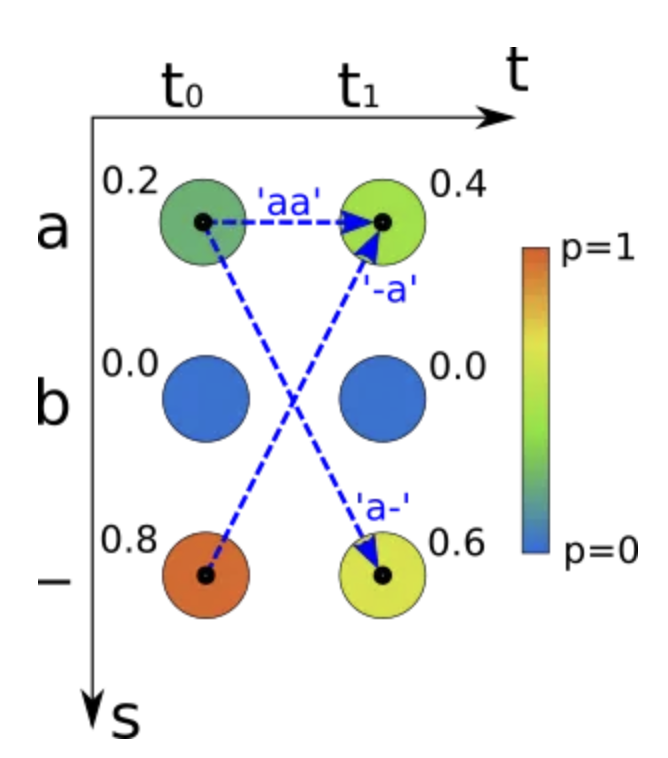
如上图所示,真实的结果应该是”a”。所有能得到字符”a”的路径为:’aa’,’a-‘和’-a’,概率之和为:0.20.4+0.20.6+0.8*0.4=0.52,0.52>0.48,所以得到”a”的概率大于”“的概率。如果用贪心算法,那么最终得到的是”“而不是”a”。
beam search(束搜索)的做法是每轮迭代的选取几个可能的结果作为candidates(beams),然后计算他们的概率。
在李沐的动手学深度学习中,也有对beam search(束搜索)的介绍束搜索。 

一个基础版的beam search算法流程如上图所示。beam search迭代地创建文本候选(beams)并对其进行评分。用empty beam(第1行)和相应的分数(第2行)初始化beams的列表。然后,算法迭代计算神经网络输出的矩阵(line 3-15)的所有时间步长。在每个时间步长,只保留前一个时间步长中得分最好的beam(line 4)被保留。beam width(BW)指定要保留的beams数量。对于每个beam,计算当前时间步长的分数(line 8)。此外,每个beam会使用字母表中的所有可能的字符进行扩展(line 10),然后再次计算分数(line 11)。经过最后一个时间步长后,返回最佳beam(line 16)。
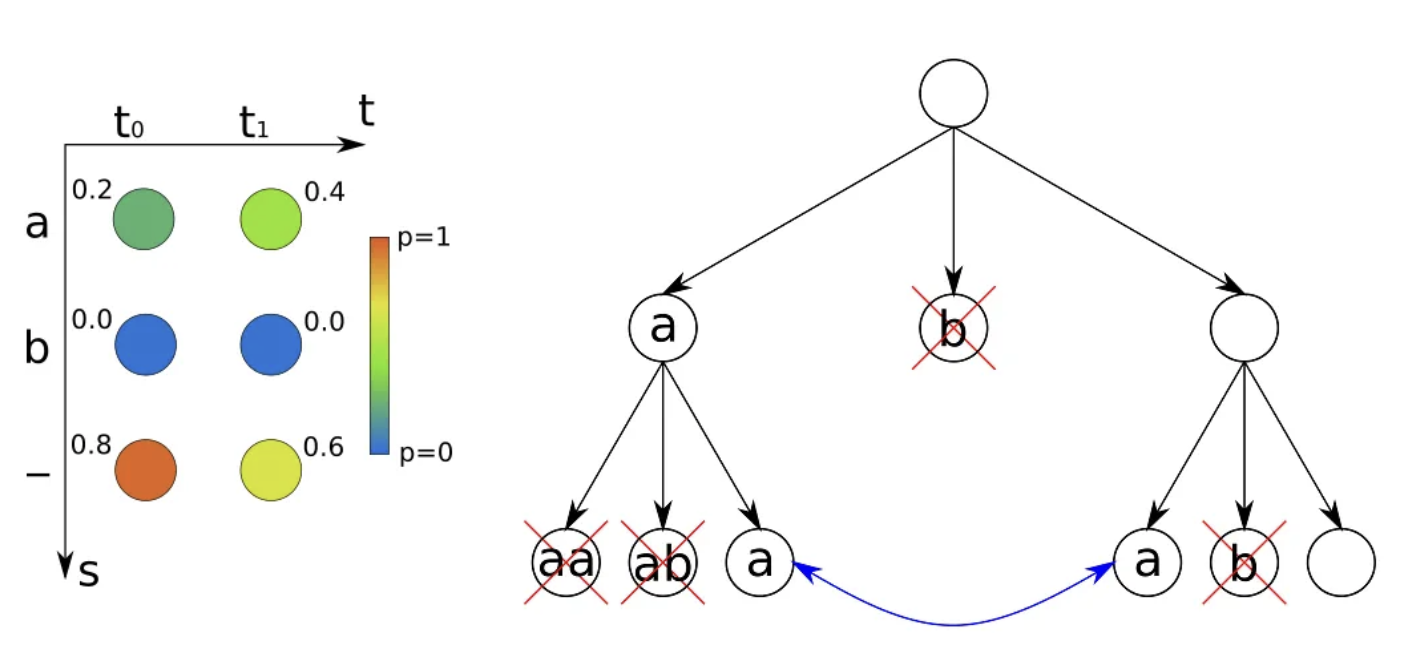
我们根据算法流程来看一下是如何用BW=2和字母表{“a”,“b”}解码前面图示的示例NN输出的。下图显示了待解码的NN输出和beam搜索树。该算法从一个empty beam “”开始,它对应于树的根节点。然后用字母表中所有可能的字符复制和扩展beam。这就给出了“a”,“b”和“”的beam。
从下图左图可以看到,每个光束只有一条路径对应:“a”的概率为0.2,“b”的概率为0,“-”的概率为0.8。
在下一次迭代中,我们只保留前一个时间步长的2个最佳beam(根据BW),即扔掉beam “b”。然后,我们再次复制和扩展被保留的beams,得到“aa”,“ab”,“a”,“a”,“b”,“”。如果两个beam相等,就像“a”的情况一样,我们简单地合并它们:我们把分数加起来,只保留其中一个beam。每个包含“b”的光束的概率为0。“aa”的概率也为0,因为要用重复字符编码文本,我们必须在中间放一个空白(例如“a-a”,这是CTC解码和beam search的规则),这对于长度为2的路径是不可能的。最后,剩下的是beam “a”和“”。我们已经计算出了它们的概率:0.52和0.48。
遍历了所有的时间步,结束迭代,返回最佳的结果”a”。
上面的算法流程,我们只是简单的使用calcScore来表示beam分数的计算,还没有细致的说明这个分数是怎么计算的。
下面讨论一下如何给beams计算分数。我们将beam得分分为以下两种情况:以空白(例如’aa-‘)结尾的路径得分和以非空白(例如’aaa’)结尾的路径得分。我们用Pb(b, t)和Pnb(b, t)分别表示以空白结束并对应于时间步长为t的beam b的所有路径的概率和非空白的情况。因此,beam b在时间步长t处的概率Ptot(b, t)就是Pb和Pnb的和,即Ptot(b, t)=Pb(b, t)+Pnb(b, t)。
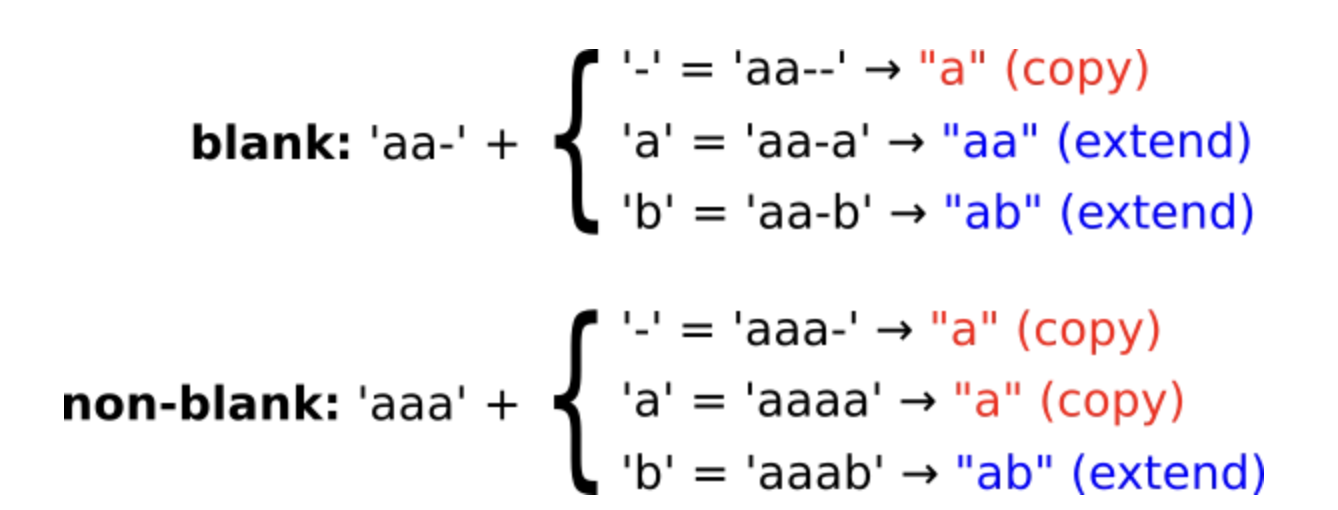
上图显示了当我们扩展一条路径时所发生的情况。主要有三种情况:通过空白进行扩展,通过重复最后一个字符进行扩展,以及通过其他字符进行扩展。当我们折叠扩展路径时,我们要么得到不变的(copy)beam (“a”→“a”),要么得到extend的beam (“a”→“aa”或“ab”)。我们也可以反过来使用这个信息:如果我们扩展beam,我们知道我们必须考虑哪条路径来计算分数。
让我们看看如何迭代地计算Pb和Pnb。所有的Pb和Pnb值最初都设置为0。
copy beam
为了复制beam,我们可以通过一个空白符(‘-‘)来扩展相应的路径,得到以空白结尾的路径:Pb(b, t)+= Ptot(b, t-1)·mat(blank, t)。
此外,我们可以扩展以非空结尾的路径(如果beam是非空的): Pnb(b, t)+=Pnb(b, t-1)·mat(b[-1], t),其中-1表示beam中的最后一个字符。
Extend beam
有两种情况。要么我们将beam使用与最后一个字符不同的字符c来扩展,那么就不需要在路径中分隔空白:Pnb(b+c, t)+=Ptot(b, t-1)·mat(c, t)。
或者最后一个字符b[-1]重复,那么我们必须确保路径以空白结束:Pnb(b+c, t)+=Pb(b, t-1)·mat(c, t)。 我们不需要关心Pb(b+c, t)因为我们添加了一个非空白字符。

上图是集成了CTC和beam search的算法过程,其中LM是指language model。

我们把集成了CTC的算法和之前说的基础版的beam search放在一起对比看。集成了CTC的和基础版的beam search差不多,但包括了对beam进行评分的代码:copy beam(第7-10行)和extend beam(15-19行)进行评分。此外,当将beam b扩展一个字符c(第14行)时,应用到了LM算法。对于单字符的beam,我们应用单字得分(unigram score)P(c),而对于较长的beam,我们应用双字得分(bigram score)P(b[-1],c)。beam b的LM分数被放入变量Ptxt(b)中。当算法寻找最佳得分beam时,它根据Ptot·Ptxt(第4行)对它们进行排序,然后根据BW取最佳的beam。
运行时间可以从伪代码中得到:最外层的循环有T次迭代。每次迭代对N个beam进行排序,排序时间为N·log(N)。选择最佳波束,每个波束用C字符进行扩展。因此,我们有N=BW·C梁,总体运行时间为O(T·BW·C·log(BW·C))。
最外层循环:在Beam Search算法中,最外层循环负责遍历所有时间步(T),每个时间步对应输入序列中的一个时间点。
每步迭代:在每个时间步,算法会对当前的候选序列(beams)进行处理。这些候选序列的数量由变量N表示。
排序操作:在每步迭代中,需要对N个候选序列根据其得分进行排序,以便选择概率最高的序列。排序操作的时间复杂度通常是O(N·log(N))。
选择最佳beam:排序后,算法会选择概率最高的BW个beam作为“最佳beam”,BW是beam宽度参数。
扩展操作:每个最佳beam都会被扩展C次。C是输出序列的字符集大小,包括空白符号(如果使用CTC)。
扩展后的beam数量:扩展后,每个最佳beam会产生C个新的候选序列,因此总共会有N = BW·C个新的候选序列。
时间复杂度:综合考虑上述步骤,Beam Search算法的总时间复杂度是O(T·BW·C·log(BW·C))。这意味着算法的运行时间与以下因素有关:
- T:时间步的数量。
- BW:beam宽度,即每步选择的最佳候选序列数量。
- C:字符集大小,包括空白符号。
- log(BW·C):每步迭代中排序N个候选序列所需的时间。
这个时间复杂度说明了Beam Search算法的效率如何随着输入序列的长度、beam宽度和字符集大小的变化而变化。在实际应用中,通过调整BW和C的值,可以在准确性和计算效率之间取得平衡。
CTCDecoder.beam_search 这个仓库是对beam search的一个python实现。

上图是我们对不同搜索算法的一个评估。在IAM数据集上解码NN,贪心搜索的字符错误率为5.60%,beam search的字符错误率为5.35%。每个样本的运行时间从12ms增加到56ms。
从上图的结果看,beam search和LM一起用,结果是最好的。
References:
https://towardsdatascience.com/beam-search-decoding-in-ctc-trained-neural-networks-5a889a3d85a7