论文解析——What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis
Published:
论文paper地址:What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis
近年来出现了许多新的场景文本识别(STR)模型。虽然每个人都声称已经推动了技术的边界,但由于训练和评估数据集的选择不一致,该领域在很大程度上缺乏全面和公平的比较。本文通过三个主要贡献来解决这个难题。首先,我们检查了训练和评估数据集的不一致性,以及不一致性导致的性能差距。其次,我们引入了一个统一的四阶段STR框架,大多数现有的STR模型都适合这个框架。使用这个框架可以对以前提出的STR模块进行广泛的评估,并发现以前未探索的模块组合。第三,我们在一组一致的训练和评估数据集下,从准确性、速度和内存需求方面分析了模块对性能的贡献。这样的分析消除了当前比较对了解现有模块性能增益的阻碍。
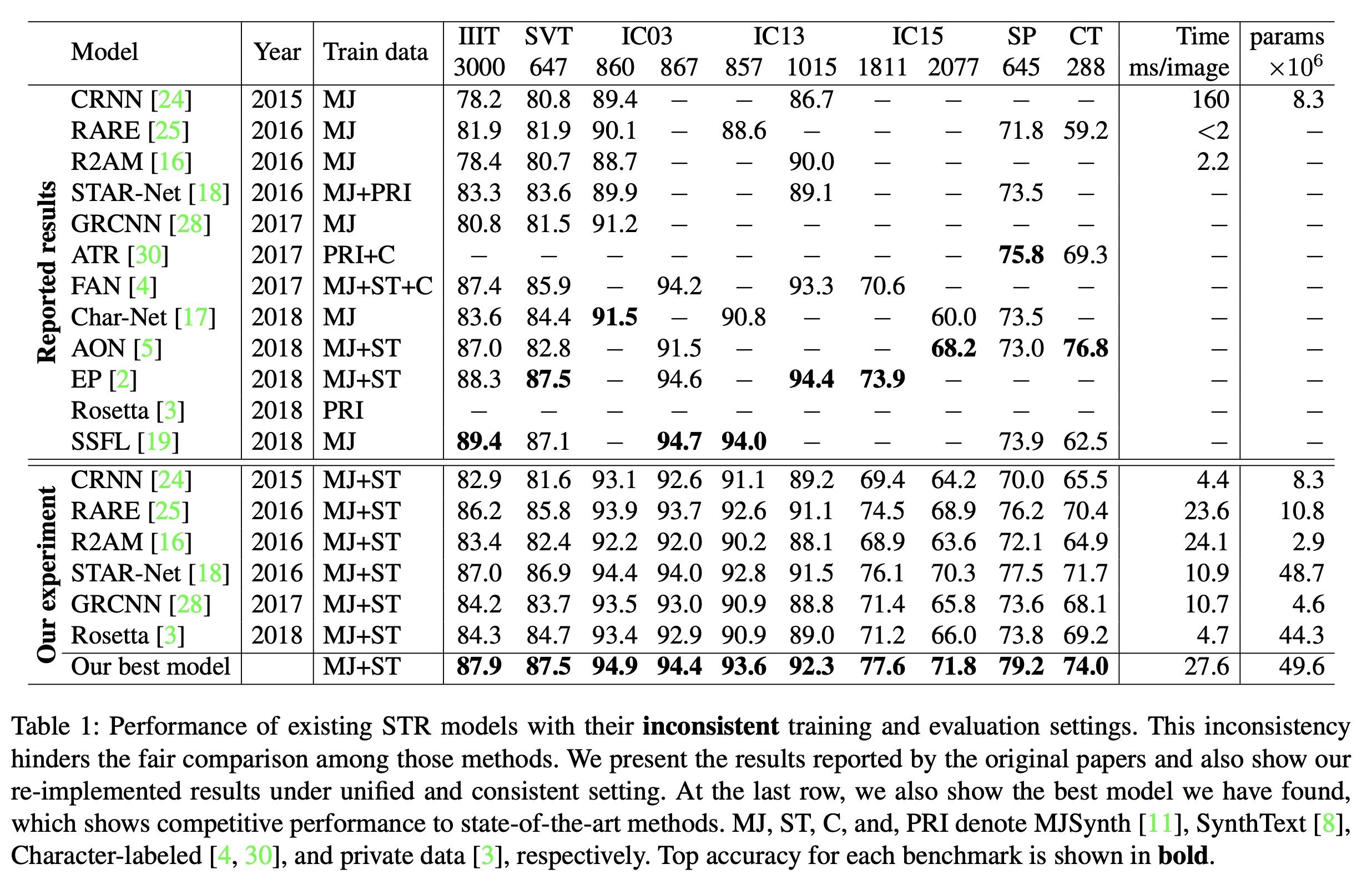
本论文首先分析了STR论文中常用的所有训练和评估数据集。论文的分析揭示了使用STR数据集的不一致性及其原因。例如,作者在IC03数据集中发现了7个缺失样例,在IC13数据集中也发现了158个缺失样例。作者调查了之前的几个关于STR数据集的工作,并表明不一致性导致不可比较的结果,如下表所示。
其次,作者为STR引入了一个统一的框架(我觉着这是本篇论文最大的贡献),为现有方法提供了一个共同的视角。具体来说,作者将STR模型分为四个不同的连续操作阶段:转换(Trans.)、特征提取(Feat.)、序列建模(Seq.)和预测(Pred.)。框架不仅提供了现有的方法,还提供了它们可能的变体,以便对模块的贡献进行广泛的分析。
最后,作者在统一的实验设置下,研究了模块在准确性、速度和内存需求方面的贡献。通过这项研究,更严格地评估了各个模块的贡献,并提出了以前被忽视的模块组合,以改进当前的技术水平。此外,作者分析了基准数据集上的失败案例,以确定STR中仍然存在的挑战。
下面作者介绍了两个在训练STR(Scene Text Recognition)时较常使用的合成数据集(如下图所示):
(1)MJSynth (MJ):是为STR设计的合成数据集,包含890万张字框图像。字框生成过程如下: 1)字体渲染,2)边框和阴影渲染,3)背景着色,4)字体、边框和背景的合成,5)应用投影失真,6)与真实世界的图像混合,7)添加噪声。
(2)SynthText (ST):是另一个合成生成的数据集,最初是为场景文本检测而设计的。尽管SynthText是为场景文本检测任务而设计的,但是通过裁剪单词框,它也被用于STR。SynthText有5.5 M训练数据。

同时作者还将多种数据集分为regular和irregular的数据集。如下图所示:

其中,regular数据集包含具有水平布局字符的文本图像,这些字符之间具有均匀的间距。这些是相对简单的STR情况:
IIIT5K-Words(IIIT):是从Google图像搜索中抓取的数据集,如“广告牌”、“招牌”、“门牌号”、“房屋铭牌”和“电影海报”。IIIT由2000张用于训练的图像和3000张用于评估的图像组成。
街景文本(Street View Text, SVT):包含从Google街景中收集的户外街道图像。其中一些图像有噪声、模糊或分辨率低。SVT由257张用于训练的图像和647张用于评价的图像组成。
ICDAR2003 (IC03):是为ICDAR2003 Robust Reading比赛创建的,用于读取相机捕获的场景文本。它包含1156个用于训练的图像和1110个用于评估的图像。忽略所有太短(少于3个字符)或包含非字母数字字符的单词将1110张图像减少到867张。然而,研究人员使用了两种不同版本的数据集进行评估:860张和867张图像的版本。与867数据集相比,860图像数据集缺少7个词框。
ICDAR2013 (IC13):继承了IC03的大部分思想,也是为ICDAR2013 Robust Reading竞赛而创建的。它包含848张用于训练的图像和1095张用于评估的图像,其中剔除带有非字母数字字符的单词会得到1015张图像。研究人员再次使用了两个不同的版本进行评估:857和1015张图片。857图像集是1015图像集的一个子集,其中短于3个字符的单词被修剪。
irregular数据集通常包含STR的更复杂的情况,例如弯曲和任意旋转或扭曲的文本。
ICDAR2015 (IC15):是为ICDAR2015 Robust Reading竞赛创建的,包含4468张用于训练的图像和2077张用于评估的图像。这些图像是在佩戴者自然运动的情况下由谷歌眼镜捕捉的。因此,许多是嘈杂的,模糊的,旋转的,有些也是低分辨率的。研究人员再次使用了两个不同的版本进行评估:1811张和2077张。以前的论文只使用了1,811张图像,丢弃了非字母数字字符图像和一些极度旋转、视角移位和弯曲的图像进行评估。
SVT Perspective (SP):收集自Google Street View,包含645张用于评估的图像。由于非正面视角的流行,许多图像包含透视投影。
CUTE80 (CT):采集自自然场景,包含288张裁剪后的图像用于评价。其中许多是弯曲的文本图像。
下面是本文最重要的工作,提出了一个STR的通用的framework,把STR分解成4个stage。如下图所示:
- Transformation(Trans.):使用Spatial Transformer Network(STN)对输入文本图像进行规范化,以简化下游阶段。
- Feature extraction(Feat.):将输入图像映射到一个表示,该表示侧重于与字符识别相关的属性,同时抑制不相关的特征,如字体、颜色、大小和背景。
- Sequence modeling(Seq.):捕获字符序列中的上下文信息,以便下一阶段更稳健地预测每个字符,而不是独立地进行预测。
- Prediction(Pred):从图像的识别特征中估计输出字符序列。

- Transformation阶段
这一阶段的模块将输入图像X变换成归一化后的图像X~。自然场景中的文本图像形状各异,如弯曲文本和倾斜文本。如果这样的输入图像是不变的,那么随后的特征提取阶段需要学习关于这种几何形状的不变表示。为了减少这种负荷,thin-plate spline transformation(TPS)作为spatial transformation network(STN)的一种变体,以其灵活性应用于文本行不同宽高比。TPS在一组基点之间采用光滑样条插值。更准确地说,TPS在上下包络点处找到多个基点(图3中的绿色“+”标记),并将字符区域归一化为预定义的矩形。我们的框架允许选择或取消TPS。
- Feature extraction阶段
在这个阶段,CNN将输入图像转换为特征图表示。 作者研究了VGG、RCNN和ResNet三种架构,它们之前被用作STR的特征提取器。VGG的原始形式由多个卷积层组成,然后是几个完全连接的层。RCNN是CNN的一种变体,可以根据字符形状递归地调整其接受域。ResNet是一种带有残差连接的CNN,它简化了相对深度CNN的训练。
- Sequence modeling阶段
从2阶段提取的特征图,会被切分成很多块的特征序列。这些序列可能会受到缺乏上下文信息的影响。因此,之前的一些研究使用双向LSTM (Bidirectional LSTM, BiLSTM)在特征提取阶段后得到更好的序列H = Seq.(V)。另一方面,有些研究删除了BiLSTM以降低计算复杂度和内存消耗。我们的框架允许选择或取消选择BiLSTM。
- Prediction阶段
这个阶段是将上一阶段生成的预测序列,转换为最终的输出文字序列。总结前人的工作,有两种预测方法:(1)Connectionist temporal classification(CTC)和(2)基于注意力的序列预测(attention-based sequence prediction, Attn)。CTC的关键方法是在每列上预测一个字符,并通过删除重复字符和空白将完整字符序列修改为非固定的字符流。另一方面,Attn自动捕获输入序列内的信息流来预测输出序列。它使STR模型能够学习表示输出类依赖关系的字符级语言模型。
总体来看这篇paper提出的STR的架构的工作流,和CRNN提出的模型差不多。
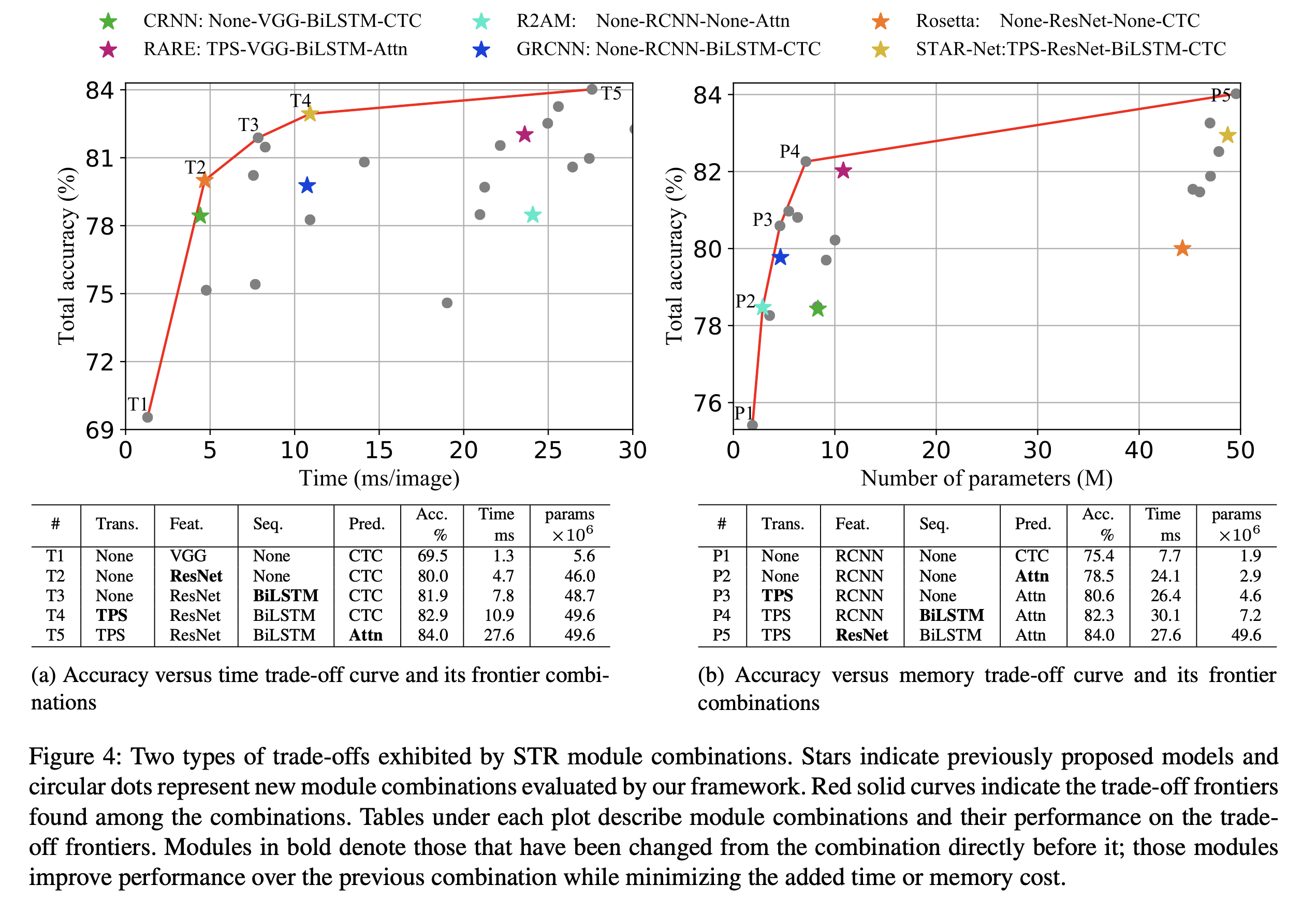
上面结果展示的是作者使用他们提出的4阶段框架,每个阶段通过结合不同的模块,来展示最终的识别率和性能。
用星标展示的是之前已有的研究使用的不同组合,圆圈表示的展示的是他们的4阶段的框架设计的新的结构。
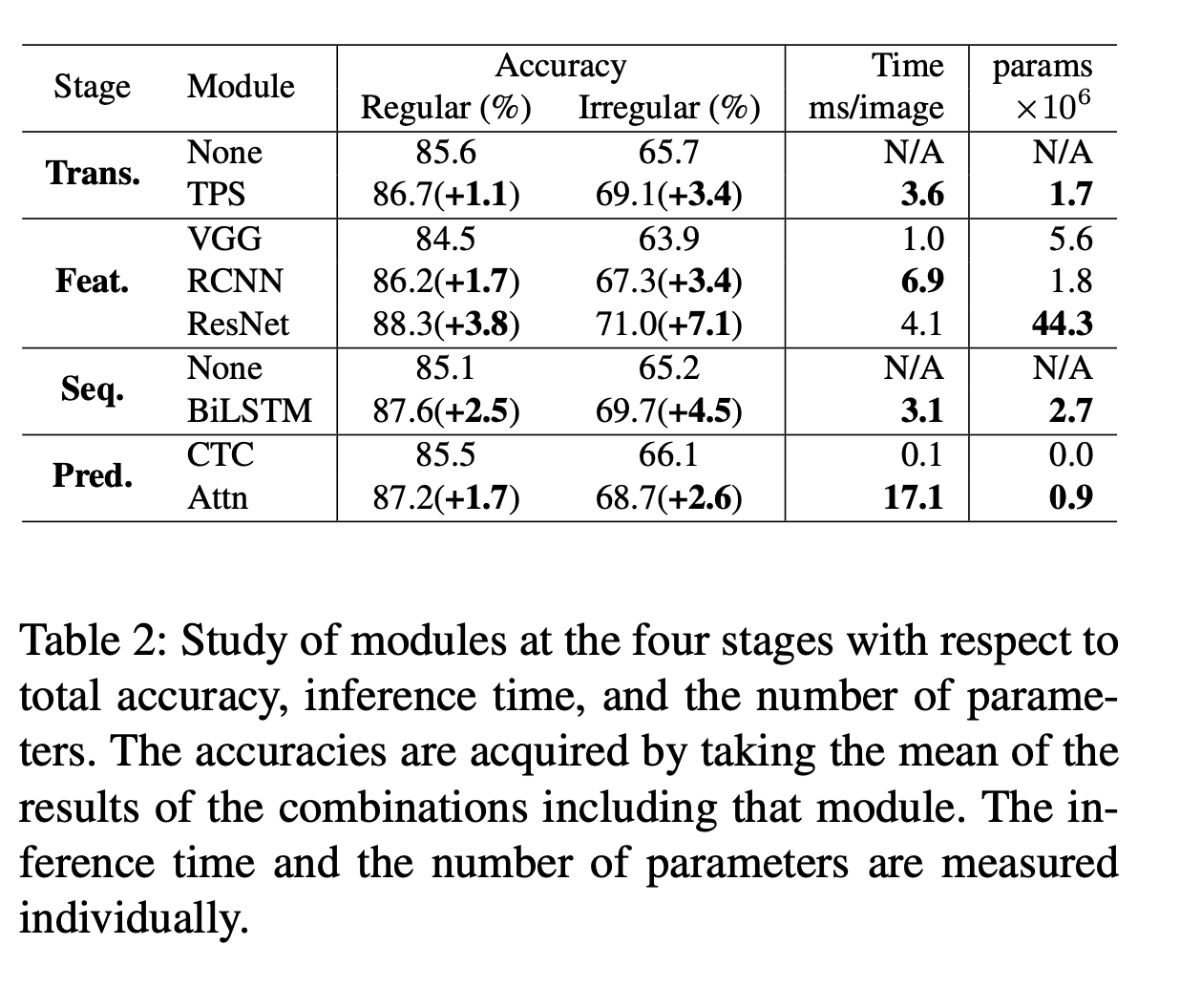
上面表格展示的是每阶段不同的模块对效果和性能的影响。