使用ncnn在树莓派4B上部署nanoDet-m网络(12fps)
Published:
1. 背景
在机器人的应用中,目标检测是一个重要的课题。深度学习的快速发展,在检测的效果方面对比大多数传统检测算法,都有明显的优势。但是将深度学习模型部署到端侧设备上,实现高效的推理,同样是一个问题很多的领域。
在机器人的主控中,树莓派和Jetson系列单板机被使用较多。这篇blog以树莓派4b为例,展示将深度学习模型部署到低算力平台的方法。
与深度学习在GPU上的推理不同,为了实现高效推理,一般都会选择使用推理框架,而不是直接使用python的推理代码进行推理。在CPU侧,常用的推理框架有ncnn、mnn、openvino等;在GPU侧,有tensorrt;高通在htp上,同样有snpe和qnn等推理框架。本blog使用树莓派的CPU进行推理,使用ncnn作为推理框架。
2. 效果
下图所示是在树莓派4b上推理nanoDet-m网络的结果。
图中的两个场景,在被检测目标较为密集的场合,检测算法也能达到11fps,且识别率很高。


除了网络的树莓派端侧推理结果之外,我还统计了一些在推理时,树莓派的相关信息。
将树莓派超频后,推理1分钟多的视频,平均fps可达11.4,最高可达12fps。且温度在合理的范围内。超频后,功耗比不超频状态下多了2.1w左右。
| 工作状态 | CPU频率(Hz) | CPU温度(℃) | GPU频率(Hz) | GPU温度(℃) | 功耗 | 内存占用(with desktop) | 平均fps |
|---|---|---|---|---|---|---|---|
| 无作业 | 600M | 34 | 200M | 33.6 | 3.135w | 318M | 无 |
| 推理nanoDet-m | 1.5G | 43 | 500M | 42 | 5.357w | 494M | 10.3fps |
| 推理nanoDet-m(超频) | 2.0G | 51.2 | 700M | 52.6 | 7.446w | 446M | 11.4fps |
下图是我使用的功耗测试仪 
3.nanoDet-m网络
如下图所示是这次要部署的网络,下图仅截取了部分backbone和部分heads网络。 

下表是以YOLOv4 tiny作为对比对象的数据。nanoDet-m实现了在较低的FLOPs和params的情况下,得到了不错的mAP值,是一个非常适合端侧低算力设备推理的网络结构。
| Model | backbone | resolution | COCO mAP | FLOPs | params |
|---|---|---|---|---|---|
| NanoDet-m | ShuffleNetV2 1.0x | 320*320 | 20.6 | 0.72G | 0.95M |
| YOLOv4 tiny | CSPDarknet53 | 416x416 | 21.7 | 6.5B | 3.1M |
4. 我的树莓派信息
硬件: 树莓派4b、2G RAM、32G ROM、荣耀平板8充电头供电、全套散热装,如下图 
软件:raspberry OS、上游分支Debian GNU/Linux 11 (bullseye)。
5. ncnn推理相关软件安装
下面介绍在树莓派4b端侧推理nanoDet-m网络,需要安装的组件以及安装方法。
5.1 安装ncnn
执行uname -a,确保是aarch64架构的系统。
执行如下安装指令
# check for updates
sudo apt-get update
sudo apt-get upgrade
# install dependencies
sudo apt-get install cmake wget
sudo apt-get install build-essential gcc g++
sudo apt-get install libprotobuf-dev protobuf-compiler
# download ncnn
git clone --depth=1 https://github.com/Tencent/ncnn.git
# install ncnn
cd ncnn
mkdir build
cd build
# build 64-bit ncnn
cmake -D NCNN_DISABLE_RTTI=OFF -D NCNN_BUILD_TOOLS=ON \
-D CMAKE_TOOLCHAIN_FILE=../toolchains/aarch64-linux-gnu.toolchain.cmake ..
make -j4
make install
# copy output to dirs
sudo mkdir /usr/local/lib/ncnn
sudo cp -r install/include/ncnn /usr/local/include/ncnn
sudo cp -r install/lib/libncnn.a /usr/local/lib/ncnn/libncnn.a
在~/ncnn/build/install/bin文件夹下,有很多转换模型的工具,这在我们后面的博客中会用得到,将onnx模型转换为ncnn支持的模型。
5.2 安装opencv4.5.5
(1)更新EEPROM 树莓派4b支持更新EEPROM中的固件,可有效降低树莓派的运行温度。
sudo rpi-eeprom-update
sudo rpi-eeprom-update -a
sudo reboot
(2) 源码编译安装opencv
不要使用pip或者apt安装opencv,这两种方式不能保证是64bit版本的,性能不能充分在树莓派上发挥出来。
在Preferences -> Raspberry Pi Configuration -> Performance -> GPU Memory设置项中,给GPU分配至少128M显存。
执行以下命令安装
# check for updates
sudo apt-get update
sudo apt-get upgrade
# dependencies
sudo apt-get install build-essential cmake git unzip pkg-config
sudo apt-get install libjpeg-dev libpng-dev
sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install libgtk2.0-dev libcanberra-gtk* libgtk-3-dev
sudo apt-get install libgstreamer1.0-dev gstreamer1.0-gtk3
sudo apt-get install libgstreamer-plugins-base1.0-dev gstreamer1.0-gl
sudo apt-get install libxvidcore-dev libx264-dev
sudo apt-get install python3-dev python3-numpy python3-pip
sudo apt-get install libtbb2 libtbb-dev libdc1394-22-dev
sudo apt-get install libv4l-dev v4l-utils
sudo apt-get install libopenblas-dev libatlas-base-dev libblas-dev
sudo apt-get install liblapack-dev gfortran libhdf5-dev
sudo apt-get install libprotobuf-dev libgoogle-glog-dev libgflags-dev
sudo apt-get install protobuf-compiler
下载opencv4.5.5的源码包
cd ~
# 如果网络连接失败,在其他电脑上访问这个网址下载好,再放到树莓派的 ~/ 目录下
wget -O opencv.zip https://github.com/opencv/opencv/archive/4.5.5.zip
wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.5.5.zip
unzip opencv.zip
unzip opencv_contrib.zip
mv opencv-4.5.5 opencv
mv opencv_contrib-4.5.5 opencv_contrib
在执行编译之前,如果是2G RAM的树莓派,需要扩容swap分区,大于2G RAM的版本可忽略此项。 扩容swap方式(仅限2G RAM)
使用开源代码rpi_zram, 对swap进行扩容,按照github上的README操作就可以。
编译opencv4.5.5
cd ~/opencv
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D ENABLE_NEON=ON \
-D WITH_OPENMP=ON \
-D WITH_OPENCL=OFF \
-D BUILD_TIFF=ON \
-D WITH_FFMPEG=ON \
-D WITH_TBB=ON \
-D BUILD_TBB=ON \
-D WITH_GSTREAMER=ON \
-D BUILD_TESTS=OFF \
-D WITH_EIGEN=OFF \
-D WITH_V4L=ON \
-D WITH_LIBV4L=ON \
-D WITH_VTK=OFF \
-D WITH_QT=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D INSTALL_PYTHON_EXAMPLES=OFF \
-D PYTHON3_PACKAGES_PATH=/usr/lib/python3/dist-packages \
-D OPENCV_GENERATE_PKGCONFIG=ON \
-D BUILD_EXAMPLES=OFF ..
make -j4
sudo make install
sudo ldconfig
验证安装,进入python编程环境
import cv2
print(cv2.__version__)
5.3 安装codeblocks
使用codeblocks在树莓派上进行开发。喜欢remote develop的也可以直接使用vscode的远程开发功能。
6. 推理通路代码
执行git clone https://github.com/borninfreedom/NanoDet-ncnn-Raspberry-Pi-4.git 来获取通路前后处理代码和素材文件。
其中,NanoDet.cbp是codeblocks工程文件,可以直接双击打开一个codeblock工程。
在codeblocks中编译并运行,即可将NanoDet模型部署在树莓派上。
7. 主要代码说明 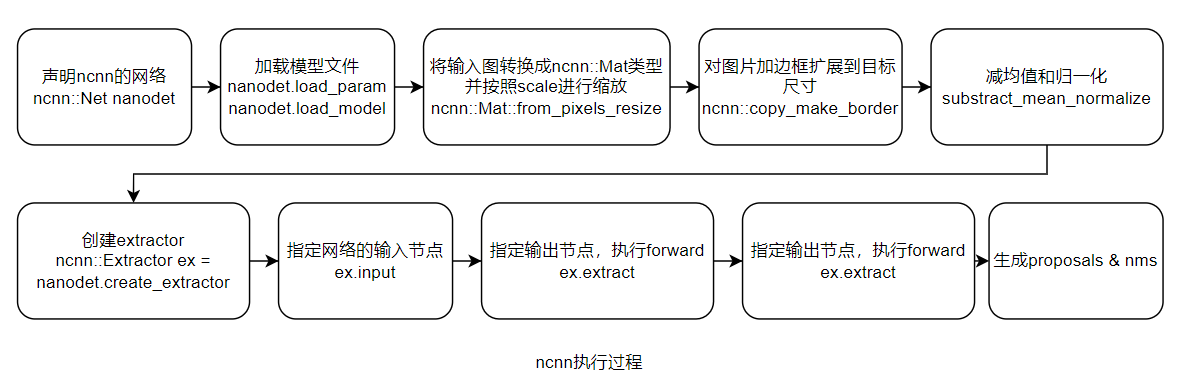
如上图是使用ncnn进行网络部署的过程。下面就以这个主线进行展开来说明代码的主要细节实现。
使用ncnn::Net nanodet,定义ncnn的网络nanodet后,首先需要将模型文件load进来。
nanodet.load_param("nanodet_m.param");
nanodet.load_model("nanodet_m.bin");
在这里,我提供了nanodet_m和nanodet_m-int8两个模型,分别为float和int8量化的模型。每一个模型分为两个文件,.param参数文件和.bin模型文件。.param文件可以直接使用netron软件打开,以查看网络结构。
在代码的main函数中,load进来模型后,下面就要执行检测的主要过程。在detect_nanodet函数中,首先对图片进行resize操作,然后调用ncnn的from_pixels_resize函数,将cv::Mat数据转换到ncnn::Mat同时进行resize操作。
int w = width;
int h = height;
float scale = 1.f;
if (w > h)
{
scale = (float)target_size / w;
w = target_size;
h = h * scale;
}
else
{
scale = (float)target_size / h;
h = target_size;
w = w * scale;
}
// from_pixels_resize将cv::Mat数据转换到ncnn::Mat同时进行resize操作
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR, width, height, w, h);
目前ncnn不支持同时进行图片等比例缩放并且填充到固定长宽,具体可以访问ncnn issues 1260。因此还需要调用copy_make_border函数进行图片的填充。
// pad to target_size rectangle
// 这两个公式的作用是将 w 填充到32的倍数,需要 pad 多少,比如 w = 1,需要 pad 31才能到32, w=63,需要 pad 1到64
int wpad = (w + 31) / 32 * 32 - w;
int hpad = (h + 31) / 32 * 32 - h;
ncnn::Mat in_pad;
// in_pad是目标Mat,函数的作用是在原输入上,进行pad,扩充边界
ncnn::copy_make_border(in, in_pad, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, ncnn::BORDER_CONSTANT, 0.f);
然后对图片减均值和norm操作。
const float mean_vals[3] = {103.53f, 116.28f, 123.675f};
const float norm_vals[3] = {0.017429f, 0.017507f, 0.017125f};
in_pad.substract_mean_normalize(mean_vals, norm_vals);
下面是创建比较重要的extractor。ncnn将网络的结构用blob(用netron打开.param文件,每一个节点可以理解为一个blob)链接构成一个DAG(有向无环图),给定input以及extract之后,ncnn从extract向上查找,找到通往input的路径,让后再顺序路径forward下来。
使用下面的语句创建一个Extractor的实例。
ncnn::Extractor ex = nanodet.create_extractor();
创建了ex之后,就可以指定input和output,让ncnn进行遍历,构建网络的有向无环图。
使用ex.input函数来指定模型的输入节点。输入节点的名字,使用netron打开.param文件,即可看到。
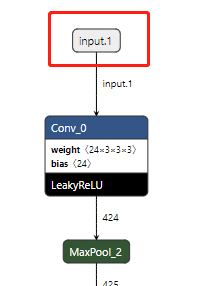
ex.input("input.1", in_pad);
然后调用ex.extract来构建网络并执行forward,这里需要将output节点的名字作为参数传递进去。nanoDet-m网络,在head部分,分别有stride8、stride16、stride32三个部分。
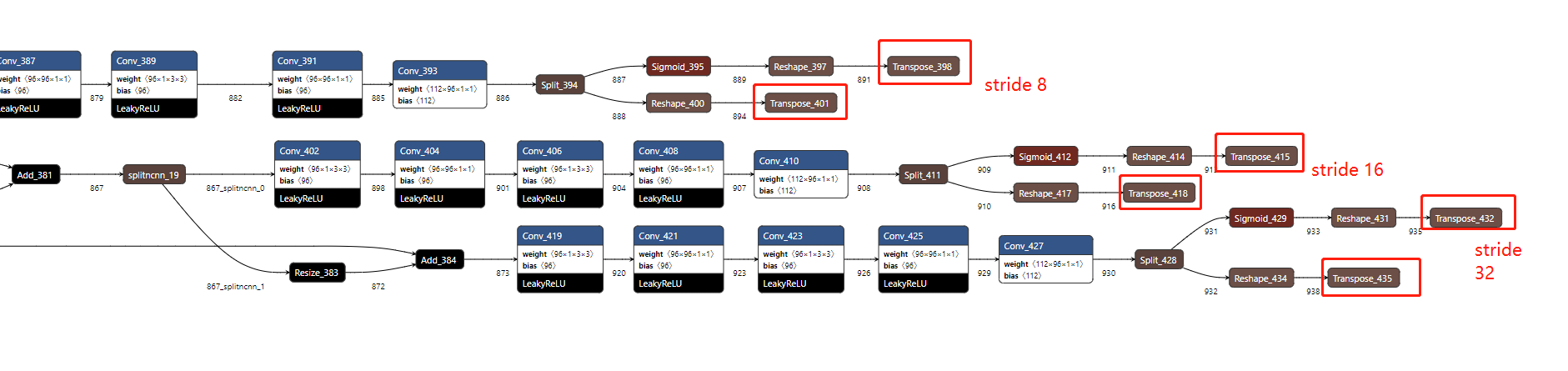
上图所示是nanoDet的head部分,从上到下依次是stride 8、stride 16、stride 32的分支,我们需要将红框框出的输出节点,作为参数传递给ncnn的extract函数。
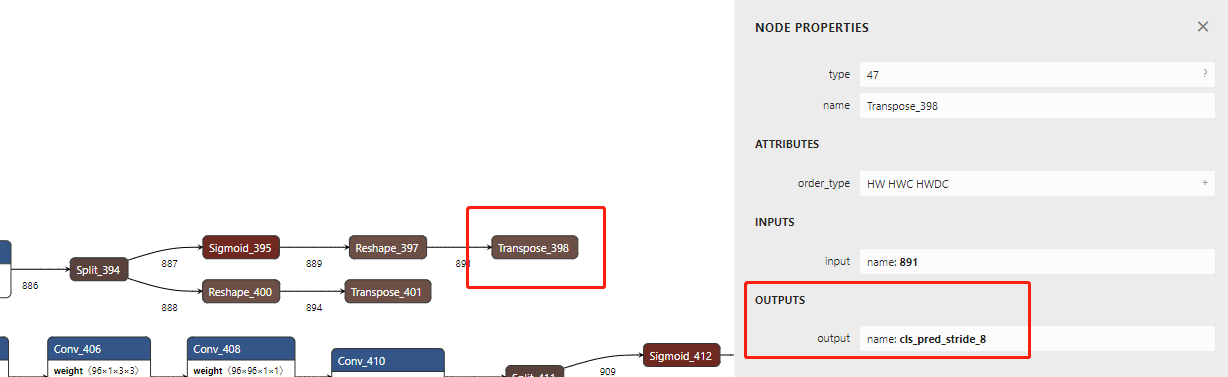
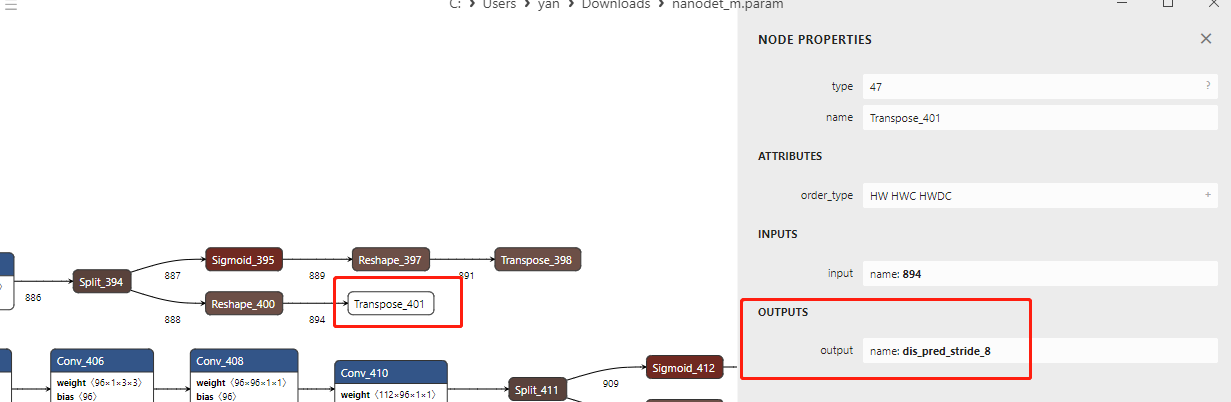
上图所示为stride 8分支,我们以stride 8分支为例。在netron中,我们点击sigmoid_395 -> Reshape_397 -> Transpose_398这个class分支最后的Transpose_398节点,如上图,可以看到这个节点的输出名字为cls_pred_stride_8。同理,点击Reshape_400 -> Transpose_401这个bbox分支的最后的节点Transpose_401节点,可以看到这个节点的输出名字是dis_pred_stride_8。这两个output的名字是我们要作为参数传递给extract函数的。stride 16、stride 32 head分支同理。
下面看一下stride 8分支的代码
// stride 8
{
ncnn::Mat cls_pred;
ncnn::Mat dis_pred;
ex.extract("cls_pred_stride_8", cls_pred);
ex.extract("dis_pred_stride_8", dis_pred);
std::vector<Object> objects8;
generate_proposals(cls_pred, dis_pred, 8, in_pad, prob_threshold, objects8);
proposals.insert(proposals.end(), objects8.begin(), objects8.end());
}
上面的代码,我们将cls_pred_stride_8和dis_pred_stride_8作为参数传递给ex.extract函数。
extract函数同时会执行forward计算,后面调用generate_proposals生成proposals;调用qsort_descent_inplace对proposals进行排序;调用nms_sorted_bboxes执行nms计算即可完成全部的部署过程。最后再执行画图操作即可。
8. 树莓派超频
为了发挥树莓派更高的性能,可以对树莓派进行超频。对于树莓派4b,在超频之前,需要先更新EEPROM (electrically erasable programmable read-only memory)固件。最新固件的作用不是提高了树莓派的主频,而是降低了树莓派的功耗,降低了树莓派的温度。
sudo apt-get update
sudo apt-get full-upgrade
sudo apt-get install rpi-eeprom
# to get the current status
sudo rpi-eeprom-update
# to update the firmware
sudo rpi-eeprom-update -a
sudo reboot
树莓派通过直接修改/boot/config.txt文件即可实现超频。在文件中,主要通过修改over_voltage,arm_freq,gpu_freq三项来实现cpu和gpu的超频。其中over_voltage表示随着cpu频率的增高,相应的cpu的电压要适当提高。
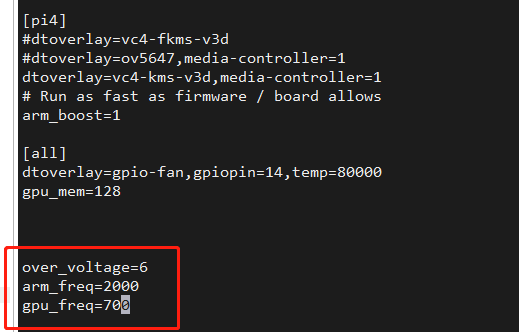
树莓派4b,不同频率,以及对应频率下over_voltage设定的值参见下表。 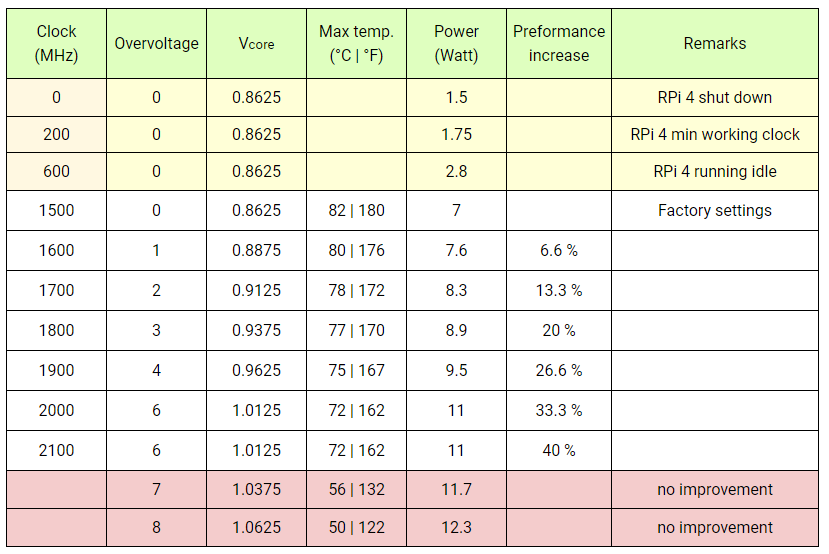
超频后,需要使用更为优秀的散热和电源。下面图片描述了不同频率、不同散热装置下,树莓派随着运行时间的温度走势。 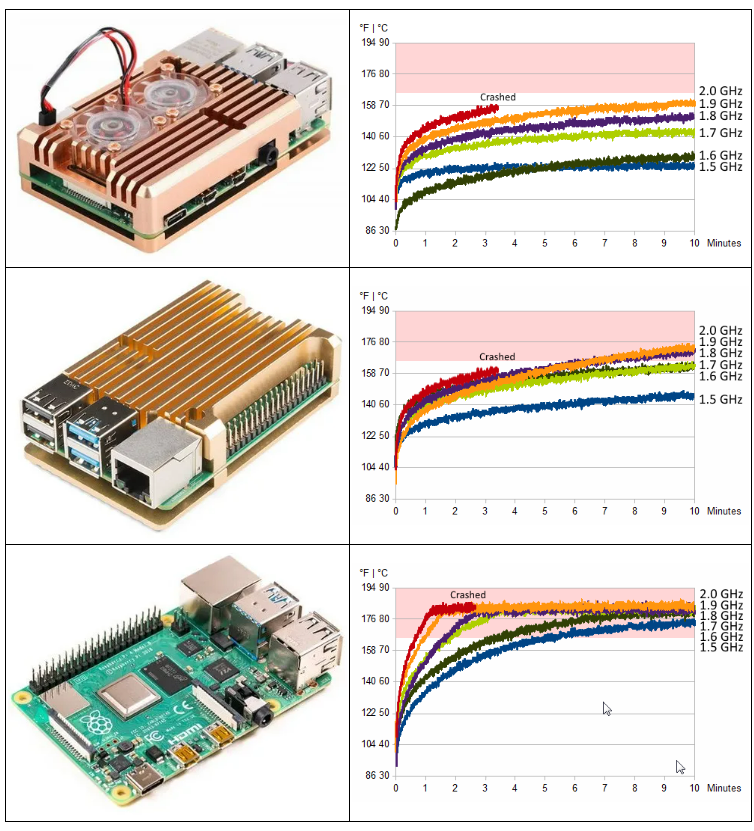
我们可以使用下面的指令来查看超频之后的频率、电压和温度。
# 查看cpu频率
watch -n1 vcgencmd measure_clock arm
# 查看gpu频率
watch -n1 vcgencmd measure_clock core
# 查看电压
watch -n1 vcgencmd measure_volts core
# 查看温度
watch -n1 vcgencmd measure_temp
# 查看所有参数
vcgencmd get_config int
#
9. int8量化模型
我提供的文件中,还有nanodet_m-int8.bin和nanodet_m-int8.param两个文件,这是使用ncnn int8量化的模型,模型的weights和activations(节点的输出,不是激活函数,详见paper A White Paper on Neural Network Quantization)使用int8来存储。量化模型相比float16模型,计算量更小,模型体积更小,推理速度更快,精度略有损失。

从上图nanodet_m.bin和nanodet_m-int8.bin两个文件的大小对比,可以看到int8的模型占用的空间,基本上是float16模型的一半。
在代码中,将load_param和load_model函数的参数改为int8模型的名字。在main函数中修改如下,加载int8量化模型:
nanodet.load_param("nanodet_m-int8.param");
nanodet.load_model("nanodet_m-int8.bin");

从上图看,int8的量化模型,在多人的情况下,依然能够都检出来。但是摩托车没有检测出来。
我也对int8模型的性能和功耗进行了测试。
| 工作状态 | CPU频率(Hz) | CPU温度(℃) | GPU频率(Hz) | GPU温度(℃) | 功耗 | 内存占用(with desktop) | 平均fps |
|---|---|---|---|---|---|---|---|
| 推理nanoDet-m-int8(超频) | 2.0G | 56.4 | 700M | 55.5 | 7.53w | 526M | 13.5fps |
然后将之前float16模型的数据一起对比来看,可以看到int8的模型的fps是最高的,平均fps达到了13.5。温度数据,由于天气变化,有波动属于正常。
| 工作状态 | CPU频率(Hz) | CPU温度(℃) | GPU频率(Hz) | GPU温度(℃) | 功耗 | 内存占用(with desktop) | 平均fps |
|---|---|---|---|---|---|---|---|
| 无作业 | 600M | 34 | 200M | 33.6 | 3.135w | 318M | 无 |
| 推理nanoDet-m | 1.5G | 43 | 500M | 42 | 5.357w | 494M | 10.3fps |
| 推理nanoDet-m(超频) | 2.0G | 51.2 | 700M | 52.6 | 7.446w | 446M | 11.4fps |
| 推理nanoDet-m-int8(超频) | 2.0G | 56.4 | 700M | 55.5 | 7.53w | 526M | 13.5fps |